使用Embeddings语义搜索:索引任何内容
我们生活在一个世界的爆炸中。有数百万件衣服,歌曲,电影,食谱,汽车,房屋,你应该选择哪一个?语义搜索可以找到任何品味和愿望的权利!
在本文中,我将介绍什么是语义搜索,可以用它构建的内容,以及如何构建它。例如,人们为什么要找衣服?他们喜欢品牌,颜色,形状或价格。所有这些方面都可用于找到最好的方面。
可以使用图像找到颜色和形状,并且在趋势中找到价格和品牌。
图像和趋势可以表示为名为Embeddings的小型矢量。 Embeddings是语义搜索的核心:一旦项目被编码为向量,它可以快速且有效地搜索最佳项目。
我将解释语义搜索如何工作:将项目编码为嵌入物,索引它们,并使用这些索引来快速搜索以构建语义系统。
千年来,人们想在文件中搜索:考虑包含数百万本书的巨大图书馆。然后可以通过作者姓名,出版日期,......仔细构建书籍的人们仔细地对这些书进行了解这些书籍,并且可以通过询问专家来找到书籍。
30年前,互联网变得流行,并与之搜索的文件数量从数百万到数十亿。这些文件每年从几千人到数千人的速度每天都有几千,并且不再可以用手索引一切。
这是建立有效的检索系统时。使用适当的数据结构可以自动索引数十亿个文档并以毫秒为单位查询。
搜索是关于满足信息需求。从使用任何形式的查询开始(问题,项目列表,图像,文本文档,......),搜索系统提供了相关项目的列表。古典搜索系统从文本,图像和上下文构建简单的表示,并建立要从中搜索的高效索引。一些描述符和技术包括
项目项目相似性是一种经典方法,可以使用评级和趋势找到类似的物品
虽然这些系统可以缩放到非常大的内容,但它们经常遭受困难来处理内容的含义并倾向于保持在表面水平。
这些经典检索技术为许多服务和应用提供了固体基础。但是,他们无法完全理解他们正在索引的内容,因此无法以相关方式回答一些文件。我们将在下一节中看到嵌入式如何提供帮助。
经典搜索和语义搜索之间的主要区别是使用小型向量来表示项目。
使用Embeddings功能强大:它可用于构建可以帮助用户使用多种查询中查找其喜欢的项目(音乐,产品,视频,食谱,......)的系统。它不仅可以在显式搜索系统中工作(在搜索栏中输入查询),还可以在隐式搜索系统中(零售商网站的相关产品,出版商的个性化新闻,社交平台上有趣的帖子)。
文本搜索系统作为输入文本查询和返回结果:搜索衣服,用于歌曲,新闻
视觉搜索系统用作输入图像并与此图片相比返回类似的项目。
推荐系统作为输入一些上下文,用户信息,并返回对给定目标的类似项目:推荐电影,汽车,房屋
社交网络,广告网络,专业搜索引擎(产品搜索)都使用检索技术来提供最佳信息
可以搜索各种项目,任何具有图片,文本,音频的项目,或者在上下文中可用。这种系统的热门例子是Google镜头,亚马逊推荐或新的时尚搜索,工厂搜索,...
在较小的规模上,它可以很有趣索引您的图片,您的消息,在许多人中找到电视节目,找到电视节目中的演员,...
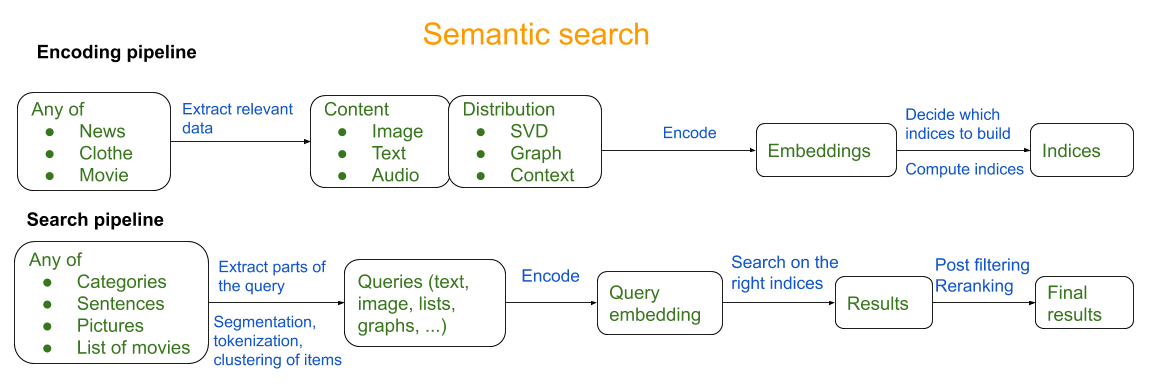
语义搜索系统由两部分组成:构建指标的编码管道,以及允许用户使用这些索引来搜索项目的搜索管道。
构建语义检索系统的第一步是将项目编码为小型矢量(数百个维度)。这对于许多项目是可能的,然后可以用于索引它们并有效地搜索它们。
检索系统可以编码来自许多不同方面的项目,因此考虑要编码的内容很重要。编码物品的一些例子是衣服,玩具,动物,新闻,歌曲,电影,食谱。每个人都有不同的特征:它们可以用它们的样子表示,如何描述它们,它们如何在其他物品中出现。
所有这些信息都可以作为嵌入式编码。要考虑的不同轴是编码多少项?所有项目都是独一无二的还是通过相关特征对它们进行更多意义?是否有一些更相关的物品并且应该是优先事项?尽早选择选择对系统的其余部分具有巨大的后果。
对于推荐系统,共同发生信息可能是最好的,但对于视觉搜索系统,图片可能是最相关的。
可以根据其内容进行编码项目。衣服可以很好地用图像表示。声音由其音频内容识别。可以使用他们的文本了解新闻。深入学习模型在制作具有良好检索性质的内容的表现时非常擅长。
图像可以用嵌入式表示(阅读我之前的博客中的介绍)。 Reset或AcheachNet等网络非常好的图像特征提取器,并且许多预先训练的网络都可用。
也不仅可以代表整个图像,而且在应用图像编码器之前也可以使用分段或对象检测。
分割可用于通过像素中提取图像像素的一部分,它可以与从时尚图片中提取衬衫和裤子相关
各种图像编码器的一个重要区别是它们使用的损失。卷积网络经常使用三重损失,交叉熵或最近的对比损失培训。每次损失都可以为嵌入提供不同的特征:三重损失和对比损失尝试将类似的物品放在一起,而交叉熵将放在同一类的物品。许多预先训练的模型在想象中培训,具有跨熵的图像分类,但自我监督的学习(SIMCLR BYOL)正在快速改变这一点,以便在没有分类的情况下进行无监督的培训。在不久的将来,最好的编码器可能不需要标记数据。来自CVPR2020的此视频教程非常适合于详细介绍图像检索。
能够将图像编码为向量,可以构建许多应用程序:可以看到和观看的任何东西都是可以编码的东西。时尚视觉搜索,工厂搜索,产品搜索都可以。在电影和其他视频内容中搜索也是可能的。
文本也可以用嵌入式表示。文字可以是各种形式和长度:单词,句子,文档。现代化的深度学习现在可以代表强大代表中的大多数人。
Word2VEC:编码单词是最受欢迎的嵌入式之一。从文字中的文字背景下,可以推断哪些词对他人的意义更接近。说明了Word2vec和Word2vec解释了概念和方法很好
变形金刚是一种较新的方法,可以通过更好地考虑句子中的许多单词之间的依赖性来编码整个句子。几年前,他们能够在许多任务中成为艺术的态度。所示的变压器是对它们的有趣介绍。
BERT架构:最后,BERT架构是一种特殊的变压器,可以在多任务设置中训练。它被称为Imageenet时刻的NLP。插图伯特是一个很好的介绍。
手套单词嵌入。这个小示例word-knn repo我构建可以帮助快速开始
句子嵌入的Labse模型是一个预先训练的BERT模型,可以在单个空间中从多达109种语言编码嵌入式
能够将文本编码为向量,可以搜索文章,电影描述,书籍标题,维基百科的段落,......许多内容可用作文本,因此使用该信息的信息可能是第一个步骤之一尝试。
超出文本和图像,音频内容也可以被编码为嵌入式(想想Shazam等应用程序)。 Jina示例和VectorHub在如何使用内容编码嵌入品的许多很好的例子
为了编码不仅是几百,但数十亿个嵌入式,批量工作(如Spark或Pyspark)可能会真正有帮助。大多数图像和文本模型将能够每秒编码数千个样本。在一小时内编码十亿个样本需要大约300个求助者。
通过它们的内容编码项目良好,并缩放到数十亿项。但内容不是唯一可用的数据,让我们看看如何编码其他项目。
衣服,电影和新闻等物品通常存在于许多用户访问的网站中。用户与物品相互作用,如或不喜欢它们,有些物品很受欢迎,只能通过用户的部分地看到一些物品,并且经常将相关的物品在一起。所有这一切都是互动数据。该交互数据可用于编码项目。这对于定义距离度量基于人们如何与这些项目交互的嵌入来特别有用,而无需任何关于其内容的信息。
在上下文中,当为一组项目(新闻,产品,餐馆,...)提供用户评分,可以计算用户和项目嵌入式。第一步是计算用户 - 项目相似性矩阵并使用矩阵分解(SVD),计算用户嵌入式和项目嵌入式。用户项目SVD是对此过程的简单介绍。
当可能观察物品之间的共同发生时,会出现另一个设置。一个例子可以是观看或由用户一起购买的产品(衣服,房屋,笔记本电脑)。这些共同出现可以用他们的PMI表示,并且可以将该项目矩阵与SVD中的eMbeddings。这两个博客帖子提供了一个很好的介绍。
由于有效的火花RSVD实现,SVD算法可以缩放到数十亿线和列的稀疏矩阵
这种方式将项目编码为嵌入式尤其强大,可以对用户偏好和用户行为进行编码,而不需要任何关于这些项目的知识。这意味着它可以跨语言和没有内容可用的物品工作。
许多数据集可以表示为图形。一个很好的例子是知识图表。例如,Wikidata和DBPedia例如在现实世界中作为人,公司,国家,电影,......以及它们之间的关系,如配偶,总统,国籍,演员。
这表像图表:实体是图中的节点,这些节点由边缘链接,即关系。
在图形嵌入和图形神经网络上有许多有趣的算法和最近的论文一般(这电报频道很好,遵循主题),但是一个简单且可扩展的一个是Pytorch大图。我用同事构建的这款辅助人可以帮助为PBG构建大图数据集,并查看一些KNN结果。
作为图表的这种数据表示可用于构建用于节点的嵌入品和用于边缘的转换,以便可以从一个节点到另一个节点。这个想法是学习如何使用两个节点嵌入品和边缘的学习转换来将节点映射到另一个节点。这种转变可以是翻译。这使得预测下一个边缘令人惊讶的良好结果。
Pytorch大图的贡献是分区节点和边沿,以便可以应用此学习数亿节点和数十亿边缘。
图表非常多功能,不仅可以代表知识图,还可以代表用户,产品,餐馆,电影之间的链接,...使用图形嵌入式可以是使用商品分发来对它们进行编码的好方法。
我们现在已经从各种角度嵌入了物品,并且他们可以提供互补信息。一件衣服看起来像是如何与之交互的,以及如何描述一切都是相关的。
连接:连接嵌入式是一种令人惊讶的基本方法。例如,连接文本和图像嵌入式使得可以使用其文本或两者搜索项目。
多模式模型:视觉和语言深入学习变得非常受欢迎,许多模型(ImageBert,Vilbert,Uniter,VL-BERT,请参阅这一有趣的演示)建议从两种语言和文本中学习,产生跨模型表示。
组成是一个强大的工具,可用于具有要编码的项目的完整视图。
在检索和推荐系统中考虑的重要主题是物品的普及。显示不受欢迎的项目通常会导致非相关结果。
解决此问题的简单方法是向嵌入添加一个受欢迎的术语。例如,最后一个组件可以是该项的视图的日志的倒数。这种方式在普及组件中具有0的查询之间的L2距离将排名第一是最流行的项目。这可能有助于从顶部结果中删除一些不受欢迎的物品,但由于必须手动设置相似性和人气之间的权衡,这并不完美。
要编码项目,预先训练的内容模型和基于分发的方法很好,但要为特定任务进行嵌入式,最好的方法是为此培训一个新型号。
许多任务可以被视为培训嵌入:基于内容,基于分布的,以及更具体的目标,如参与,点击,或甚至可以用户幸福。
图像嵌入式可以培训,其中包含分类,识别,分段等任务。 Groknet是一个大型系统的一个很好的例子,用于学习具有特定目标的图像嵌入物...它在许多不同的任务中了解许多不同的数据集。
Faceget是另一个培训超越分类的图像嵌入的简单方法。三重损失允许它学习特定类型的图像嵌入:面部嵌入。这可以重复使用培训熊嵌入的其他示例
BERT是一个模型的一个很好的例子,可以微调并为各种目标重复使用。特别是拥抱Face变换器库和句子变换器库基于它很好,可以为特定用例进行微调文本模型。数百种不同的变压器架构可以在那里有几十个训练设置。
另一个设置是建议的培训模型。这可以非常适用于超越SVD和火车产品和用户嵌入品。 Criteo Deepr库与伴随的Blogpost有很好的介绍。 Tensorflow推荐人是另一个好的入口点。
除了这些特定的培训设置之外,培训嵌入式是深度学习和代表学习的核心。它可以应用于许多环境和许多目标。一些有趣的例子是:
Starspace一个Facebook项目,以了解来自图像,文本,图形和分布的嵌入物,以获得各种目标
食谱嵌入项目的一个例子,用于从成分,说明和图像中学习食谱嵌入的配方嵌入
要更深入地进入培训神经网络的这一主题进行信息检索,因此来自ECIR2018的这些幻灯片非常完整。
建造嵌入后,我们需要一种快速查看它们的方法。这可以通过K最近邻算法实现这一点。它的简单版本包括计算一个向量和数据集的所有向量之间的距离。通过使用近似K最近的邻居算法可以大大提高这一点。
使用knn指数的正确实现,可以寻找从一组以毫秒为单位的向量嵌入的最近邻居。由于量化技术,这可以仅适用于几个GB的内存。
召回:在指数结果中发现了蛮力knn的有多少结果?
记忆:索引有多大,需要在RAM中保持多少内存?
在搜索相关性方面,将嵌入尺寸分区可能很重要。例如,物品可以通过广泛的类别(裤子,T恤,...)进行分区,以便适用于时尚视觉搜索应用程序。这种分区可能会在构建指标时产生后果,因此最好提前决定。
要选择构建指标的最佳方法,嵌入的数量是一个很好的鉴别者。
少于一百万,快速但不是记忆有效的算法(例如HNSW)是合适的
一个天真的KNN:可以用具有优先级队列或O(n)的O(nlog(k))实现,具有QuickSelect或Introselect。为了能够计算出来,需要将所有嵌入物存储在内存中。
HNSW:一种构建邻居图的算法。它是o(log(n))在搜索中,但不是精确的。嵌入式内存需要两倍,因为它需要存储图形
IVF:倒置文件算法包括将嵌入空间分成几个部分,并使用k均值找到嵌入式的近似值。它比HNSW更快,但它允许减少索引所需的内存尽可能多。
要了解有关所有索引的更多信息,我建议您阅读Faiss文档的此页面。来自CVPR2020的本教程深入了解这些算法,如果您有兴趣了解更精细的细节,我建议钟表。
Faiss是一个非常广泛的库,它实现了许多算法和清洁接口来构建它们并从中搜索它们
随着近似KNN的核心是现代检索的核心,它是一个活跃的研究领域。值得注意的是,这些最近的论文介绍了击败一些指标的新方法。
来自Google的扫描是一种新的方法,即最先进的方法,使用各向异性量化跳动HNSW和召回
来自Facebook的催化剂,建议用针对特定任务的神经网络训练量化器
我建议从Faiss开始实现灵活性,并尝试其他图书馆进行特定需求。
分片:沿着维度分区项目,可以将索引存储在不同的机器中
在速度方面缩放,索引的速度非常重要(像HNSW这样的算法可以帮助很多),但服务也至关重要。有关服务部分的更多详细信息。
实际上,只有15GB的RAM和延迟以毫秒为单位建立200米嵌入的指数。这将在单个服务器的等级中解锁廉价的检索系统。这也意味着在几百万枚嵌入的规模中,KNN指数只能适用于数百兆字节的内存,这可以适合桌面机器甚至移动设备。
数据库存在于各种:关系数据库,键/值存储,图形数据库,文档存储,...每种实现都有许多实现。这些数据库带来了方便和有效的方式来存储信息并查看它。这些数据库中的大多数提供了在网络上添加新信息并查询它的方法,并在许多语言中使用API。他们核心的这些数据库正在使用指数来制作
......