#scraping
Screen scraping and TinyML can turn any dial into an API(petewarden.com)
2021-3-1 8:51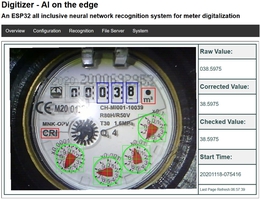
该图显示了传统的水表,已使用廉价的ESP32相机和机器学习功能将其转换为网络API,以了解表盘和数字。我预计在未来十年中将部署数十亿台这样的设备,不仅用于水表,而且用于任何具有刻度盘,计数器或显示器的旧设备。我已经从多个团队那里听说过,他们需要在老式炼油厂,农田,办公楼,汽车和房屋等各种环境中监控旧硬件。其中一些设备......
Web Scraping with JavaScript(qoob.cc)
2020-10-27 0:57如果你尝试用谷歌搜索“网络抓取教程”,你会得到一堆关于这个主题的技术文章,告诉你如何使用python来达到这个结果。这个工具包对于这些帖子来说是相当标准的:Python3(希望不是第二个)作为引擎,Requests Library用于抓取,以及Beautiful Soup4(已有6年历史)用于Web解析。
我也看过一......
Git scraping: track changes over time by scraping to a Git repository(simonwillison.net)
2020-10-11 15:53
Git刮是我给一种刮技术起的名字,我已经试验了几年了。它真的很有效,应该有更多的人使用它。
互联网上充满了有趣的数据,这些数据会随着时间的推移而变化。这些更改有时可能比底层的静态数据更有趣--例如,@NYT_DIFF Twitter帐户跟踪对“纽约时报”标题所做的更改,这为了解该出版物的编辑流程提供了一个有趣的视角。......
2020-8-16 3:12
据估计,互联网包含40万亿GB的数据,即后面有12个0的40个数据。根据Internetworld的统计,从2000年到2020年,用户数量惊人地增长了1200%,随着使用量的增长,数据也随之增长。
有了所有这些数据,那些找到用武之地的人将比那些无视其价值的人拥有几乎不公平的优势。
您如何收集、管理和使用信息将决定您......
Web Scraping with Prolog(www.youtube.com)
2020-6-23 4:26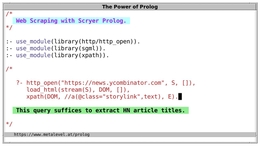
Prolog非常适合Web应用程序。HTML和XML文档很容易表示为Prolog术语,并且可以很容易地通过内置的.