The Difference Between Google's Pseudo-static and Static HTML
First, let's look at the question of which is better.
Based on years of observation of Google, this issue has been basically perfectly resolved by Google. This means that for Google today, whether using pseudo-static or static HTML, both can be crawled and indexed well, without the phenomenon that dynamic URLs with multiple parameters were not crawled a few years ago.
With the crawling issue resolved, under equal conditions, which is better for search engines: pseudo-static or static HTML? The answer is static HTML. As of now, this is the case, but it’s not guaranteed to remain so in the future (this issue will be discussed further later).
The above must apply under equal conditions, as mentioned in a previous article titled "Google Explains Dynamic, Static, and Pseudo-Static URLs." You need to compare such a URL:
`upload/200912020904484252.jpg"`
(Click to view large image)
In the image above, on the left is a pseudo-static page of an article, and on the right is a static HTML file. By comparison, two obvious differences can be seen:
**Last-Modified**: Static HTML has a modification time (for search engines, this means they can directly obtain the file modification time).
**Content-Length**: File size (SEO experts should know that file size impacts search engines; if Googlebot can directly obtain the file size from the server as a reference, the efficiency of crawling will be higher).
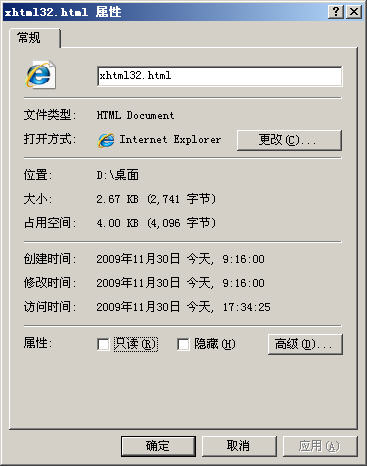
Below is the file attribute of static HTML:
Finally, let's speculate why Google considers static HTML to be superior to dynamic URLs.
By comparing the working methods of static HTML and dynamic URLs:
**Static HTML**: Successful communication between the client and server, and the server directly sends the file attributes and content.
**Dynamic URL**: Successful communication between the client and server, and the server generates the page content based on the client's request, then sends the server information and requested content.
Using dynamic URLs: If there is a problem with the program, all content based on this program will become inaccessible; if the template changes, all information will change even though the truly valuable content hasn't changed; if the database ID is not unique, newly added content may reuse the ID of deleted content, leading to the situation where the URL remains unchanged but the page content completely changes...
However, if it is static HTML, the file only exists in the state of "exists & does not exist" (excluding the server status), and "modified & unmodified" (just read the Last-Modified value).
After such analysis, the conclusion is: Static HTML has higher stability.
This speculation also explains a common issue in SEO: some documents (PDF & DOC & XML) within a website often have relatively high weight.