Google的深度学习发现了AI芯片的关键路径
一年前,ZDNet与Google Brain总监Jeff Dean谈了有关该公司如何利用人工智能促进其定制芯片内部开发以加速其软件的过程。迪恩(Dean)指出,在某些情况下,人工智能的深度学习形式可以比人类做出更好的决策,以决定如何在芯片中布局电路。
本月,Google在arXiv文件服务器上发布的论文“阿波罗:可移植的体系结构探索”中向世界展示了一个名为Apollo的研究项目。以及主要作者Amir Yazdanbakhsh的同伴博客文章。
阿波罗代表着一个有趣的发展,它超越了迪恩一年前在国际固态电路会议上的正式讲话中以及在他对ZDNet的讲话中所暗示的含义。
在Dean当时提供的示例中,机器学习可用于一些低级设计决策,即“布局和路线”。在位置和路线上,芯片设计人员使用软件来确定构成芯片操作的电路布局,类似于设计建筑物的平面图。
相比之下,在阿波罗,该计划执行的是Yazdanbakhsh及其同事所说的“架构探索”,而不是平面图。
芯片的体系结构是芯片功能元素的设计,它们如何相互作用以及软件程序员应如何访问这些功能元素。
例如,经典的Intel x86处理器具有一定数量的片上内存,专用的算术逻辑单元和许多寄存器等。这些部分的组合方式赋予了所谓的英特尔架构以意义。
当被问及关于Dean的描述时,Yazdanbakhsh在电子邮件中告诉ZDNet,我会看到我们的工作和布局规划项目是正交且互补的。
"架构探索比计算堆栈中的布局布线高得多," Yazdanbakhsh解释说,指的是康奈尔大学克里斯托弗·巴顿(Christopher Batten)的演讲。
"我认为[架构探索]是存在更高的性能改进余地的,"亚兹丹巴赫什说。
Yazdanbakhsh及其同事将Apollo称为“第一个可转移的架构探索基础结构”。第一个程序越能在不同的芯片上工作,它就能更好地探索可能的芯片架构,从而将学到的知识转移到每个新任务上。
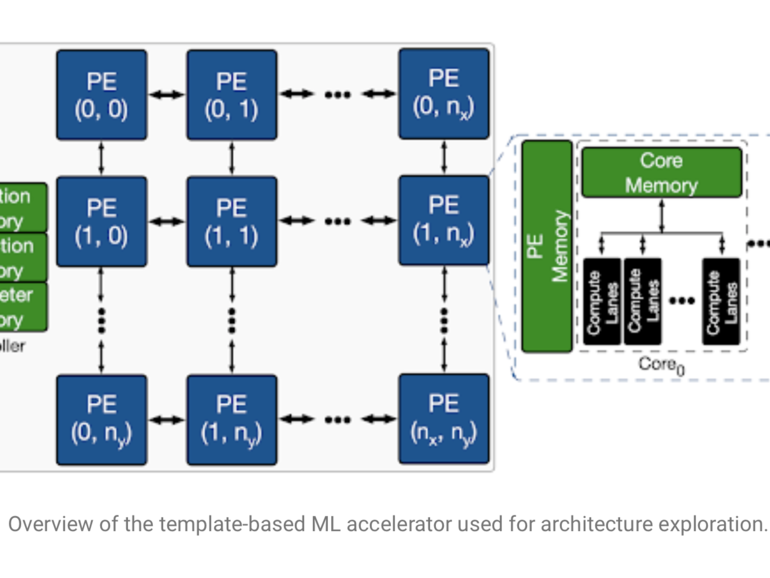
Yazdanbakhsh和团队正在开发的芯片本身就是用于AI的芯片,称为加速器。这是与Nvidia A100& Ampere"芯片相同的芯片。 GPU,Cerebras Systems WSE芯片和许多其他启动零件目前正在投放市场。因此,使用AI设计运行AI的芯片具有很好的对称性。
鉴于任务是设计一个AI芯片,Apollo程序正在探索的架构是适合运行神经网络的架构。这意味着很多线性代数,很多简单的数学单元执行矩阵乘法并对结果求和。
团队将挑战定义为找到适合给定AI任务的这些数学块的正确组合之一。他们选择了一个相当简单的AI任务,即一个称为MobileNet的卷积神经网络,这是一种由资源节约型网络组成的网络,由Andrew G.Howard和Google的同事于2017年推出。此外,他们使用多个内部设计的网络测试了工作负载,以执行诸如对象检测和语义分段之类的任务。
这样,目标就变成了,对于芯片的体系结构来说正确的参数是什么,以使得对于给定的神经网络任务,芯片满足诸如速度之类的某些标准?
搜索涉及对超过4.52亿个参数进行排序,包括将使用多少个数学单元(称为处理器元素),以及对于给定模型而言最佳的参数存储量和激活存储量。
Apollo是一个框架,这意味着它可以采用文献中开发的多种方法进行所谓的黑盒优化,并且可以使这些方法适应特定的工作负载,并比较每种方法在解决目标方面的效果。
在另一个很好的对称性中,Yazdanbakhsh采用了一些优化方法,这些方法实际上是为开发神经网络体系结构而设计的。其中包括Google的Quoc V.Le及其同事于2019年开发的所谓进化方法;由Christof Angermueller和其他人在Google进行的基于模型的强化学习和所谓的基于总体的方法集成,目的是“设计”。 DNA序列;和贝叶斯优化方法。
因此,Apollo包含了令人愉悦的对称性的主要层次,将为神经网络设计和生物合成设计的方法汇集在一起,以设计可用于神经网络设计和生物合成的电路。
比较所有这些优化,这就是Apollo框架的亮点。其整个存在的理由是要有条不紊地运用不同的方法,并找出最有效的方法。阿波罗(Apollo)试验结果详细说明了进化方法和基于模型的方法如何优于随机选择和其他方法。
但是,阿波罗最引人注目的发现是,与蛮力搜索相比,运行这些优化方法如何使效率更高。例如,他们将基于群体的集成方法与他们所说的对体系结构方法的解决方案集的半穷尽搜索进行了比较。
Yazdanbakhsh及其同事看到的是,基于人群的方法能够发现利用电路中权衡取舍的解决方案,例如计算与内存,而这些通常需要特定领域的知识。由于基于人群的方法是一种博学的方法,因此它可以找到半穷举搜索无法找到的解决方案:
实际上,P3BO(基于人口的黑盒优化)发现的设计比3K样本搜索空间的半穷尽略好。我们观察到该设计使用非常小的内存大小(3MB)来支持更多的计算单元。这充分利用了视觉工作负载的计算密集型性质,而原始半详尽搜索空间中并未包含该功能。这证明了半穷举方法需要人工搜索空间工程,而基于学习的优化方法利用了较大的搜索空间,从而减少了人工工作。
因此,Apollo能够弄清楚不同的优化方法在芯片设计中的效果如何。但是,它还可以做更多的事情,那就是它可以运行所谓的转移学习来显示如何依次改进这些优化方法。
通过运行优化策略以将芯片设计提高一个设计点,例如最大芯片尺寸(以毫米为单位),然后将这些实验的结果作为输入输入到随后的优化方法中。 Apollo团队发现的是,通过利用初始或种子优化方法的最佳结果,各种优化方法可在诸如面积受限的电路设计之类的任务上提高其性能。
所有这些必须由以下事实括起来:为MobileNet或任何其他网络或工作负载设计芯片受设计过程对给定工作负载的适用性的限制。
实际上,其中一位作者Berkin Akin帮助开发了MobileNet版本MobileNet Edge,他指出优化是芯片和神经网络优化的产物。
神经网络架构必须了解目标硬件架构,以优化整体系统性能和能效,去年在与同事Suyog Gupta的一篇论文中写了Akin。
ZDNet通过电子邮件与Akin联络,问一个问题:与神经网络体系结构的设计隔离时,硬件设计有多有价值?
Akin说,Apollo对于给定的工作负载可能就足够了,但是在芯片和神经网络之间进行的所谓的协同优化,将在未来产生其他好处。
当然,在某些用例中,我们正在为给定的一组固定神经网络模型设计硬件。这些模型可以是硬件目标应用领域中高度优化的代表性工作负载的一部分,也可以是定制加速器用户的要求。在这项工作中,我们正在解决这种性质的问题,我们使用ML为给定的工作负载套件找到最佳的硬件体系结构。但是,当然在某些情况下,可以灵活地共同优化硬件设计和神经网络体系结构。实际上,我们正在进行一些此类联合优化的工作,我们希望可以取得更好的权衡...。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
那么,最后的收获是,即使芯片设计受到AI的新工作量的影响,芯片设计的新过程也可能对神经网络的设计产生可衡量的影响,并且辩证法可能会以有趣的方式在神经网络中发展。几年以后。