优化700 CPU远离生锈
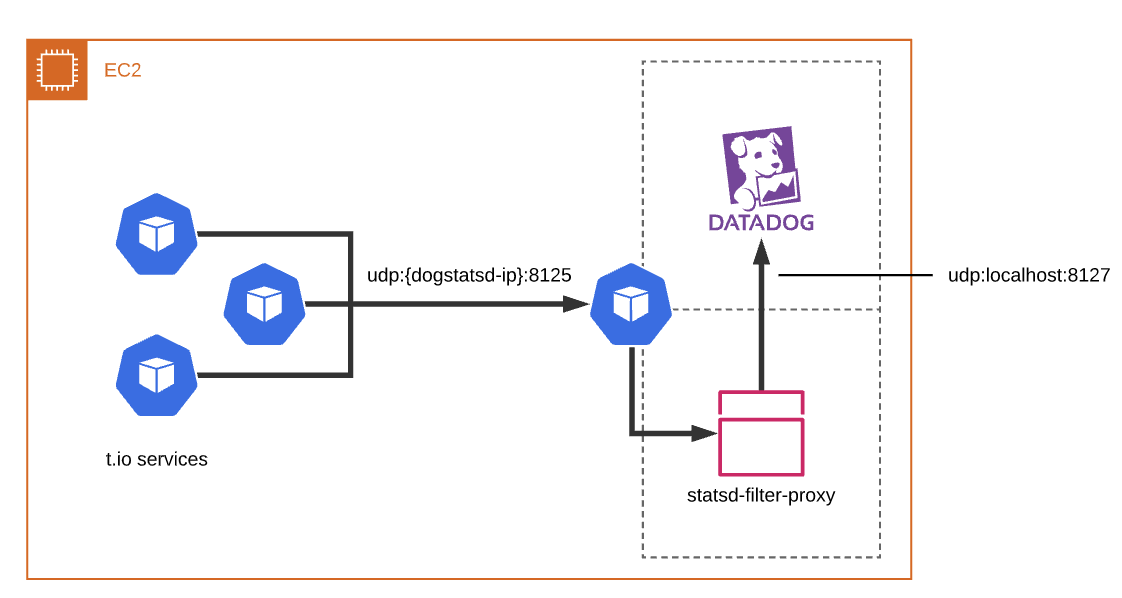
在Tenable.io中,我们是DataDog自定义指标的沉重用户。通过Dogstatsd发送数百万度量,在复杂的平台上提供深刻的见解。随着平台的增长,我们发现遗留应用程序发送的大量指标已过时。我们试图在Codebase中追捕这些已经过量的指标,但修改遗留应用程序非常耗时和危险。
要解决此问题,我们将一个Statsd Filter部署为DataDog代理Sidecar以过滤掉不必要的指标。过滤器是在Node.js中写入的简单UDP数据报转发器(示例,而不是实际代码)。我们选择了node.js因为在我们的环境中,其网络性能超越了其他语言,这些语言将其速度等于生产。我们能够在一周内在所有T.IO平台上实施,测试和部署此更改。
虽然这是多个月的工作,但绩效问题开始播出。由于平台继续扩大,我们通过过滤器发送越来越多的指标。在2021年的第一季度,我们增加了超过140万元的新指标,以提高我们的可观察性。过滤器需要更多CPU资源来跟上新的指标。在这种规模中,即使是轻微的低效率也会导致大量浪费。随着时间的推移,我们在这些过滤器上消耗了超过1000ccus和400gb的内存。开销已经变得不可接受。
我们分析了性能指标,并决定以更有效的语言重写过滤器。我们选择了RUDER以其高性能和安全特性。 (请参阅生锈评估的其他帖子)此处可提供新的基于RUST的过滤器的源代码。
基于RUST的滤波器比原始实现更有效。通过完全管理堆分配的能力,RUST的处理每个数据报的内存分配保持最小。这意味着基于RUST的过滤器只需要几MB的内存来操作。因此,我们的CPU使用率降低了75%,并且生产中的内存使用率降低了95%。
除了回收计算资源外,每个数据包的延迟还丢弃超过50%。虽然延迟不是此应用程序的关键性能指示符,但它有助于看到我们正在运行两倍,以便为资源的一小部分运行。
通过这种小变化,我们能够优化700多个CPU和300GB的内存。这一切都实施,测试和部署在单个冲刺(两周)。部署新过滤器后,我们能够确认DataDog指标的资源减少。