论容忍复杂性(叙事性非虚构类遇见科技博客)

我手头现有的出版工具不是特别好用来展示我的想法,但它们足够方便,我可以直接写下来,把实际阅读它们的问题留给那个博客上发生Toland的任何人。
我是说,这只是个博客。从8个顾客开始,它得到的交通流量主要是朋友。他们可以忍受的。
但不幸的现实是,我不能完全忍受看着做得不好的事情。我们可以涂鸦的感觉萦绕在我的脑海里。编辑可以更简单。发布可能会更快。想起来容易多了。
即使最终结果更糟,我也会尽力做到最好,虽然我会第一个承认它可能不是最吸引人的品质,但它总是教会我一些新的东西。每隔一段时间,我都会设法把它做得更好。我周围的世界也因此变得更美好了。
这一次我不得不坐下来写点东西。我还不太清楚是什么,但我知道我的写作方式妨碍了我想要写的东西。所以我退了一步,四处打听这些酷孩子们这几天过得怎么样。
许多人似乎喜欢像Next.js、Gatsby或Hugo这样的工具。它们都提供了适合您内容的某种结构或模板,几种进行主题和导航的方式,以及将整个Shebang作为静态或动态生成的服务运行的可能性。
我只需要一些静态文件,并且我需要它们在它们已经存在的结构中,所以从我得到的选择看起来获胜者实际上是Next.js。它附带了几个有趣的功能,我把它们斥为花言巧语,并且对我的页面必须被翻译成Reaction组件的要求不屑一顾。
当然,一个如此强调开发人员体验的工具会考虑我的数据可能采用的多种格式,并适应它。但是Inonethless决定把一篇文章翻译成一些Javascript代码,我终于觉得我可以开始写作了。
突然,不知何故,有人建议我从我自己的写作开始,用我自己的写作,找到好的Javascript组件库为我做突出显示的好的Javascript组件库,它现在不再只是文本,实际上是一个伪装成一篇文章的计算机程序。
快速浏览一下引擎盖下面,我发现有超过10万行的Javascript代码可以将我不同凡响的话变成一个该死的网站。
我们的日常工作有相当大的复杂性,我使用的是vim,在我的计算机上,它运行在Linux内核上。我可以容忍从那里到它运行的硬件的数百万行代码。宽容是这里的关键词。他们给我买东西。不是像食物这样的物质东西,而是当你发现一个新的想法时,你的思维所获得的启示。
当我第一次了解GIT时,我突然有了一个新的思考工具。我不熟悉Subversion或其他版本控制工具的分支模型,但Git的分支、合并和代码历史扩展了我的想法。我对GIT的内部结构有一个模糊的理解,但我容忍这种复杂性,因为它给我提供了什么。
这个工具到底为我提供了什么这么复杂的功能呢?我已经支付了将我的内容翻译成它想要的格式的费用,还有什么呢?资产的热重装。太棒了。我的资产是样式表文件、临时图像和一两个嵌入式脚本。我已经可以用按键刷新浏览器了。还有什么?
从表面上看,这个工具并不能很好地支持我的用例。像Next.js这样非常流行和复杂的东西怎么能不支持我看似简单的用例呢?我一定是错了。如果我不能在不引入更多信息的情况下利用它,那么所有这些复杂的东西都会走向何方?
之所以存在一些复杂性,是因为潜在的问题实际上是复杂的。它需要处理,不能再减少了。我们倾向于将这种本质复杂性称为本质复杂性。NeXT中所有的复杂性仅仅是为了证明让我觉得有效率是合理的吗?
我开始想知道,我需要做的事情到底有什么本质上如此复杂,但没过多久,我就列出了一张看起来最独立的事情清单:
我希望我的Markdown文件编译成相应的HTML文件,考虑到它们的现有结构。
他们就在那里。这个问题可以突破的5个要求。我不应该花超过几天的时间去深入研究它们中的每一个,才能理解我所看到的是不是巨大的本质复杂性。
Markdown是作为一种更人性化的HTML编写方式引入的。它已经从一个语法不一致的移动目标演变成了一系列标准,其中一些标准描述了一种相当复杂的格式,具有大量的功能。
要构建一个Markdown to HTML编译器,我必须清楚地知道我将支持哪种Markdown格式。因为我的内容目前主要是按照Github口味的Markdown写的,所以这似乎是Markdown的目标。
每个编译器都有一系列阶段,获取初始源代码或程序的类似规范,然后转换为另一种语言。有些编译器把源代码变成机器语言,有些则把它变成另一种高级语言。
无论您的目标是什么,编译器都有可能读取一些二进制字符串(有时这只是UTF-8文本,有时是它实际的二进制编码数据),并将它们转换成它可以操作的东西。然后,它继续将这些数据结构转换成更接近所需输出的东西,可能会在此过程中进行一些检查。
Markdown文本的解析-解析阶段需要一个Markdown解析器来处理GFM的怪癖,而CommonMark规范则建立在它的基础上。
Markdown结构和HTML树之间的转换-这将采用诸如段落{Content:String}或列表{Elements:VEC<;ListElement>;}之类的数据结构,并将它们转换为适当的HTML树。
写出HTML树-它将接受一个DomNode{tag:DomTag,Attributes:VEC<;DomAttribute>;,子节点:VEC<;DomNode>;},并将其转换为可写入文件的字符串。
枚举MarkdownNode{Heading1(Vec<;MarkdownNode>;),//对应于a#Heading2(Vec<;MarkdownNode&>),//对应于##块报价(Vec<;MarkdownNode>;),//对应于>;//...}struct MarkdownDoc{Nodes:vec<;MarkdownNode>;}enum。VEC<;HtmlAttribute>;>;,子项:Option<;Vec<;HtmlNode>;>;},文本{Child:string}}fn string_to_markdown(input:string)->;result<;MarkdownNode,Error>;{}fn markdown_to_html(md:MarkdownDoc)->;result<;
我花了大约一个小时阅读规范才意识到,为整个语法实现一个解析器很容易花费我一周多的时间,而我没有这样的时间。这也可能是一个非常错误的过程。
当然,这是一件非常有趣的事情,但是在更好地理解了这个具体问题之后,我可以忍受引入第三方Markdown编译器的复杂性。
模板可以采用多种形状和形式。从成熟的编程语言到更普通形式的字符串匹配和替换,都支持ERB(Embedded Ruby)风格。
考虑到我不需要执行任何特定的逻辑,我的模板需要更接近字符串匹配,然后进行一些拆分和连接。
我有一个template.html文件,中间的某个地方有一个关键字,我想用我正在撰写的文章的实际内容替换它。
我们如何准确地找到要被内容替换的单词并不重要,但是从大量的参考书目中,我保存了一份FlexiblePattern Matching in String,这是实现这些算法的一个很好的资源。
一旦您知道在哪里拆分模板以注入内容,剩下的就是字符串连接。
值得庆幸的是,现代编程语言擅长为我们提供字符串操作工具,因此将其组合在一起所需的代码几乎与伪代码一样多:
就我的用例而言,让整个增量呈现组件框架(如Reaction)跨页面重用组件以达到相同效果的复杂性是不可容忍的。
我们使用的很多工具一遍又一遍地做同样的事情,有时这是可以的。有时这是强制性的。
就我的用例而言,因为我希望保留编译的输出版本,所以编译过程应该只重做需要完成的工作。
这有一个附带的好处,那就是重新编译这些文档应该相对较快,因为我倾向于一次只处理一个文档。有时,模板文件中的更改只会触发使用它的文档的重新编译,但这项工作是必要的。
它的速度还不够快,我不介意一遍又一遍地做,如果不做就会产生一件破损的艺术品。
因此,这里的一个隐藏要求是,构建过程应该确保相互依赖的工作被正确链接,并且如果上游工作必须重做,那么依赖的下游工作也将再次进行。
当我们想到工作及其依赖关系时,一个非常有用的思维工具就是图论。现在我不是专业的数学家,但是构建类似树的数据结构是我们在函数式语言中轻而易举地做的事情。即使我们自己没有定义新的列表,我们也已经使用了列表的归纳定义,这可以被认为是有向循环图,其中每个节点都可以有一个子节点。
枚举构建计划{WithDependants{TODO:CompilationUnit,Then:VEC<;Buildplan>;},无依赖项{TODO:CompilationUnit}}。
有了这个心智工具,我们就可以对我们的整个构建计划进行建模,即我们为实现目标而必须执行的步骤,而不一定要进行实际的编译。然而,我们将不得不描述沿途的每一步,以及未来实施它所需的所有信息。
Enum CompilationUnit{//要创建目录,需要知道其路径CreateDir{path:string},//要复制文件,需要知道其源副本和目标副本{src:string,dst:string},//要编译文件,需要知道编译什么以及放在哪里编译{input:string,output:string},//要将文件作为模板,还需要知道使用什么模板{input:string,output:string,template:string},}。
似乎因为我们在这里只处理文件,所以我们可以利用预期的输出来验证它们是否已经在它们应该在的位置,并使用它来避免重复该工作。
像Google的Bazel这样的工具已经在这个领域做了大量的工作,它们在处理跨各种语言的大规模编译图形的分布式和并行执行方面表现出色。
尽管如此,对于我的用例来说,问题的基本复杂性可以归结为遍历树和一些文件系统操作。在这种情况下,引入一个外部图形库的能力超过我认为是不可容忍的。
在构建了文档编译器的大部分之后,我展望了如何使这些输出在Web浏览器中可用。
在该堆栈的底部,我们需要侦听abrowser可以连接到的TCP套接字,这样我们就可以了解浏览器正在请求什么,并可以访问文件系统以读取、编码和使用适当的HTTP响应回复到浏览器。
我已经将IP/TCP堆栈包括在可容忍的集合中,但是让我们快速检查一下原因。重新实现TCP堆栈需要我坐下来仔细阅读IETF的RFC793。我不确定我是否能理解那份80页的文档中所描述的一切,所以我马上说,这可能需要我几个月的工作。我没有那样的时间。
这里的下一层是HTTP。出于非常相似的原因,这归入了可容忍的一类。阅读并重新实现用于HTTP/1.1的原始RFC2616或任何后续更新(这些更新取代了第一个规范)将花费我数周(如果不是数月)的工作。
最后,还有一项工作是将HTTP请求转化为针对文件系统的特定操作,并将适当的响应组合在一起。这应该不会那么难。
//说明ideafn handle_request(req:request)->;response{let request_path=req.path();let tual_path=project_folder.join(Request_Path);let file_content=read_file(Tual_Path);response::OK(File_Content)}的伪代码。
如果我能得到一些表示浏览器请求的结构或对象,我应该能够提取一些东西,比如路径,并用它来构造到实际底层文件的路径。
读取文件是大多数编程语言已经具备的功能,这样就可以做到这一点。
将请求路由到我已经知道存在的磁盘中的文件的基本复杂性主要由TCP和HTTP协议吸收,我不会实现这些协议。
其余部分是可管理的,因此引入第三方静态文件服务器解决方案似乎是不可容忍的。
我就在那里。我可以建立我的文档,我可以提供它们。但它们是最稳定的。
我在这里要坦率地说。当你修改实际运行的系统时,这种热重新加载是浏览器最接近Smalltalk给你的感觉。
一旦你拿到了这样的工作流程,除了表达你的意图之外,很难再回到任何其他要求你的事情上。
就像我发现离开键盘用鼠标选择一个单词很困难一样,手动刷新浏览器来突然看到我的更改也是一件我不能不皱眉的事情。
所以我坐了下来,我想知道是什么让热重新加载在这种情况下工作。如何告诉浏览器重新下载并重新应用现有DOM节点上的样式?那图像呢?我也可以随时更新它们吗?
在控制台中四处查看,抓取<;link/>;字段的句柄,并尝试更新HRED属性。
“网络”选项卡中有一个请求飞过。此更改由浏览器自动获取,并尝试下载新的、明显缺失的样式表。
我将旧值返回,我看到旧样式表再次被下载。很明显,为该属性分配一个新值将重新触发该资产的下载。
在更改了磁盘中的CSS之后,我再次尝试,样式也更新了。这对图像也有效。
我对这个发现很满意,我意识到如果我能把已经更改的资产列表放在一起,那么我就可以有一个单一的请求/响应周期,它可以告诉浏览器需要更新的内容。
我开始工作,在HTTP服务器中创建了一个新的处理程序,并让thathandler等待,直到实际上有了来自编译的新创建的工件。这很容易,因为计划构建已经返回了一个值和必须完成的工作量。
Fn WAIT_FOR_CHANGES(请求:请求)->;响应{let Changed_files=[];loop{let build_plan=plan_build();if build.has_work_to_do(){build.ecute();change_files=build.new_files();Break;}睡眠(";100ms";);}响应:OK(Changed_Files)}。
有点天真,我会承认这一点,但考虑到重新编译已经非常有效,而且只有在有人倾听变化的情况下才会发生,我会说这并不是那么糟糕。
然而,在浏览器端,我必须发出此请求以等待更改自动发生,而无需任何用户干预。对我来说,必须在文档中并排编写一些古怪的实时重载代码是没有任何意义的,所以我需要找到一种方法,将少量的Javascript注入到响应中,以自动发出此请求,并对其返回的响应采取行动。
这个过程本身需要解析即将请求的HTML,并拼接一个新的DOM元素来运行nesidedJavascript。反过来,我必须实现遵循W3CHTML规范的HTML解析器,而我没有时间做这件事,所以引入一个解析器的复杂性是合理的。
在此之后,所有这些都很好地结合在一起,但是对于我的用例来说,第三方热重载程序所涉及的复杂性是不可容忍的。
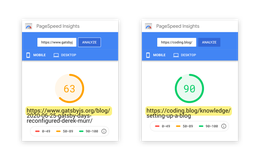
就这样,一周过去了,我做了我担心的事情:我花了整整一周的时间编写文档构建器,而不是编写实际的文档。
我仍然不确定,1000行相当业余的Rust代码,阅读RFC、语言规范,以及对Bazel、Dune、Next.js、TCP、HTTP和许多其他我将不会提到的作者令人难以置信的天才工作的实现,是否真的让世界变得更好了。
我不确定我认识的人中有没有人会鼓励我自己去做。如果你正在读这篇文章,如果你愿意,那就伸出援手。
我确信的是,我已经学到了更多关于我使用的工具中有哪些东西是我重视的,以及它们是如何帮助我工作的。
我了解到,我喜欢投资合理的更好的工具,比如git如何通过几个比喻赋予我时间旅行的能力。
我了解到,我喜欢尊重我的数据高于一切的工具,比如Dune和Bazel如何尊重我的文件夹结构,无论它们可能有多疯狂。
我了解到我的意图和它所产生的效果之间存在差距,而热重新加载是在浏览器中弥合这一差距的一个很好的方式。
最重要的是,我认识到我重视那些帮助我更清晰地思考的工具,当我理解为什么事情是复杂的,并能够做出自愿的决定来容忍或反对它时,我的思考最清楚。
而这似乎是当今软件最需要的。少一些闪光,多一些理解。少一些诱饵,多一些问题。