隐含的森林:缩放60fps的十亿个跟踪事件
在试图弄清楚如何顺利缩放10亿微量事件的时间表中,我发现了一棵很酷的树结构,即我无法在线找到其他地方,这是我的两个朋友在找不到任何东西后独立得出的在他们自己的搜索中。它是实现阵列上的索引的索引的一种方法(例如,在O(log n)时间中,在O(log n)时间内,使用摊销常数时间附加,实现简单的实现(周围) 50行锈频),低恒定因子和低记忆开销。
该结构是对隐式二叉树的想法的变化,通常用于堆,这允许您在阵列中紧凑地表示完整的二叉树树,其结构由数组的布局而不是指针确定。我使用的结构而不是像往常一样安排节点宽度,而是使用一级深度第一布置,而是使用两棵尺寸的完整树的森林而不是一个近乎完整的树。这些变化使得追加的实现更简单,提高缓存效率,较低的内存开销,以及与基于虚拟内存的可耕种数组组合提供O(log n)尾随延迟,而不是O(n)。
我使用我的实现来制作一个原型跟踪时间表,可以平滑地缩放10亿个事件,我认为任何现有的跟踪观众可以在保留类似细节时做,但底层结构可以聚合任何关联操作(MONOID)。虽然我的高级竞争程序员朋友没有认识到布局,但我的朋友Raph Levien记住了为Android的SpannablestringBuilder有类似的东西,而我的同事斯蒂芬Dolan说他在推出矢量化友好时继续进行了类似的发现之旅。 KD树。
数据结构背后的一般思想是加速范围查询的是,将元素预聚合到不同大小的块中可以在查询时间中保存工作。当我们获得要查询的范围时,我们选择一组块,一起组成范围并将它们聚合在一起,而不是聚合范围中的所有单个元素。一个二进制段树结构,其中最低级别聚合了两个元素,下一个聚合四个元素等导致保证可以用O(log n)块覆盖任何范围。
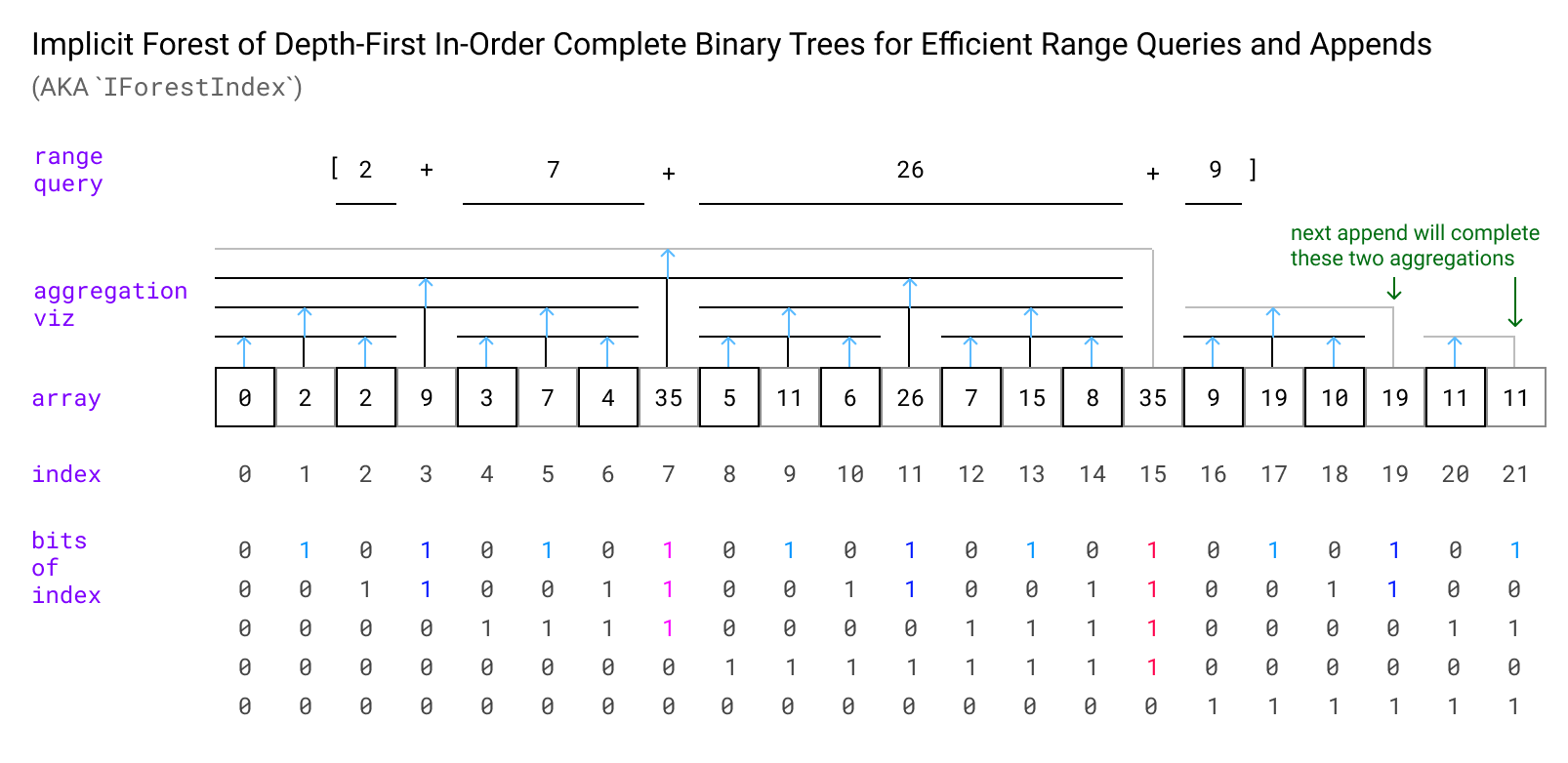
我将描述的是一种在阵列中布置这样的聚合结构的特定方法,请浏览一眼,我将在下面解释图表的详细信息:
按优布局是一种在阵列中存储聚合树的方法,其中每个偶数索引元素是叶子,并且每个奇数索引元素都使用一些关联操作(图使用SUM)到左右左右。聚合节点形成二进制树结构,使得第一级聚合两个叶节点,第二级聚合两个级别一个聚合节点等......
当我们的项目数不是两个的权力时,较高级别的一些聚合节点将无法在它们被假设的右侧聚合,因为还没有节点,所以他们将不完整(图中以灰色显示)。这意味着它不是技术上是树结构,而是一个两尺大小的树木的森林,构成了正确的总物品数量。当我们附加一个新项目时,我们首先将叶节点附加,然后完成应包括该节点的任何不完整树,然后在其后添加一个新的不完整聚合节点。
我们如何决定给定节点应该聚合的级别以及它应该完成的不完整节点的级别?事实证明,通过这种布局,聚合节点的级别对应于索引的二进制表示中的尾随一个位的数量!这很好,因为现代处理器具有“计数尾随零”的有效单个指令,并且尾随刚刚不需要在此之前。结果表明,我们需要聚合的节点是双方的权力,并且汇总节点的数量对应于新聚合节点的级别。这导致了一个非常简单的实现:
ichsl lt;答:聚合> iforestindex< A> {// ... PUB FN推送(& mut self,block:& traceblock){self .vals .push(a :: from_block(block));让len = self .vals .len(); //我们希望每2个节点索引第一级,每4个节点级别2个节点...... //这一时遇到索引中的尾随数量,let level_to_index = len .trailing_ones() - 1; //完整的未完成的聚合节点,现在就准备就绪让mut cur = len-1; //我们刚刚推动的叶子在0。lecth_to_index {let prev_higher_level = cur - (1< level); //级别达到的节点2 ^级别让它们组合= a :: combine(& self .vals [prev_higher_level],& self .vals [cur]);自我.vals [prev_higher_level] =组合; cur = prev_higher_level; } //推送新的聚合节点比我们聚合自我.vals .push(self.vals [len - (1 范围查询更加直接,因为它刚刚从范围的左侧开始,然后使用它可以在没有过冲的情况下使用最长到达的聚合节点跳过前进。我将让代码(和图表顶部的示例)自身说话: PUB FN Range_Query(& self,R:范围< Usize>) - > a {fn left_child_at(node:measize,level:measize) - > BOOL {//每个级别的两个块的每一个均匀功率都在左侧(节点>> level)& 1 == 0} FN跳过(级别:USIZIZE) - > USIZIZE {// LVL 0跳过它旁边的SELE和AGG节点,由2 2的功率提升为2<级别} fn agg_node(节点:使用,级别:USIZIZE) - >使用{node +(1< lten) - 1 // lvl 0是US + 0,LVL 1为US + 1,按功率为2}让MUT RI =(r .start * 2)..( r .end * 2); //翻译到室内索引的下面让Len = self .vals .len();断言! (ri .start< = len&& ri .end< len,"范围{:?}不在0。{}",r,len / 2);让mut组合= a :: fight();虽然ri .start< ri。命中{//通过我们&#39的最高级别跳过;左边的最高级别,它是' t太远,让mut up_level = 1; left_child_at(ri .start,up_level)&& ri .start + skip(up_level)< = ri。ri .end {up_level + = 1;让Level = Up_Level - 1;组合= A ::组合(&组合,& self .vals [agg_node(ri.start,level)]); ri .start + =跳过(级别);组合} 这个布局的最接近的替代方案是在线界边描述的广度 - 首先布局,在其中放置根节点,然后将根节点放在一起,然后是下一级别的所有节点,依此类推到最后,您拥有一些叶子节点,有一些最终的斑点未填充,因为您需要将树尺寸达到两个的下一个功率。这两种布局都具有很好的数学关系,使得能够在叶节点指数和存储您索引的数据之间的阵列之间进行遍历树和映射。 编辑:Reddit上的NightCracker指出,可以使用有效的附加和简化的Quallary查询来制定隐式Fenwick树。它看起来有3N大小的开销而不是2n,o(log n)附加而不是摊销o(1),并且我还没有调查到其他缓存或效率属性。 我最终寻找替代品的主要原因是宽度第一布局的是,宽度首先附加令人讨厌。因为它是一个不完整的树,而不是完整的树木的森林,只要大小交叉,你需要重新排列一切较大的树结构。您不仅需要编写代码来实现这种情况,但新重新分配的树具有4倍内存开销,超过叶节点所需的空间:2x为半空,2x用于所有聚合的通常累计计数节点。然后,如果您没有实现一个花哨的重新组织,那么在6倍时内存峰值,因为您在移动事物时需要在旧的和新树周围。即使您的摊销追加成本仍然是O(1),尾部延迟也很糟糕。 Warning: Can only detect less than 5000 characters 编辑:Twitter上的每个VogneNen说遥测确实有一个范围聚合数据结构,我猜他们用于聚合时间摘要信息面板(因为它们的缩小渲染看起来与perfett不同)。他使用B +树的层次进行了对他讨论设计的有趣HN。 我检查了Perfetto的源代码,发现它将迹线量化为小时间片,并在每个级别的每个时间切片下显示最长迹线跨度的颜色。结合Perfetto的彩色跨度跨度的方法,基于标签的哈希,我认为这是一个很好的方法,概述了一个缩小的痕迹。它倾向于显示主导事件在每个级别,嵌套在不同点的深度,单击显示了特定事件颜色的深度。 问题是Perfetto的实现使用慢速线性扫描,因此当缩小到大迹时非常慢,它们依赖于Asynchrony来保持UI响应于下一个缩放级别。由于“时间片中的最长跨度”对应于“最大持续时间”的范围聚合,因此应该可以使用树结构来加速这一点并找到每个像素下的每个像素下的最长跨度60FPS,因为它只有每帧的10k O(log n)查询的顺序,它可能会在轨道上并行化。 然后我开始了我的旅程,弄清楚了IFOrestIndex数据结构,之后我用它来汇集一个简单的概念概念概念的追踪Viewerthat可以顺利缩放10亿个随机生成的事件的迹线。由于随机生成的数据没有结构,因此颜色不好,因此它不会呈现任何跨度标签,并且我不会向后逐步逐步渲染在视口开始之前启动的跨度,但它有效: 我实际上没有计划实施自己的全追踪观众,这是一项大任务。我只是想有趣地弄清楚如何达到我想要的微量缩放,并在这个过程中弄清楚一个很酷的数据结构,因为我怀疑它是可能的,但不知道任何做的人。鉴于我知道自己的三个人之一,谁必须自己弄清楚这个数据结构,希望这篇文章有助于任何未来想要这种问题的数据结构的人。