在创建世界上最大的图表数据库的幕后
每个论坛碎片包含9亿个关系和182百万个节点。该人员碎片包含30亿人和他们之间的160亿个关系。
“100台机器不酷。你知道什么很酷?一万亿的关系。“
我并不是说有人实际说出了这些确切的话语,但我很确定我们都认为他们。那是一个月前,当我们决定尝试并建立曾经存在的最大的图形数据库。
当我们推出Neo4J面料时,我们还创建了在FOSDem 2020呈现的概念基准证据。
它表明,对于1TB数据库,吞吐量和延迟随着它分布在的碎片数量而直线地改善。更多的碎片,更性能。
结果看起来很好,并确认我们对缩放图形数据库的方法非常了解。开发面料继续使其成为Neo4J的一个组成部分。
创建并改进了新技术(服务器端路由是一个很好的例子),也适用于非结构设置。
但是,来自FOSDEM的1TB数据集总是唠叨我们。 1TB至少是那么大,至少是Neo4J。我们经常具有10TB或更大的生产设置,虽然它们在大型机器上运行,但Neo4j展现得很好。
我们并没有真正需要解决方案;我们需要一个真正大数据库的解决方案。这就是我们创造了面料的原因,但我们还没有找到它的极限。
那个规模是什么?一年前,我们建造了40台机器的集群,他们效果很好。前往100台机器似乎没有挑战。数十亿个节点,也许?嗯,数十亿个节点与几TB数据相同。
此外,图形模式的丰富性来自节点之间的关系,而不是节点本身。记住:我们正试图看到我们可以推动neo4j,不仅让自己感觉或看起来不错。
每一个现在都会出现同样的讨论,并且变得明显,我们正在寻找一个机遇,一个避雷针,将我们在一个现实的目标。
事实证明,我们最大的在线开发人员会议,该机会是2021年6月17日的节点。
我们决定,我们需要向世界展示我们谈论规模时的意思。不仅仅是Neo4J水平缩放时可以保留甚至提高性能,但显示我们仍然可以在仍然保持性能时进行多远。
我们将需要更大的数字。需要注意的东西。不是数百台机器或数十亿节点。
你甚至在哪里找到一个带有万亿关系的数据库?使用生产设置将出现物流问题 - 数据传输本身将是复杂的,更不用说混淆数据,因此可以适合公共视图。我们需要从已知模型生成它。我们知道我们需要从数据模型开始,因为它会给我们机器的数量和大小,我们运行的查询,以及我们创建的测试。简而言之,从数据模型开始,以获得它需要的努力。
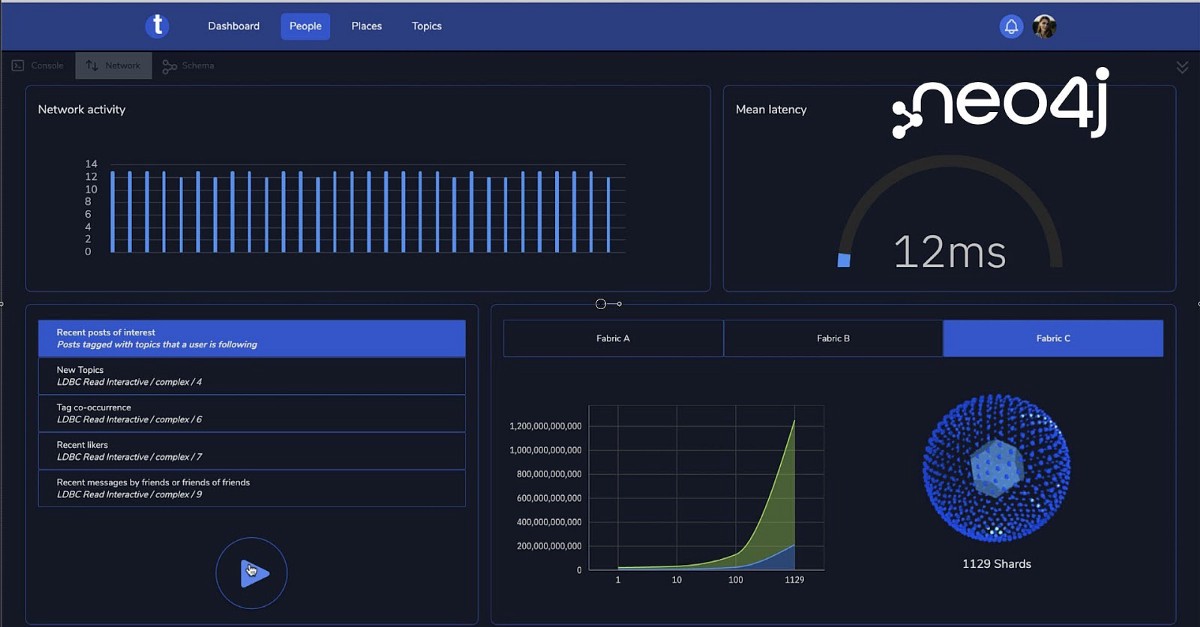
LDBC是一个很好的候选人。它是一个包含人,论坛和帖子的社交网络。它很容易理解和解释,我们非常熟悉它。我们决定了30亿人,超越了地球上最大的社交网络。选择了社交连接程度,以便该人员碎片将出现850GB,每个论坛碎片都会以250GB来到250GB,每个人都有约900万个关系。为了获得1万亿的关系,我们需要大约1110个论坛碎片,每个人都是自己的机器。
这是1110个论坛碎片,加上冗余的更多信息,每个都需要有一个为它生成的商店。
我们还想要连接到10,100和所有碎片的3个面料代理,以了解系统尺度如何随数据尺寸的增长。并且,随着时钟滴答作响,我们需要一个计划来协调所有这些机器。
这一切都是关于管理风险。我们预期,如果麻烦发现我们,它是在商店生成期间或在网络中严重发出故障的东西。事实证明,我们就是一半。
一个是举办碎片的大量机器。另一个正在生成碎片数据,我们知道需要并行发生,因此也需要协调大量机器。
我们需要一个两步的方法。第一步将是全尺寸的商店,而是少数NEO4J进程。这将让我们测试并行商店创建,发电机,从桶到分片的存储器,也测试延迟测量客户端的MVP。
它不会对我们的编排工具(以后来)对任何压力进行压力,并允许我们专注于为我们的概念证明正确地接线。事情很好地锻炼身体,我们都有所有的作品。一切似乎都在一起工作,现在我们可以屏住呼吸并获得第二阶段 - 全尺寸。
剩下两周后,我们搬到第二步:我们拔出了所有的挡块并支撑了影响。
提到的第一个问题是AWS实例配置开始在左右800台机器时不可预测地失败。一些侦探工作导致发现我们对我们的AWS帐户有一个vcore限制,这些账户没有让我们创建任何机器。 AWS支持迅速提升,我们继续创建实例只会达到更严重的限制:
“我们目前没有足够的x1e.4xlarge容量,具有支持”GP2“卷。我们的系统将致力于提供额外的容量。“
唔。看起来亚马逊缺乏容量。这让我们留下了两个选择。要么用于多个可用性区域或较小的实例类型。我们决定多AZ的复杂性和未知数,所以我们现在做了更小的实例,如果表现是一个问题,我们稍后会处理它。到达全部的实例是最重要的目标。
使用较小的实例执行了诀窍,第二天我们拥有1129个碎片的全部或跑步。延迟测量演示应用程序几乎准备就绪,因此我们决定拍摄一些测量以查看我们的立场。
完整的面料代理,指向所有1129个碎片的一个,是时机。 Neo4j日志文件没有任何相关的错误消息,只是超时。没有GC暂停,没有防火墙错位;常规嫌疑人都没有责备。每个单独的碎片正常响应,并且面料代理也没有显示任何问题。它花了一个晚上的调查工作,发现这个问题是DNS查询限制。随着AWS文件指出:
“亚马逊提供DNS服务器每秒每个弹性网络接口(ENI)执行每秒1024个数据包的限制。亚马逊提供DNS服务器拒绝超过此限制的任何流量。“
是的。这应该这样做。我们的Fabric配置正在使用碎片的DNS名称,因此我们在我们提交的每个查询上立即到达了该限制。解决方案非常简单 - 只需使DNS条目静态在结构实例上,不再依赖于DNS(/ etc / hosts ftw)。
这是我们必须克服的最后一个限制。我们的初始延迟编号看起来非常好,我们决定没有理由转移到更大的实例类型,这也有助于保持成本合理。
总的来说,我们在按一下按钮时,我们建立了允许我们的工具,以设置1129个碎片群托管280 TB数据,3小时内的3个面料代理。耶!它只需要16天到达那里。
我们剩下的时间清除配置和查询,并尝试延迟测量应用程序。我们还在图表本身上播放,创建了新的Ad-hoc查询,以获得使用如此大的设置。
我们不想创建一个纯粹的演示程序,因此我们决定通过使用万亿图表存储库尝试自己(在不同的尺度)上运行Setup(以不同的尺度)运行设置。记得要注意你的AWS账单♥!
这只是长途旅程的第一步。 我们有很多工作要做,以了解大图数据库的表现方式,网络变化如何聚合为噪音以及我们应该如何改进系统以超出我们为此演示所实现的数字。