对流式 ByteString 的颂歌
我最喜欢的创始原则之一 鉴于 Unix 对大量厨房水槽程序并不陌生,我们中间的愤世嫉俗者可能会将其称为神话而不是原则。事实上,我正在这样一个程序中写这篇文章。 Unix 的特点是字节流的普遍性。 Unix shell 为我们提供了一个一元管道运算符 |,即,给定一些计算 a | b, 执行 a 使其输出形成 b 的输入。这一原则为标准的 Unix 命令提供了简洁的组合,允许执行 shell,而不是程序本身,通过一个组合的 shell 命令序列来控制数据流。事实上,字节流操作的原理是整个编程语言(如 sed 和 awk)的基础。 xargs 和 tee 和 parallel 等工具提供了高阶组合器,以超出管道操作员本身能力的方式从更多管道构建管道。让我们考虑在诸如此类的流水线计算中运行良好的程序的一些属性,使用 grep 作为此类程序的原型。当然,grep 是一种具有近乎无与伦比的重要性的工具,它被载入 POSIX 标准,并且它的优化可能与任何其他程序一样彻底。我们的程序可能不是 grep,但它们可能需要模拟 grep 如何管理其输入流:它隐藏了资源操作的细节。操作系统、其系统库、当前使用的外壳及其实现 |操作员隐藏了输入如何在文件之间进行批处理和馈送的详细信息。鉴于这些细节是从我们这里抽象出来的,我们应该假设输入在必要时被缓冲和分块,并且这些缓冲区和块的处理开销尽可能小。特别是,从输入流读取的字节缓冲区应该只在程序明确请求时才被复制和保留:旧的输入不应该在内存中徘徊,因为该输入的大小理论上是无界的。它懒惰地消耗其输入。如果我告诉 grep 在一个 10 GB 的文件中搜索一个且仅出现一次的字符串,它应该只消耗满足我的请求所需的输入量。如果从流中读取的字节数超过所需的字节数,则在性能方面应该与读取尽可能少的输入没有区别,并且不会对可观察到的程序行为产生任何变化。它清理它的资源。如果 grep 向操作系统请求资源,或者产生一些其他辅助进程,这些资源和子进程应该被快速可靠地回收,即使面对上游或下游管道故障,甚至只是一个用户不耐烦地敲击 Ctrl+C 并发送数十个SIGKILL 信号。 C 程序擅长满足这些标准。哈!只是在开玩笑。 C程序可以擅长流式数据操作,因为C编程将其细节托付给您,您可能是擅长流式数据操作的人。尽管 POSIX 标准提供了某些保证 POSIX 标准指定某些资源——文件描述符、目录流、来自 iconv() 的流转换器和来自 catopen 的消息目录——在程序退出时被放弃。使用 exec 系列函数产生的子进程通常不会终止(除非父进程或相关进程组特别请求)。共享内存可能会或可能不会被放弃,这取决于其他进程是否正在引用它。这种离题已经足够长了;如果您真的很好奇,请阅读标准。关于程序退出时资源回收的方式,您仍然负责在程序执行期间管理资源。你、标准输入和标准输出之间没有太多的抽象层。当然,如果你的底层 FILE* 结构可以为你做一些缓存,它可能会,但你总是可以直接使用 read(2) 或一些低级别的以效率为重点的框架,如 kqueue、epoll、libdispatch 或 io_uring。使用更高级别的垃圾收集语言,事情变得有点棘手。高级语言有责任将我们与 C 的问题隔离开来:与 shell 脚本一样,在一般情况下,我们不应该特别了解如何读取文件、如何分配内存或如何输入被缓冲。对于大多数程序,尤其是垃圾收集语言擅长的快速而肮脏的程序,这些细节无关紧要。但是,当您发现自己处于“大多数程序”的范围之外时,情况可能会令人烦恼:当您的软件的正确性取决于细节时,高级语言的性质会将您与资源管理决策隔离开来所说的资源管理。我们发现自己面临着一个特别棘手的辩证法:高级语言通过抽象细节来帮助程序开发,但是当程序正确性直接取决于这些抽象细节的属性时,例如编写处理错误条件的代码时,就会阻碍程序的开发在存在资源压力的情况下稳健或保持可靠。在可移植 shell 脚本中解决这些问题时遇到的困难只是我们不在 shell 中编写所有内容的众多原因之一。
至少在理论上,Haskell 的声明性、非严格评估和正确构造哲学使其成为编写在流管道中运行良好的代码的有吸引力的解决方案。然而,在实践中,我们遇到了三个相互关联但又截然不同的问题,这些问题与上面概述的管理良好的输入流的属性表现出很好的对称性: 流问题:我们如何编写 Haskell 代码来处理潜在的无限数据流有限的内存?懒惰的 I/O 问题:鉴于 Haskell 的非严格语义,我们如何懒惰有效地消费来自外部世界的输入?资源操作问题:鉴于我们无法直接控制数据的生命周期,我们如何确保我们的代码正确管理和放弃昂贵的资源?我将讨论如何解决这些问题,使用流生态系统来解决第一点,流字节串库是第二点,而资源库是第三点。鉴于 Haskell 的不止一种方法来做的哲学,存在许多替代的生态系统——像管道、管道字节串、streamly 和 io-streams 这样的库都提供了解决这些问题的工具——但流生态系统是我最熟悉的一种,一种用函数组合来表达的普遍友好的界面。流和流字节串都经过巧妙设计和深思熟虑;我希望这篇文章可以探索他们相关的设计决策和由此产生的习语。但是为了理解这个问题的深度,我们必须首先讨论 Haskell 如何表示字节缓冲区和数据流,以及他们的标准公式中的错误如何为流字节串提供其存在的理由。如果您已经熟悉 Haskell 字符串类型和惰性 I/O 的危险,请随意跳到下一节。 Haskell 因其过多的字符串类型而臭名昭著:String(四字节 Char 值的惰性列表);严格和惰性文本值,以及严格、惰性和短字节串值字节串包也提供了Data.ByteString.Char8和Data.ByteString.Char8.Lazy,但它们实际上在内存中使用相同的类型,并提供处理Char 和 String 值而不是 Word8 和 [Word8],前者可以更自然,只要您知道您的输入是 Latin-1 兼容的。 .就本文而言,我们不会担心 String 或 Text,因为它们都对已知为有效 Unicode 数据的值进行操作。我们的流管道对字节进行操作,而不是 Unicode 字符——如果说,我们希望能够在这样的管道中对二进制数据进行操作,那么试图将这些数据表示为 Unicode 文本本质上是错误的。因此,我们将只关注 Haskell 的字节缓冲区类型 ByteString。 Strict ByteStrings 很容易理解:
module Data.ByteString where data ByteString -- strict = BS {-# UNPACK #-} !( ForeignPtr Word8) -- payload {-# UNPACK #-} ! int——长度 ByteString 表示一个字节缓冲区及其相关长度;在这方面它类似于 Go 的 []byte 或 Rust 的 &[u8] (尽管它要跟踪的数据少了一个,因为 Rust 和 Go 类型提供对相关字节缓冲区的可变访问,因此必须跟踪其总容量) . ByteString 值可以包含 NUL 字节,或者实际上任何其他 Word8 值。如果给定的 ByteString 表示人类可读的文本,则必须使用 Data.Text.Encoding(对于 UTF-8/16/32)或编码库将其显式转换为 Text 值或 String 值;转换失败应该在这些调用点处理,尽管正确的行为通常是抛出异常。通过提取该 ForeignPtr Word8 并将其视为它所在的内存地址,此表示还允许快速序列化和反序列化为 C char* 值。类似地,我们可以选择通过从另一个源(如另一个 ByteString 或从套接字)复制来创建 ForeignPtr Word8,或者通过使用不安全的 ByteString 操作(这可能会破坏引用透明性,但有时在极低级别的代码中是必要的)而不进行复制)。支持 O(1) 长度和索引以及 O(n) 连接的内存和长度对非常简单。更有趣的是这种类型,懒惰的 ByteString。为了示例的清晰起见,我们将使用与 bytestring 不同的类型名称,它对惰性和严格变体都使用 ByteString 名称,通过模块名称消除歧义(Data.ByteString 表示严格,Data.ByteString.Lazy因为懒)。 module Data.ByteString.Lazy where import Data.ByteString 限定为严格数据 ByteString = Empty |大块{-#解包#-}! Strict.ByteString ByteString -- ^ head chunk -- ^ lazy tail 这不是一个严格评估的缓冲区和长度对,而是一个惰性列表,类似于我们用 [ByteString] 表示它的情况:Empty 是像 [] 和 Chunk 就像 : 操作符。唯一的操作区别是第一个严格的 ByteString 参数被严格评估,这稍微减少了它在内存中的开销。第二个参数,一个惰性 ByteString 表示字符串的其余部分,并不严格,因为这个企业的重点是让 Haskell 运行时管理与我们的字节缓冲区惰性列表相关的惰性。这听起来很重要:GHC 的评估器是一个经过微调的工具,我们不太可能因此而改进。这让我们想象一下 ByteStream.Lazy.readFile 是如何工作的:给定一些块大小 N,运行时将从源读取 N 个字节,将它们放在 !ByteString 参数中。然后,第二个参数将是一个 thunk,如果求值,将读取另一个最大长度为 N 的字节缓冲区。如果从不求值第二个参数——换句话说,如果我们的调用代码只对前 N 个字节进行操作,则 Lazy。 ByteString 参数永远不会被评估,并且永远不会产生读取更多字节的开销。实际上,这或多或少是该功能的实现方式。然而,从磁盘懒惰地读取文件时,懒惰的 ByteString 值不能可靠地工作。它违反了确定性资源清理的原则:一旦读取了一个块,读取其嵌入的 ByteString 需要评估它的第二个参数,这需要进一步的系统调用来执行进一步需要的磁盘 I/O 以构建另一个块(或者一个 Empty,如果我们re 在文件末尾)。如果这些系统调用引用已关闭的套接字或文件描述符,我们将遇到运行时崩溃。即使 openFile 发生在 IO monad 中,生成的 ByteString 也将 IO 邪恶地隐藏在其中,即使传递到它应该是纯的上下文时也是如此。我已经看到这被称为“伪纯”:它可能看起来像一个纯计算,但它可能导致 I/O 发生在其他地方,即使它有效,也不是 Haskell 方式。 I/O 太重要了,不能隐式!
这一直是一种非常冗长的方式来解释为什么在存在惰性 I/O 的情况下没有基本的字符串类型满足我们的所有标准:严格的 ByteString 被一次性读入内存,这违反了我们对惰性的需求和持续的资源消耗; Lazy.ByteString 违反了确定性资源清理的原则,除非您使用 Haskell 对线性类型的实验性支持,这可以防止惰性字节串超过其关联的文件句柄(尽管线性类型是尚未广泛采用的前沿特性)。现在,这可能并不总是重要的。您的程序可能只处理小文件,在这种情况下,您根本不需要惰性 I/O:您只需将文件内容作为严格的 ByteString 读取即可。现在的计算机有很多内存。但是 Haskell 是一种懒惰的语言,它擅长解决可以懒惰地措辞的问题。如果我们的业务逻辑是惰性流处理的问题,我们需要某种抽象,可以从具有恒定内存消耗、最少复制和安全、确定性资源清理的数据源中惰性地流式传输字节缓冲区。流、流字节串和资源的三重奏处理了这一点:让我们看一看它是如何工作的。 Stream 类型 Stream (Of a) mr 表示能够产生零个或多个 a 值、在 m 中执行效果并返回最终 r 结果类型的流。我们可以在 Stream 本身的定义中看到这些功能:这样的计算可以产生一个计算过的 Step,嵌入一个 monadic Effect,或者简单地返回一个纯值。 module Streaming where data Stream fmr = Step !(f ( Stream fmr)) -- 产生一个项目,以及一个流的其余部分,由函子 f | 定义。 Effect (m ( Stream fmr)) -- 执行一些导致进一步流的一元效应 | return r -- 什么都不做,返回一个最终值 作为 f 的值最常用的函子是 Of 函子,它与元组类型 (,) 相同,但它的左参数是严格的,再次避免了当我们知道所讨论的值已经被评估时,一个惰性值。
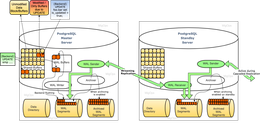
运行 Stream 的常用方法是调用 Streaming.toList,它返回一个 Of-pair,其中包含生成的 a 值和最终 r 的列表。请注意,Of 部分应用于流中,其参数 a 是流产生的元素类型。 toList :: Monad m => Stream ( Of a) mr -> m ( Of [a] r) 这里没有任何特定于字节串或 I/O 的内容,这意味着 Stream 适用于在任何 monad 中构建流抽象,而不仅仅是IO。相比之下,ByteStream 关心的是保存分块的 ByteString 值,而不是 Stream:模块 Streaming.ByteString 数据 ByteStream mr = Empty r |大块{-#解包#-}! ByteString ( ByteStream 先生) | Go (m ( ByteStream mr)) 您会注意到 ByteStream 与 Lazy.ByteString 相似,但有一些不同。首先,它可以访问两个类型变量 m 和 r:m 表示一个 monadic 上下文,使用 Go 构造函数,分块读取可以通过它执行副作用。这个 Go 构造函数也是新的;它明确表示,读取更多 ByteString 块会导致副作用,这与 Lazy.ByteString 不同,后者隐藏了从磁盘读取长字符串时可能发生文件 I/O 的事实。通过使用 MonadResource 清理文件句柄,我们可以使用类型系统指示从 ByteString 中读取 ByteString 值需要磁盘 I/O,并且必须清除文件句柄或临时数据的任何地方的 MonadResource 约束线程。最后,Empty 构造函数接受一个 r 参数,表示给定 ByteStream 计算的最终值(如果有)。 ByteStream 和懒惰的 ByteString 之间的区别可能看起来并不大,但它代表了 Haskell 非常深刻的一些东西:通常,我们通过将计算视为数据来获得表达能力。 ByteStream 有一个 Go 构造函数,它允许嵌入任意 m-actions,只要它们返回进一步的 ByteStream,这一事实使 ByteStream 能够表示任何类型的计算。在系统产生的 ByteStream 值的情况下,m 可以是 IO,或实现 MonadIO 的 monad 转换器,或实现 Lift IO 的效果堆栈。但是如果我们正在处理一个提前定义的 ByteStream,那么 m 可以是 Identity。一个有趣的结果是 ByteStream 的 Show 实例,它要求 m 参数为 Identity 并且 r 返回类型为 (),因为 Show 类型类无法访问打印输出所需的 monadic 上下文,例如,需要 IO 来执行其效果的 ByteStream。 (要打印这样的 ByteStream,您需要将它传递给类型为 MonadIO m => ByteStream mr -> mr 的 stdout 消除器,它会评估该流的效果并将在此过程中遇到的任何块打印到控制台。)此外, ByteStream 不仅仅是一个计算,它是一个 monad 转换器,根据一些父 monad m 进行参数化。这意味着我们可以以意想不到的方式使用它,例如我们快速而肮脏的 Web 服务器中的基本 monad:在这种情况下,在我们的效果堆栈中心有一个 ByteStream IO monad 使我们能够发送字节流使用 sendM 函数断开网络连接。我们将请求值的处理工作交给 Reader 效果,状态效果负责处理 Response 值,但是 HTTP 处理程序要执行任何有用的操作,它必须能够访问字节接收器。使用 Lift (ByteStream IO) 允许我们访问此类功能,而无需透露这些字节最终传输给用户的方式(我们只知道它发生在 IO 中,实际上所有网络活动都必须这样做)。
检查构造 ByteStream 值的方法使 ByteString、Stream 和 ByteStream 之间的关系更加清晰: -- 空 ByteString 可泛化为任何 m,但不携带任何值 -- 在其返回类型中。 empty :: ByteStream m() -- 当前程序的标准输入本身就是一个字节流, -- 使用'MonadIO'从输入的文件描述符中实际读取。 stdin :: MonadIO m => ByteStream m () -- 如果我们已经有一个严格的 ByteString,我们可以用 -- 'Chunk'(和一个 'Empty' 尾部)打包它。 fromStrict :: Strict.ByteString -> ByteStream m () -- 从懒惰的 ByteStream 转换为 ByteString 是 -- 折叠前者,替换 'Empty' 和 'Chunk' -- 构造函数与 ByteStream 提供的构造函数. fromLazy :: Lazy.ByteString -> ByteStream m () -- 一般而言,我们可以将 ByteStream 视为一种更有效的 -- 表示未分块的 Word8 值的流,或分块的严格 ByteString 值的流。请注意,这些保留了输入流的 -- 返回值。 pack :: Stream (Of Word8) mr -> ByteStream mr fromStream :: Stream (Of Strict.ByteString) mr -> ByteStream mr 更有趣的是基本的文件读取方法,readFile。有趣的是,这是我们第一次看到 MonadResource,一个由 resourcet 包提供的类型类。 MonadResource 类型类表示能够管理关键资源生命周期的 monad,即使在......