使用CUDA加速康威的生活游戏
遍久前,在Nvidia的GPU技术会议(GTC)期间,我很幸运能够参加CUDA领先的一些开发人员的课程。在预期这些课程时,我决定创建自己的项目来工作,将使用GPU编程与CUDA。为此,我选择了创造康威的生命游戏(缩写CGL前进)。
为这种情况选择一个项目很棘手,因为我所希望的结果不是特定的产品/程序,而是对我来说是新的技术知识(CUDA)。此外,我需要该项目来达到几个标准。
它需要对我有趣(对在矩阵上发现随机数学方程的任何人没有冒犯)。
它必须具有一个简单的概念,可以在没有太多麻烦的情况下创建基本实现,因此我可以专注于将CUDA应用于它(也许下次射线跟踪)。
在浏览论坛和由导师发送给我的建议之后,我决定CGL适合所有标准,我开始起草我的大纲。
障碍物是棘手的,因为我有几个不同的想法,我需要选择。首先,我完全排除了一个无限的世界,因为处理潜在的无限数据不是我在这个项目中的目标。我发现我被认为是在两个选择之间决定,选项是制作一个循环世界(从Marek Fiser偷走的想法被偷走了,他们制作了一个非常相似的项目)或者只是使用固定大小的网格。在这两个选择中,我不得不再次提醒自己,该项目的重点需要在CUDA上,所以我采用了一个固定的大小,更容易实现,可以在头文件中轻松调整以测试不同数量的数据。
障碍物是关于哪些关于图形的文库的一些有趣的研究。当您谷歌“如何在C中实现图形时,大多数事情导致库”图形“。在尝试实施它并做一些更多的研究后,我得出结论,图书馆非常过时,我应该调查更好的选择。然后我的注意力转移到DepenGL和SDL之间。两个我决定使用SDL。虽然SDL比OpenGL更强大,但功率较少,速度越来越简单,而且由于我不试图为新的PS5构建图形,而我认为SDL仍然可以为我提供充足的。
在将任何逻辑放在一起进行实际程序之前,我想在我的屏幕上显示一些图形,以便我可以正确显示我的输出。如果我没有这样做,我只能查看输出的方法是尝试格式化一个大的2D数组来打印我的终端的标准输出(不乐趣)。
为了完全诚实地,为我的学习SDL最难的部分是如何安装它并获取“SDL2.h”标题以在我的代码中正确编译。这是我第一次安装第三方库并在编译中链接它,但经过一天的看法,“sdl2.h'没有找到这样的文件或目录,”我终于实现了成功的编译。
从那个点开始使用SDL,它是平稳的帆船,或者至少像我所希望的那样顺畅。当然,我仍然遇到了问题,但没有一件事挂给我过长的时间。
我最喜欢使用图形的一部分是每个成功感受的令人满意。从创建一个窗口来绘制该窗口中的网格以使其互动,每一步都感觉到自己的成就。
既然我有计划,了解如何使用图形我准备好实际创建该程序。
该程序的第一个实现旨在刚刚在CPU上运行,并在串行中展示网格的每个索引。为此,我设置了一个初始化的2D阵列,其将反映用户在交互窗口中的初始状态。一旦对启动状态满意,请在键盘上按“Enter”开始模拟,迭代并评估2D阵列的每个元素。基于其八个邻居评估网格中的每个单元,结果将在新阵列中存储为1或0,具体取决于它是否存在于下一个场景中。在此过程结束时,更新的数组与下一个场景应该如下填充。使用此更新的阵列和SDL,我更新可视显示以反映发生的更改。最后一步是交换更新和原始阵列,以便为下一个场景评估更新的阵列。
此时,我有什么我会考虑cgl的工作实施。我添加的最终触摸是一个计时器,以时钟程序执行所花费的时间和命令行提示选择运行时参数。包括选择是否在每个场景之间运行它(视觉上的延迟或在视觉上时钟)。一旦实施CUDA,该计划就是添加另一个选项来选择是否想要在CPU或GPU上运行代码。
类似于我的SDL初始经验,使用CUDA的大规模挑战只是让我的代码编译。 “布伦丹,听起来你从你花费SDL的所有时间学到了你的东西。”是的,我知道它的声音,但在你跳到那个结论之前,请给我一个机会解释自己(又名借口)。
建立CUDA与设置SDL非常不同,因为CUDA不仅仅是另一个我需要在编译中下载和链接的另一个C库,它是一个具有自己编译器的整个其他语言。当CUDA的编译器编译代码时,它使用以下路径转换:CUDA→C ++→对象文件。现在我们看看我们的C代码:C→对象文件的路径。我们留下了两种类型的对象文件,一些基于C代码以及基于C ++的一些 - 代码。这不是C代码调用C函数和C ++代码调用C ++函数的问题,但只要一个尝试调用另一个,就会出现错误,但仍然存在函数定义,尽管名称和原型不存在匹配。
使用名称列表('nm')linux命令(在我的导师上为他的导师提供帮助的巨大的shoutout),我可以看到c和c ++对象文件名称不同。由于在C ++中可以进行重载功能,因此对象文件提供有关导致它们在C对象文件中不匹配它们各自的定义的函数的更多信息。
一旦我理解发生了什么,谷歌答案就会变得更加容易,因为我知道要寻找什么。在太长之前,我找到了一个使用'extern'关键字的解决方案,强制C ++函数被称为C功能。一旦正确实施,我就可以成功编译并且可以开始优化工作。
在处理CUDA时,我在NVIDIA课程中从我的讲师那里了解到的提示是迭代地实施它。这意味着开始以最基本的实现,从那里修改它。您的CUDA代码可以瓶颈有多个地方,因此重要的是开始简单,并开始优化需要最优化的方面。如果你直接拍摄你认为是最佳的蝙蝠的最佳选择,这可能很困难。
对于我的第一个实现,我需要我的代码用以下顺序排队:
所有分配/复制步骤都是单行语句,可以在CUDA运行时API中找到。由于其参数,内核启动,虽然技术上只有一行,但它是更复杂的。通过额外的四个参数,它与我们的标准编程功能不同:
动态分配的共享内存的大小(我在这个项目中没有混淆这个))
在此实现中,我不担心动态内存和流,因此我省略了那些,只是填写网格和块尺寸。我的初始选择非常简单:网格高度=块数&网格宽度=每个块的线程。这样,我将恰好推出每个单元格的一个线程来评估(这不是CUDA如何工作,但现在让我们假装是)。此内核启动配置工作很大,直到我开始使用非常大的网格尺寸搞乱,这将导致尝试发射更多线程而不是可用的线程。
关于处理内存转移,使我更容易使用CUDA的托管内存,该内存利用统一内存来允许使用一个指针来访问GPU和CPU上的内存。托管内存的好处是编写代码的简单性,因为我不必在所有内存传输中明确写入。缺点是,如果让它运行自己的情况,我会在场景后面发生内存转移,我放弃了一些控制如何控制内存的实际管理(允许它是一个非常好的工作)。
在我认为基本实现完成之前,在代码上有两个最终修改。
在试图实现我的阵列时,我了解到,CUDA内核不会用2D阵列玩得很开心。这导致我必须通过我的所有代码并将其编辑它来平整2D阵列,并使用索引公式来转换(x,y)坐标和索引之间。
删除条件陈述是一种防止翘曲发散的技术。启动CUDA内核时,线程将分组为32个被称为WERPS的块。由于WARP中的所有线程需要执行相同的指令集,因此条件语句可能导致一个线程从其他线程“偏离”。如果一个线程与其他线程执行不同的动作,则所有其他线程待机,直到发散线程完成。这个废墟并行化,可以导致程序中不必要的放缓。
运行较小的数据集时,CPU的差异不太明显,因为通过存储器和设备之间的存储器传输,计算速度的改进是取消的。但是,在运行较大的数据集时,差异更加明显。
以下是使用类似于上述内容的CUDA实现来运行的代码的视觉分析。这在20,000×20,000个单元格网格上运行了20个迭代。您可以看到,与执行内存传输的时间相比,您可以看到在内核(薄蓝线)苍白的时间。在左侧的击穿中,GPU上的总时间的96.5%占据了内存转移。
此执行需要大约4.3秒,而运行相同数量的数据的CPU仅需100秒。尽管这比CPU上的串行实现速度快多次,但肯定会有改进的空间。
值得注意的是,我正在使用固态驱动器而不是计算机中的硬盘驱动器。如果我使用HDD跑了这个,我希望可伸出的内存转移能够显着增加时间。此时,由于我们正处于硬件主题,这里是我正在运行这个系统的系统。
我并不完全确定为什么它无法识别我的图形汽车,但我正在运行一个nvidia geforce gtx 1660tii。在程序上报告一对又一次图像,您也可以看到它在左侧面板上列出。
上面图片的代码中的明显瓶颈是内存转移,因此我的目标是进一步优化它们。为此,我希望解决标记在所有这些方面的“可粘性”方面。要了解这意味着什么,为什么它是重要的,以及如何改善它,我不得不做更多的研究。
当分配内存时,它并不总是存储在堆栈上。通常,当您分配内存时,它最终会在不同的存储设备上分配它,并使用堆栈“页面”以快速访问。
当从主机传输到设备时,如果需要分页该存储器,则需要路径:存储→堆叠→设备;而不是更直接的路径:堆栈→设备。必须引起数据的额外步骤可能导致性能显着下降。
为了优化此,我可以利用CUDA函数“CudamAlloChost()”,这将确保分配的内存被固定到堆栈,并且不必为每个传输分页。
要实现这一点,我必须重构一些代码来获取在原始CUDA功能外设置的固定内存。在找出如何正确使用它之后,我最终得到了如下所示。
显然,他们仍然比内核本身花更多的时间,但尽管如此,内存转移速度速度速度较快。这将程序的执行时间从大约4.3秒丢弃到2.8秒。此外,请注意,“可粘性”确认它已正确完成,内存副本不再注意到。
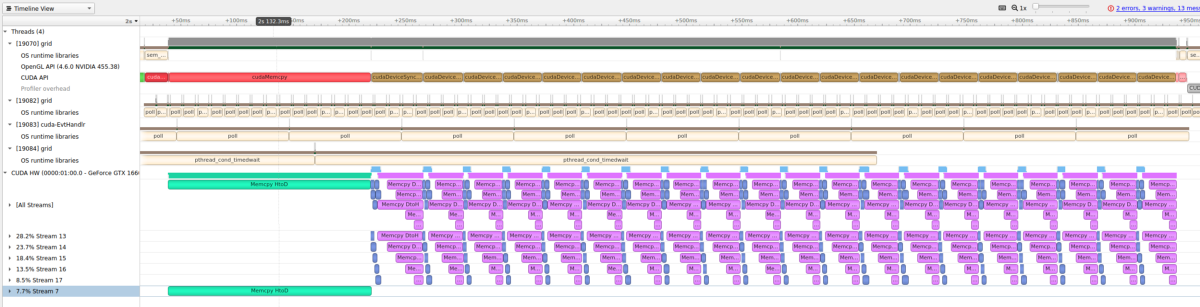
我最终的优化内存传输的想法是打破它们并使转移进行异步。例如,如果我将每个内存传输分成两个部分,我可以同时运行第一和第二半部分,从而将传输速度减半。要完成此操作,我需要学习使用流。在CUDA中,Streams基本上是多线程内核呼叫的方式。
要实现此目的,我创建了一系列Streams,并将数据数组划分为基于我的流的数量。然后我创建一个循环和每个流,我启动内核,每个内核都有一个不同的数据块。
CUDA的溪流很有趣,因为它们都可以同时执行,但它们并不能保证。因此,理想情况下,许多数据块将同时执行,同时提高计算的整体速度。但是,这仍然没有解决这么长时间的内存转移问题。
值得庆幸的是,CUDA提供了一个函数“cudamemcpyasync()”,它几乎与标准的“cudamemcpy()”几乎相同,除了它将流作为附加参数之外。这允许我在同样的方式重叠内存传输的时间内刚刚复制数据的特定块,同样地跟上内存。
另外,在调用所有流上的内存传输之后,需要同步流以确保在使用该程序前进之前的所有内存已经完成传输。 下面现在显示我的最终迭代,在我设法成功重叠内核计算和内存转移。 正如您所看到的,我已经推出了5个单独的流,这些流遇到重叠和大大提高性能。 此迭代我的代码在大约0.9秒内执行,显然比先前的任何东西快得多。



