预测编码已经用BackProjagation统一
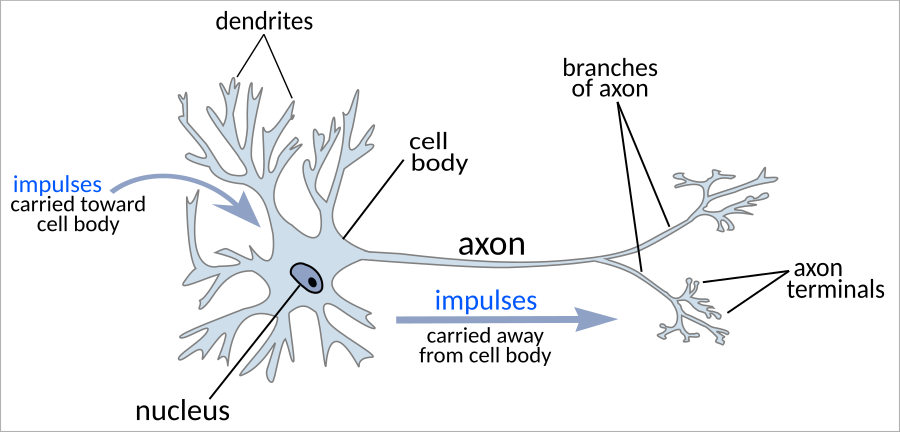
人工神经网络(ANNS)基于BackProjagation算法。 BackProjagation算法允许您在神经元网络上执行梯度下降。当我们通过ANNS提供培训数据时,我们使用BackProjagation算法告诉我们权重应该如何改变。
Anns擅长推理问题。生物神经网络(BNNS)也擅长推动。 Anns是由神经元构成的。 BNN也是由神经元构成的。它使ANNS和BNNS可能正在运行类似的算法,这是直观的。
我们对生物学不太了解,可以说BNN不可能运行BackPropagation算法。然而,"一项共识已经出现,大脑不能直接实施背部,因为这样做就需要生物学难以置信的连接规则" [1]。
BackProjagation算法需要沿网络向前和向后流动的信息。但生物神经元是单方面的。动作电位从轴身向下到轴突到轴线端子到另一个细胞' s树枝状体。轴突势永远不会从电池和#39; S端子向后行驶到其身体。
预测编码是BNN生成其环境的心理模型的想法,然后仅发送偏离该模型的信息。预测编码考虑错误并惊喜是相同的。 Hebbian理论是预测编码的特定数学制定。
预测编码是生物学可言论的。它在本地运营。没有单独的预测和训练阶段必须同步。最重要的是,它可以让您训练神经网络,而不会向后发送Axon电位。
在硬件中更容易实现预测编码。它是本地定义的;它比背部经历更好地顺序化;当您将基板缩小为一半时,它继续运行。 (胼callootomy用于治疗癫痫症。)当你将它们切成两半时,数字电脑打破。预测编码是一种易于发明的东西。
纸张预测编码沿任意计算图[1:1]&#34沿着任意计算图近似于倒波;演示预测编码会收敛于使用本地学习规则的任意计算图中的渐近渐变(并且在实践中迅速地)。&# 34;作者对一个神经网络的单一理论进行了统一的预测编码和反向化。预测编码和BackProjagation是最终相同算法的单独硬件实现。
如果它们将ηv到1设置为它们,则在单个后向通行证1中会聚,因为它们然后计算精确反击。将ηv设置为小于那个,也许混合通过顺序仅仅会使此过程延迟并延迟此过程,但收敛,因为任何没有错误儿童的神经元都无处可行,而是朝着正确的情况。整个收敛是单一输入!之后,它们可以像往常一样手动对重量进行梯度步骤。
我的意思是,它的整洁,你可以通过相同的更新规则治疗激活和参数,但是你应该实际做到这一点。每个"勾选",替换输入和标签,并让每个神经元更新其参数和数据,其中每个神经元只能看其邻居。当然,如果输入和标签来自连续流,则只有工作的机会,因为如果输入是另一个网络的输出,则会有机会。他们还注意到连续数据的可能性。然后一个人可以看到它的性能如何降低,因为一种速度达到糟糕的大脑和环境:)。
1:必须处于向后顺序和εi←v i - ^ v我必须在v更新行之后再次完成。认知状态:其他人都在振荡所以也许我是愚蠢的?
当然,如果输入和标签来自连续流,则只有工作的机会,因为如果输入是另一个网络的输出,则会有机会。
因此,预测处理非常适合于BNN,因为生物体的实时感官数据,包括被另一网络预处理的感官数据,是连续流。
目前的神经网络似乎需要更多的数据(例如星际争霸游戏),以达到与人类成年人相同的表现。有不同的假设,为什么这是:
- 乌鸦大脑有很多预先培训,他们可以获得良好的习惯和模型,它概括为新的任务/情况(我们称之为"童年"和#34;教育")。 GPT-3等显示了神经网的类似作品,也许我们只需要用更大的大脑做更多的事情。
我听到了各种人严重维护的所有这些假设。如果这是真的,它会排除最后一个。
毫无疑问,人性大脑有很多本能内置的本能。但是有多少信息单一物种和#39;本能可以包含。人类&#39是难以置信的;认知本能含有比人类基因组更大的信息(750兆字节)。我期待我们的本能较少。
人类大脑肯定有特殊的建筑,就像海马一样。关键问题是这些特殊架构的重要性。我们的特殊架构是否对一般情报至关重要,也是他们只是速度的黑客攻击?如果它们是速度黑客,那么我们可以通过构建更大的计算机或编写更高效的算法来超越它们。
毫无疑问,人类比其他动物传播更多的文化知识。这与语言有关。 (更具体地说,我认为我们的生物学笔触语言在50,000年前袭击了一个关键点。)复杂的语法不存在于任何非人类动物中。 Wernicke'涉及区域。 Wernicke' S区域可能是一个特殊的架构。
上述人类优势有多重要?我相信采取受欢迎的ANN架构并仅仅缩放它不会使神经网络能够在星际争霸中与人类竞争等量的培训数据。如果另外,ANN不允许使用转移学习,那么我愿意在这一预测上公开赌注。 (ANN必须限于每秒人为行动率。安娜没有通过API或类似的手工编码预处理器进行播放。如果ANN观看其他玩家的视频,那么这对它的培训数据有所依赖。 )
如果Ann可以' it使用转移学习,' s漂亮的不公平,因为人类可以。 ('不像婴儿直接从子宫中播放星际争霸;人类可以学习星际争霸,但只有多年的多年在各种环境中的不同数据进行预训练)
好点子。允许转移学习,但它仍然符合培训数据的总培训数据;培训数据"现在是人类可以在一生中处理的一切。
由于需要迭代VS直到收敛,预测编码网络的计算成本大致100倍,而不是背部网络。
这似乎暗示,人造NNS是100倍的计算效率(以不能增长并且可能降低容错等的成本)。仍然,i' m更新以模拟需要比大脑中的神经元更小的CPU需要表明的大脑。
假设大脑使用预测编码来实现BackProp,而它可能改为在其硬件限制的情况下做出更多计算效率的事情。 (实际上,它的事实' s如此效率低效,让您更新它'不太可能为大脑做到这一点)
部分,是的。但部分计算可能是与它的交易交易(成长,容错,......)的交易相比廉价的部分。大脑架构也可能允许它包括更广泛的输入,这些输入可能无法使用背部产品(或没有有效地)。
我认为那个早产权。这只是一个BNN型号的一个(数字,同步)实现,可以显示在与BackProp相同的结果上会聚。在该电路的神经形态实现中,收敛将在与前向传播相同的时间尺度上发生。
斯科特总结了预测性处理理论,以非常便宜的方式解释(无需数学),并使用它来解释一大堆心理现象(注意,想象力,运动行为,自闭症,精神分裂症等)
有人可以为我提供ELI5 / TLDR本文,以非技术人员更容易获得的方式解释?
- 如果信息可以&#39向后流动,背部工作如何? - 在Scotts Post中,他说,当较低级别的感测数据违反高级别预测时,在没有注意到它的情况下,高级层可以覆盖较低级别的预测。但是,如果低级感测数据具有高置信度/精度 - 较高的级别会通知它,您的体验"惊喜"哪一个相当于背景错误?它是低级别的预测被覆盖,或者高级别的层注意到惊喜,或者其他东西,如改变神经元之间的连接来训练网络并以某种方式从错误中学习?
它已知预测编码是否比返回更容易训练?本地学习规则似乎它们将更加平行化。
然而,我们示出了由标准梯度下降算法学习的深网络实际上大致相当于内核机器,这是一种简单地存储数据的学习方法,并通过相似函数(内核直接用于预测。这极大地提高了深网络权重的可解释性,通过阐明它们是有效的训练示例的叠加。网络架构将目标函数的知识包含在内核中。
本文的第一个缺点是其结论假设具有梯度流动(GF)的列车下的NN,这是梯度下降(GD)的连续时间版本。如果学习速率非常小,并且由此产生的GD动力学紧密地跟踪GF微分方程,则这是一个很好的假设。
似乎在实践中似乎并不是这种情况。更大的初始学习率有助于获得更好的性能(https://arxiv.org/abs/1907.04595),人们在实践中使用它们。如果人们在实践中使用的是由GF近似地近似,那么较小的学习率会给出相同的结果。您可以使用另一个似乎似乎对GD相当好的另一种差分方程(http://ai.stanford.edu/blog / whebecharics/),但我不知道纸上的数学是否仍然效果。
其次,正如论文所指出的那样,GD学习的内核机器有点奇怪的是,系数$ A_I $用于称重不同$ k(x,x_i)$依赖于$ x $。因此,所得到的输出函数不在封入内核的再现内核HILBERT空间中,该空间被声称描述NN。结果,作为内核机器,它'非常奇怪。我希望大量分析学习过程的输出(学习理论等)假设$ A_I $不依赖于测试输入$ x $。
您是否知道使用类似方法来研究通过预测编码学习的等效内核机器的任何工作?
我不,我最好的猜测是没有人这样做:)你所谓的纸张是最近的。
您' D必须首先找到预测编码的ode模型,我认为可能将学习率限制为0。
由于需要迭代VS直到收敛,预测编码网络的计算成本大致100倍,而不是背部网络。
本文要求预测编码需要更多计算。我同意预测编码应该更平行化。如果您使用的是GPU,则BackPropagation已经充分并行化。然而,可能是神经形态硬件可以比GPU更好地平行化,这产生了计算功率的增加,该计算能力超过了算法本身的100倍的计算成本。
稿件似乎有几个符号错误。 (可能值得直接向作者伸出援手)
它们的预测编码算法在收敛过程中固定的VHAT值,其实际上意味着多个不同的网络拓扑,而不是图中所示的更传统的网络拓扑。
等式2的右侧。此外,算法1中的V更新步骤应该具有否定标志(同一页面上的文本版本具有正确的文本版本)。
黑色V圈代表神经元。红色ε三角形表示激活(动作电位)。行动潜力'在突触前神经元和后腹膜神经元之间共享信息含量,因为激活从突触前神经元传播到后腹膜神经元。
底部图中的黑色箭头表示动作电位的物理创建。红色箭头表示梯度的神经元内计算。请记住,每个神经元都知道它产生它自己的动作潜力以及发送给它的动作电位。
哦,这更有意义。 Delta v1帽子的变化V1而不是一个infintesimal? (询问,因为它是它' d更容易理解它是如何计算的)。
神经元和&#34之间没有关系;神经元"一个安。这一点''此时只是一个命名的事故。