版本控制数据管道:Metaflow和Dolt
这篇文章详情如何使用Metaflow与DOLT。 Metaflow是定义数据科学和数据工程工作流程的框架,其中能够定义本地实验并将这些实验从单个API进行生产作业。 DOLT是一个版本控制的关系数据库。它提供了熟悉的SQL接口以及类似Git的版本控制功能。每个提交都对应于创建提交时数据库的状态。 DOLT和METAFLOW都是开源的。
我们展示了如何使用DOLT和METAFLOW的CO MB,以解决现代数据科学和数据工程项目和架构中的三种共同挑战:
再现性:如何确保我们可以始终如一地重复过去的结果,并逐步改进结果。纪律主题的科学和工程要求守门员不会意外地转移,例如由于输入数据的变化。实验跟踪:如何跟踪执行所有更改和实验。今天,很难想象没有像Git的版本控制的软件开发,数据科学需要一个类似的工具来保持组织。谱系和审计:最后,当我们的系统在生产中,我们希望了解有助于系统输出的确切模型和输入数据,例如预测。当结果令人惊讶时,这尤其重要,我们需要了解原因。
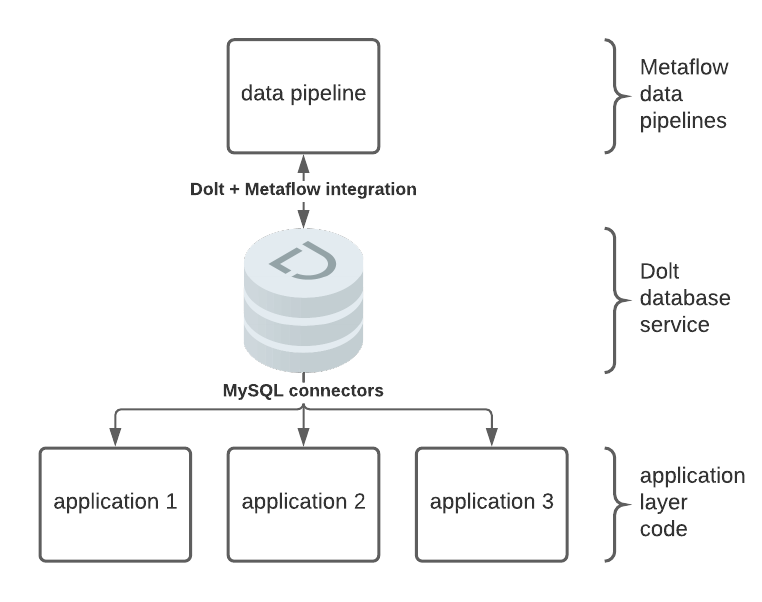
DOLT和METAFLOW都是在强大版本控制的思想之外构建的:Dolt版本数据和Metaflow版本代码,执行环境和执行状态。为了说明MetaFlow和Dolt如何一起解决这些挑战,我们使用示例元流量管线来派生输入数据集的结果。我们将输入数据读到Pandas DataFrame中,并将该Dataframe转换为Dolt中的永久存储,以与具有中间步骤的应用层服务一起使用。 Dolt SQL Server可用于通过MySQL连接器提供此版本化和可重复的数据,进入基础架构的其他部分。
我们的管道由两个流动组成。一个流量消耗由另一个的结果。第一个流量计算医院手术的国家级中位数。第二流量计算跨州的过程的价格方差。对于输入数据,我们选择了使用Dolthub数据赏金创建的1400个美国医院价格的新公共数据集。我们的管道看起来像下面的示意图。
我们将使用最终结果来说明Dolt和Metaflow如何为Metaflow用户提供遍历其最终数据版本的能力,以及通过管道进行回溯以检查各个阶段。用户可以通过MetaFlow API和Dolt Integration在熟悉的环境中这样做,如控制台或笔记本。
示例流水线的所有代码都是开源,可以在Dolt-Integrations Github存储库中找到。
我们的设计目标具有这种集成,是直接从Metaflow提供Metaflow用户额外的功能。我们希望尽量减少额外的API表面积。
Metaflow中的工作流称为“流动”。每个流程存储关于流量执行的元数据,称为“运行”。每次运行与DOLT交互时,我们都会捕获少量元数据以使该交互再现。我们在Metaflow运行和DOLT提交之间创建映射,为用户提供强大的素线和再现性功能。
运行的各个步骤可以创建单独的提交,以后写入写入后的数据库状态。
当流程从DOLT读取数据时,它记录了在MetaFlow内部读取数据的准确。当流程写入致命时,它会创建提交并捕获相关元数据,以及格式化提交消息。这允许用户直接浏览它们流量的流量的输入和输出,而无需了解大多数关于DOLT的任何内容。此外,用户可以检索最后从给定分支或提交的表的流程,也可以直接从MetaFlow API进行提交。
这一切都是抽象的,所以让我们安装一些依赖项,抓住一个数据集,并陷入运行我们的管道。
让我们离开乏味的东西。我们需要以下内容:
- 安装了Dolt和Dolt-Integrations - 安装了Metaflow - 我们将使用的示例数据集,这可以轻松从Dolthub克隆
接下来让我们安装MetaFlow + Dolt集成。它与MetaFlow和Dolt的Python Cli包装器一起包装,Doltcli。通过PIP安装很容易:
最后一步是获取数据集。调用DOLT是一个带有类似GIT版本控制功能的SQL数据库,它可以克隆远程数据库到本地计算机。我们可以使用该功能来轻松获取DOLT数据库:
注意此数据集是近20千兆字节,可能需要几分钟才能克隆。一旦它降落到SQL即将跳转到SQL,这是直接的:
$ dolt sql#欢迎来到Doltsql shell。 #语句必须终止&#39 ;;' #"退出"或" quit" (或Ctrl-D)退出。 hospital_price_transparency>显示表; + ----------- + |表| + ----------- + | cpt_hcpcs | |医院| |价格| + ----------- +
在我们进入详细信息之前,让我们首先在最新版本的上游数据库中产生我们的管道运行。第一个流量在州级计算给定医院手术的中位数:
$诗歌运行python3 hospital_procedure_price_state_medians.py run \ --hosital-price-db路径/到/医院 - 价格 - 透明度\ --hoSital-price-price-dub路径/到/医院 - 价格分析metaflow 2.2.8执行医院PriceStatemedians对于用户:oscarbatori验证您的流程......图表看起来不错! 2021-04-07 08:50:36.934工作流程开始(Run-ID 1617810636925188):2021-04-07 08:50:36.941 [16178106369251818 / start / 1(PID 21075)]任务是启动。 2021-04-07 09:02:36.095 [161781063692518188 / Start / 1(PID 21075)]任务成功完成。 2021-04-07 09:02:36.136 [1617810636925188 /端/ 2(PID 21257)]任务开始。 2021-04-07 09:02:37.697 [1617810636925188 / END / 2(PID 21257)]任务成功完成。 2021-04-07 09:02:37.698完成!
$诗歌运行python3 hospital_procedure_price_variance_by_state.py run \ --hosital-price-anysis-db路径/到/医院 - 价格分析metaflow 2.2.8执行HospactProcedurepricevarianceByState for User:OSCArbatori验证您的流程......图表看起来很好! 2021-04-07 09:07:25.262工作流程开始(Run-ID 16178116452555563):2021-04-07 09:07:25.269 [16178116452659 [1617811645255563 / start / 1(PID 21299)]任务是启动。 2021-04-07 09:08:25.200 [16178116452555563 /端/ 2(PID 21349)]任务开始。 2021-04-07 09:08:25.982 [16178116452555563 / END / 2(PID 21349)]任务成功完成。 2021-04-07 09:08:25.983完成!
我们现在拥有我们的第一个结果集。让我们通过集成来访问计算的差异,使用流作为入口点。您可以使用命令行或笔记本中的Python解释器执行以下代码段和后续示例。 Snippet使用Metaflow的客户端API访问过去运行的结果:
代码价格0CPT®86708,72253.125 1CPT®86708,73253.125 2CPT®86708,74253.125 3CPT®86708,45253.1254CPT®86708,762545376695 NaN,7 779888.100 1176697 NaN,8 215298.800 1176698 Nan,9 4031522.000 [1176699行]
我们已经看到运行我们的管道相对简单,并通过引用生产它们的流程来访问我们的版本化的结果。我们现在潜入其中一些功能,这提供了选择在数据基础架构中使用DOLT的Metaflow用户。
在此示例中,我们的输入数据集存储在DOLT中。我们使用了一个Dolthub数据集,因为它很容易克隆数据集并开始入门,并且毕竟这是关于将Dolt与Metaflow集成。但是,在DOLT中拥有我们的输入数据集只是这篇文章的便利性。因为每个Dolt提交都代表了一个时间点的数据库的完整状态,所以我们可以轻松地将管道指向数据的历史版本。让我们检查DOLT提交图表并从SQL控制台直接抓取提交:
$ cd路径/到/医院 - 价格 - 透明度$ dolt sql#欢迎来到Doltsql shell。 #语句必须终止&#39 ;;' #"退出"或" quit" (或Ctrl-D)退出。 hospital_price_transparency>选择commit_hash,来自dolt_comits的消息,其中`日期` ' 2021-02-17'按“日期”DESC限制10; + ----------------------------------------- ---------------------------------------- + | commit_hash |消息| + ----------------------------------------- ---------------------------------------- + | f0lecmblor67rcuhuti6tbkrigh6gt |从UWMC_PRICES.csv的更新价格更新价格| | mj9ce6d8em9avj9ej0pqnaoes4fbglti |更新CPT_HCPC与UWMC_CPT_HCPCS.csv |更改| 2j6ommult20qvbj05j1nq63nkbd5fgdj |更新价格随房屋的变化.CSV | | pu8ctvhfcppp83q3iil8trp90vnuesaci |使用CPT_HCPCS.csv的更改更新CPT_HCPC | | Q49L0KGNBBBGKT3IMJD57TSLBI2IGES8 |使用Hospitals.csv的更改更新医院| | gstcq5loi9ieqdv1elrljab9hcgr090p |使用Hospitals.csv的更改更新医院| | TE6SPCQTJK0SCOSE2C45F9T7TPCRT69C |添加医院Wellspan外科&康复医院。 | | bjg3b5lua8omadcl5nr6o7v0nphliqpu |加入医院Wellspan York医院。 | | t4js1g5mfvgikqlmqa238it26mg94g5i | Alabama的医院儿童添加了医院儿童。 | | jsan7p4iad61cjmeti858ebcl4s86vda |添加了医院毛明酸盐区域。 | + ----------------------------------------- ---------------------------------------------
假设我们希望使用Commit Gstcq5loi9ieqdv1elrljab9hcgr090p的输入数据运行我们的管道,这是第一个标记的医院更新医院.CSV的更改。这很容易,首先让我们用分支命名提交:
在重新计算中位数之前,让我们在与root提交的医院 - 价格分析数据库中创建一个分支,以存储这些实验:
现在让我们开始重新计算中位数。由于我们从原始定价数据的历史版本重新计算我们的中位数,我们将把它们写入单独的实验分支:
$诗歌运行python3 hospital_procedure_price_state_medians.py run \ --hosital-price-db路径/到/医院 - 价格 - 透明度\ --hosital-price-db-branch metaflow-backtest \ --hosital-price-sigent-db路径/到/医院 - 价格分析\ - HOSPITITITIAL-PRESITIO-DB-BRONG METAFLOW-BROWTEST METAFLOW 2.2.8执行HARMADYPRICESTATEMEDIANS for User:OSCARBatori验证您的流程......图表看起来很好! 2021-04-07 09:20:00.883工作流程开始(Run-ID 1617812400875290):2021-04-07 09:20:00.889 [1617812400875290 / start / 1(PID 21700)]任务开始。 2021-04-07 09:20:20.254 [1617812400875290 / Start / 1(PID 21700)]任务成功完成。 2021-04-07 09:20:20.264 [1617812400875290 /端/ 2(PID 21776)]任务开始。 2021-04-07 09:20:21.422 [1617812400875290 /端/ 2(PID 21776)]任务成功完成。 2021-04-07 09:20:21.423完成!
$诗歌运行python3 hospital_procedure_price_variance_by_state.py run \ --hosital-price-project-db路径/到/医院 - 价格分析\ --hosital-price-price-price-db-branch metaflow-backtest metaflow 2.2.8为用户执行HospitalProcedurePriseByState :Oscarbatori验证你的流程......图表看起来不错! 2021-04-07 09:21:12.296工作流程开始(运行ID 1617812472287058):2021-04-07 09:21:12.303 [1617812472287058 / start / 1(PID 21827)]任务是启动。 2021-04-07 09:21:16.321 [1617812472287058 /端/ 2(PID 21871)]任务开始。 2021-04-07 09:21:17.283 [1617812472287058 /端/ 2(PID 21871)]任务成功完成。 2021-04-07 09:21:17.284完成!
由于此提交所采取的数据收集过程中的较早,我们可以看到唯一的独特程序代码,21k Vs 1.17M:
代码价格0 0001A 184.03088 1 0001M 12250.82000 2 0001U 35871.70000 3 0002A 275.67660 4 0002M 0.00000 ...... 21332 L1830-00 13.41620 21333 L1830-01 9.24500 21334 L1830-02 20.22480 21335 L1830-03 247.53125 21336 L1830-04 35.70125 [21337行x 2列]
或者我们可以使用Dolt SQL的语法来查询我们的Extreapt的结果:
$ CD路径/到/医院 - 价格 - 分析$ DOLT SQL#欢迎来到Doltsql shell。 #语句必须终止&#39 ;;' #"退出"或" quit" (或Ctrl-D)退出。 hospital_price_analysis>选择* from variance_by_procedure' metaflow-backtest'订购价格DESC限制10; + ------- + -------------- + |代码|价格| + ------- + -------------- + | Q2042 | 5.9482256E + 11 | | Q2041 | 5.1718203E + 11 | | 216 | 1.2761694E + 11 | | J3399 | 9.192812E + 10 | | Q4142 | 1.604416E + 10 | | 0100T | 1.4931476E + 10 | | C9293 | 9.202785E + 09 | | 47133 | 8.558203E + 09 | | 90288 | 8.4152607E + 09 | | J7311 | 8.2143995E + 09 | + ------- + -------------- +
在本节中,我们看到了DOLT中的存储流量输入是如何再次测试的。这是通过Easy Dolt的COMMIT图表使其成为用户的历史版本来实现这一点。
我们的管道包含两个步骤,一个计算状态程序价格中位数,第二个计算跨州的程序价格差异。现在假设我们想调整我们计算差异的方式。我们可能想排除一些异常值或无效的程序代码。在生产环境中,我们可能拥有差异计算,而不是中位数计算,并且具有更严格的标准,用于排除无效数据。让我们更新variances作业,然后使用更新的流定义重新计算。
我们使用该路径作为Doltdt的参数,这又导致Doltdt以与所提供的运行路径指定的运行完全相同的方式读取数据:
回顾我们第一次运行计算中位数的流量,运行ID为1617810636925188.我们也可以在DOLT中看到它:
Dolt log commit lmjqpf293qg9ma10r034htt7jhfu5c4f作者:oscarbatori< [email protected]& gt;日期:4月07日星期三09:08:24 -0700 2021 run:hospital procedurepricevariancebystate / 1617811645255563 / start / 1 commit 3je2okkrig5h3dbmufuf8bhmfq0okps3lg作者:oscarbatori< [email protected]& gt;日期:4月07日星期三09:02:21 -0700 2021运行:HospanitalPriceStatemedians / 1617810636925188 / Start / 1
让我们创建一个分支固定在我们想要重现的提交中:
我们可以直接将此分支直接传递给我们的作业,以实现所需的数据读取隔离以进行测试,以便测试我们的代码更改:
$诗歌运行python3 hospital_procedure_price_variance_by_state.py run \ --hosital-price-anysis-db〜/ document / dolt-dbs / hospital-price-price-price-price-anysis-db-branch metaflow-change metaflow 2.2.8执行HosparalProcedurePriceVarianceByState for User:OscarBatori验证您的流程......图表看起来不错! 2021-04-07 15:11:15.634工作流程开始(Run-ID 1617833475626845):2021-04-07 15:11:15.641 [1617833475626845 / start / 1(PID 42039)]任务是启动。 2021-04-07 15:12:17.799 [1617833475626845 / start / 1(PID 42039)]任务成功完成。 2021-04-07 15:12:17.808 [1617833475626845 /端/ 2(PID 42199)]任务开始。 2021-04-07 15:12:19.046 [1617833475626845 /端/ 2(PID 42199)]任务成功完成。 2021-04-07 15:12:19.047完成!
我们现在可以看到我们的过程级别差异已被适当过滤,我们在我们的数据集中不再有损坏的程序代码,首先使用运行路径抓取它:
索引代码价格0 679855CPT®78710,1030.000 1 679856CPT®78710,104 0.000 2 679857CPT®78710,1050.000 3 679858CPT®78710,1060.000 4 679859CPT®78710,1070.000 ......。 .. 1176681 2190407 HCPCS C1769,15784 5886.125 1176682 2190408 HCPCS C1769,15785 5886.125 1176683 2190409 HCPCS C1769,15786 5886.125 1176684 2190410 HCPCS C1769,15787 5886.125 1176685 2190411 HCPCS C1769,15788 5886.125 [1176686行×3列]
通过简单地检索运行路径,并缩小我们的差异流,我们能够重现历史运行的确切输入。
在上一部分中,我们展示了如何使用以前运行的输入运行一个流。我们这样做是为了实现数据版本隔离,以便测试我们的代码更改。我们用于实现这种再现性的相同机制也允许我们跟踪数据谱系。回想一下,我们的管道有两个步骤,每个步骤单独的流量:
显然,一个真实的世界例可能具有更复杂的数据依赖性图表,使这种跟踪更重要。让我们看看我们如何追溯最终差异的血统。首先要做的是创建当前生产数据的运行:
我们现在拥有生产差异的流的运行ID。我们可以以类似的方式访问写入中位数的流程:
作为最后一步,我们可以在输入数据上提取,因为我们存储在DOLT中:
[10]:NPI_NUMBER ...价格0.0.0 ... 75047.00 2 1003139775.0 ... 4572775.0 ... 972.00 4 1417901406.0 ... 296.00 ... ... ... 72724847 94.11 72724849 15989178081C ... 15.4015989178601598917860159989178601915989178661/12.1598917866 ... 15.40 [72724866159891786612/12.00
通过将MetaFlow存储在DOLT中,结果集可以与流和输入数据集相关联。当Metaflow的结果被放入其他数据存储时,我们没有办法将桌面追踪回生成的流程运行。
在这篇文章中,我们演示了如何使用MetaFlow的DOLT。 Metaflow提供了一个框架,用于定义数据工程和数据科学工作流程。使用DOLT用于输入和输出增强了MetaFlow中定义的管道,具有额外的功能。用户可以在其DOLT数据库中检查表,并找到产生该表的流程,如果该流量使用DOLT作为输入,则定位速率输入数据的流量,等等。用户还可以运行流程钉入数据的历史版本,提供可重复的运行,使用数据版本隔离以确保正确测试代码更改。最后,当DOLT用作输入时,提交图可以用于对数据的历史版本的返回测试。
如果您想了解有关使用MetaFlow的DOLT,请加入Doldord的Dolt团队,或结帐Metaflow Docs。