优化Rigelengine的OpenGL渲染为覆盆子PI
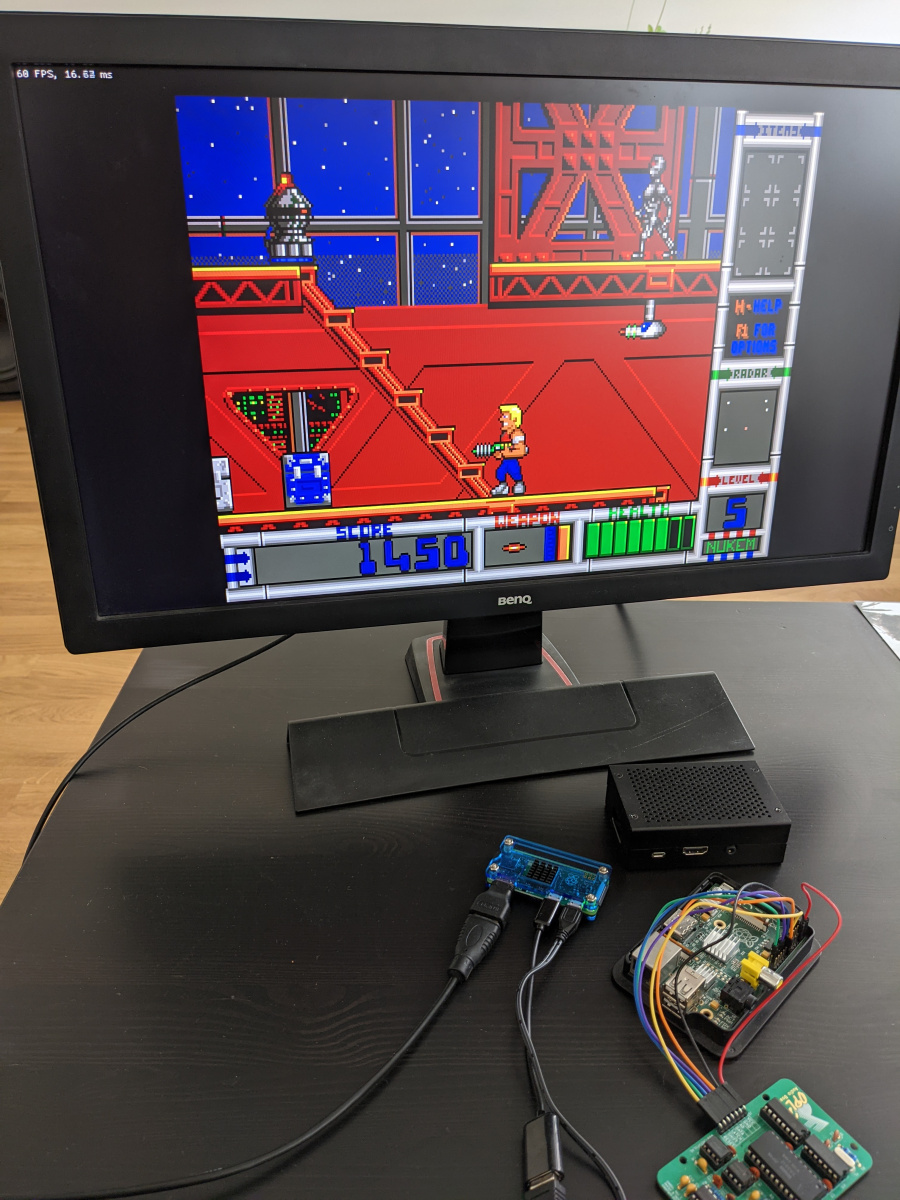
在研究Rigelengine的同时,性能主要是一个非问题。现代计算机如此强大,90年代初的2D游戏对它们没有匹配。当揭开帧速率时,我的游戏PC轻松超过3000 FPS在3000多件FPS上运行游戏,并且一名6岁的MacBook Pro仍然超过400 fps。但它在覆盆子pi上是一个不同的故事。当我第一次尝试在PI 3模型B上运行Rigelengine时,它在游戏中只在15到17个FPS上管理。经过一轮优化后,它现在在PI 3和PI零上以1080p分辨率在稳定的60 fps(V-sync开启)上运行。在本文中,我将通过优化过程,并描述绩效差异的变化。由于该项目是开源的,因此您将找到与所有相关代码更改的链接。
首先,让我们来看看游戏中典型场景的复杂程度。这样,我们有一帧我们要求硬件的参考。乍一看,这古老的游戏似乎奇怪的是,即使对于像覆盆子Pi这样的东西,这也会挑战任何挑战。原始跑车在低于兆字节的RAM和CPU速度的机器上,在25至66 MHz的范围内。而PI比现代低端游戏PC相比,PI比这更强大。但Rigelengine渲染其图形的方式与最初工作的方式非常不同,即使视觉输出实际看起来也是一样的。游戏使用GPU进行渲染,通过OpenGL(3.0或2.0 es)。
在PI上,我正在使用GL es与专有的Broadcom驱动程序(AKA遗留驱动程序),没有X服务器运行。我发现这使得与KMS或FKMS驱动程序相比,这使我最好的性能。我应该注意,我没有在没有X11的情况下使用KMS测试的,所以我不知道这与遗留驱动程序有何比较。
在游戏中,有几个元素构成了现场:视差背景层,瓷砖,精灵,粒子效果和HUD。瓷砖和精灵进一步分为背景和前景层。
除了使用gl_points原始呈现的粒子效果,所有这些元素都使用gl_triangles和索引缓冲区绘制为纹理Quad。我的渲染器自动组合(批量)绘制使用相同纹理的请求,以减少绘制呼叫的数量。所有纹理都绘制了GL_NEAREST过滤。
Rigelengine以解决操作系统报告的任何解决方案运行,这通常是监视器的本机分辨率,除非另有配置。所以在我的情况下是1080p。但实际渲染的内容仅为1440×1080,匹配原稿的4:3宽高比(除非启用宽屏模式,在这种情况下使用整个屏幕)。
原始游戏以320×200的分辨率耗尽,哪个(尽管16:10通常)在CRT监视器上显示为4:3(监视器水平伸展图像,导致非方形像素)。纹理的尺寸很小。许多精灵约24×24或32×32像素。背景图像为320×200,TiXEET为320×240。包含字体的精灵片和HUD的许多UI元素也是320×200。
在呈现的基元方面,工作负载可以从低至340三角形的范围,到超过1500个三角形加500点。最大的三角形来自渲染瓷砖:在繁忙场景中可能有680和710块瓷砖。繁忙场景中的Sprite计数可能大约20个或更多,但一个简单的场景可能只有一个精灵。
要以这种方式提出这一点,1500大约与三个人形字符或从半衰期1的单个大敌人大致相同的三角形,或者从半衰期的半衰期2.甚至可以有超过2000年在一个场景中的三角形。整体而言,工作量似乎非常合理 - 最初是如此慢?
我没有使用任何专用的分析工具。我的方法是建立一个易于重复的基准,给了我一个帧时间测量,然后进行实验。我可能会在将来获得性能数据的工具,但对于这一轮的优化,基准驱动的方法很棒。
作为侧面笔记,我强烈推荐使用帧时间(连续帧之间的增量时间)而不是FPS优化时:前者可以轻松比较两个不同的值。无论基线性能如何,5ms的增益总是相同。另一方面,“20 FPS更快”意味着根据基线的不同事物。从20个FPS改进到40表示我们将渲染时间降低25毫秒,但从200 fps到220的改善只是0.5毫秒的减少。
对于基准测试,我使游戏将直接加载到第一级,运行渲染循环,并收集帧时间几秒钟,然后自动退出并打印出平均帧时间。这样,很容易在代码中进行更改,看看它是如何影响帧时间的。在基准期间没有给出用户输入,以便保持工作量一致。
尝试这种方式,我能够相对迅速地磨练瓶颈。它仍然花了一些时间(并在论坛发布中询问一个问题)真正了解为什么有些事情很慢 - 我最初发现它很难相信PI在1080P时遭受这种看似简单的工作量。但发现慢零件相当容易。最后,它归结为两个相当大的问题,占大量放缓的问题,加上一对较小的优化,以帮助特别是PI Zero和PI 1型号B等较弱的PI。
在我们进入瓶颈是什么之前,一些上下文:我在电台上开始的平均帧时间为65ms,这对应于15 fps。为了达到60个FPS(16ms),我必须找到一种方法来减少至少49ms。现在让我们看一下我发现的第一个改进。
Warning: Can only detect less than 5000 characters
我们刚才描述的所有内容都呈现为另一个纹理,然后在屏幕上绘制最终顶级渲染目标。
这是一个多通行渲染设置:事物不直接呈现为帧缓冲区,但进入中间缓冲区(渲染目标)。然后,需要在单独的步骤中将顶级缓冲区绘制到帧缓冲区上。正如我们刚才学识渊博的那样,由于对内存带宽的需求增加,这并不适用于基于瓷砖的架构。会发生什么是GPU使渲染目标的东西呈现一些东西,并将中间缓冲区写入主内存(切片到瓷砖)。然后它必须将数据加载回片片内存中,做更多的处理,最后将其写回主内存。这意味着每个渲染目标导致额外的往返到主要内存,这些内存进入我们的带宽。使用1080p渲染目标,我们需要近1 GB / s的额外带宽,以便在我们已经需要写出最终帧缓冲区的顶部。这是一个巨大的差异!当直接渲染到1080p渲染目标Vs渲染时,我在帧间时间测量大约8ms的开销。如果我们想达到60个FP,我们只有16毫秒的每帧总时间预算。一旦我们有两个1080p渲染目标,它就变得完全不可行,以便以60 fps运行。
我们可以没有所有这些渲染目标吗?理论上是,但需要相当重大重新准备代码。我可以将粒子效应呈现为小型矩形,这将避免需要“低分辨率层”渲染目标。独自改变不会那么糟糕。但摆脱顶级渲染目标更难。而且我不知道如何避免水效应缓冲,短暂禁用效果。
为什么难以摆脱顶级渲染目标?我正在使用它来实现屏幕淡化的效果。每当游戏在场景之间过渡时,它就会快速淡出和屏幕上的效果。通过渲染目标,我可以通过用缩小/增加的alpha绘制纹理来轻松实现这一点(侧面注意:通过修改VGA颜色调色板逐渐消退)。通过在场景顶部绘制黑色矩形,然后增加/减少其alpha,可以在没有渲染目标的情况下实现相同的效果。但是改变我的代码来褪色,那种方式是很多工作。使用渲染目标进行渲染目标简化了大量代码,因为渲染目标捕获了游戏呈现的任何何种代码。这意味着我可以在不需要连续重新渲染游戏的情况下进行淡出,因此游戏代码甚至不需要意识到衰落。如果我想切换到其他方法,我需要更改代码中的大量地点以使其工作,并做大量的测试,以确保所有可能的转换都正常工作。
因此,我决定保持渲染目标,但使它们更小。而不是像帧缓冲一样大,水效应缓冲区和顶级目标现在是320×200。以前,每个单独的瓷砖,精灵等单独缩放,但现在一切都以1到1级渲染,并且只有渲染目标延伸到最后的目标大小。因此,我现在可以摆脱低分辨率层和雷达缓冲区,节省更多带宽。
现在你可能会问,为什么我首先使用1080p渲染目标,如果游戏的艺术目标只有320×200?为什么要通过低分辨率层等遇到所有麻烦,新设置似乎更简单?答案是我计划在将来能够使用更高分辨率的精灵/瓷砖模式。并且对于这些实际上出现Hi-Res,每个元素都需要单独升级,因为可能有一个原始艺术品和高分辨率替代品。因此,我已经将更复杂的Up-Scaling系统置于预期在未来添加修改支持,而不知道对像PI这样的弱势设备上的性能影响。
高分辨率代码路径实际上仍然存在,它只是不再是默认值。这意味着我们对PI进行了良好的性能,但一旦我增加支持,我们就可以利用高分辨率艺术品。幸运的是,由于我归档渲染管道的方式,这种变化是可能的,而无需触摸太多的代码。对于大多数渲染代码,它不会有所不同,坐标系是否由渲染目标的大小或通过视口转换来定义 - 它总是假设它绘制到320×200“屏幕”,而且并不是'请关心升起的缩放如何发生。
引入低分辨率代码路径给出了另一种非常显着的提升。帧时间在正常场景中提高12毫秒,何时可见时25毫秒!这与精灵渲染的改进相结合了已经提高了性能,但是有几个较小的胜利胜利。
大多数游戏的图形包括直接的位图绘图,但有一些颜色修改效果:当敌人和其他物体受到伤害时,它们会短暂闪烁白色。
在菜单中绘制文本时会发生另一种颜色修改。底层字体纹理是白色的,然后调制以出现在不同的颜色以指示所选菜单项,或者注意某些菜单项。
使用着色器实现这两种效果。最初,我制作了一个可以绘制常规纹理的单个着色器,并选择应用这些效果:
这种灵活性在PI的GPU上没有免费提供。由于大多数对象不使用这些效果,因此我创建了一个额外的“简单”着色器,并添加了一些代码以动态切换着色器,具体取决于当前是否启用了效果。这使得我在帧间时间内推动了3毫秒,这与始终保持60个,但仍然需要保持60个FPS(例如,当水效应是可见的)。这是简单的着色器:
请参阅代码更改 - 但请注意,渲染代码在此期间更改了很多。
我做过的另一个优化,它有助于低规格PI,涉及将更少的数据发送到GPU / OpenGL。更具体地说,我最初使用以下代码来呈现批量纹理的四边形:
这是每批处理提交顶点和索引数据。在优化时,我意识到索引数据实际上是相同的 - 它只是改变的顶点位置。所以我制作了一个只有一个只提交到OpenGL的大型索引缓冲区,批量提交代码变为:
每个索引是两个字节,我们需要6个索引来绘制一个四边形(两个三角形)。当绘制700瓦片时,这意味着我们节省了8 kB的数据。在PI 1模型B上通过6ms改进了帧间时间。
游戏现在在PI 3和PI ZERO上以稳定的锁定60 fps运行,但它在PI 1型号B上并不是那么达到50 fps。通过将分辨率降低到720p,或将CPU和GPU超频分别将CPU和GPU超频分别(库存设置为700 MHz和250 MHz),仍然可以达到60 FPS。值得注意的是,PI Zero归零的CPU和GPU作为PI 1,但框中的更高时钟(1 GHz和400 MHz)。
因此,我决定不在现在进入PI 1的时间。毕竟,PI零更便宜并运行游戏而不会开箱即用问题,并且可以将PI 1超频到与零(并且可能是安全的,给出它是相同的硬件)。我可能仍然在某个时候回到它,看看我是否可以将其推过边缘 - 但目前没有具体的计划。
因此,即可为覆盆子PI看看OpenGL性能优化。这两个最大的胜利是由于引入精灵的纹理图集,并使用更小的(且更少)渲染目标来减少所需的带宽量。 Shader Simplification和重用单个索引缓冲区,用于多个绘图呼叫也有帮助。全部优化
......