Sohu Blog's robots.txt has a low-level error.
by scseoer on 2011-08-31 19:39:11
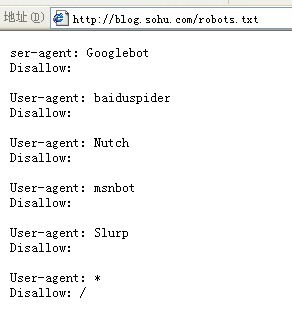
When a search spider visits a site, it first checks whether there is a robots.txt file in the root directory of the site. If it exists, the search bot will determine the scope of access according to the content of this file; if the file does not exist, all search bots will be able to access all pages on the website that are not password-protected.
Below is the robots.txt file for Sohu Blog: