使用DataLoaders将数据库查询缩短到最小值
在我们之前的帖子中,我们通过简化处理和通过最小化Node-Postgres等库中的开销来提高性能,让我们深入了解我们如何减少数据库查询(读取以及写入)至最低限度。
数据库的原始概念,如存储库中所述来自Facebook 2010年:
... 2010年Facebook的@Schrockn最初由@schrockn开发的“装载机”API的港口作为一种简化的力量,以实现当时存在的阳光钥匙值存储后端API。在Facebook中,“Loader”成为“ENT”框架的实现细节之一,Web服务器产品代码中的隐私感知数据实体加载和缓存层。这最终成为Facebook的GraphQL Server实现和类型定义的基础。
DataLoader是在JavaScript中实现的这个原始想法的简化版本,用于Node.js服务。在实现GraphQL-JS服务时通常使用DataLoader,但在其他情况下也广泛有用。
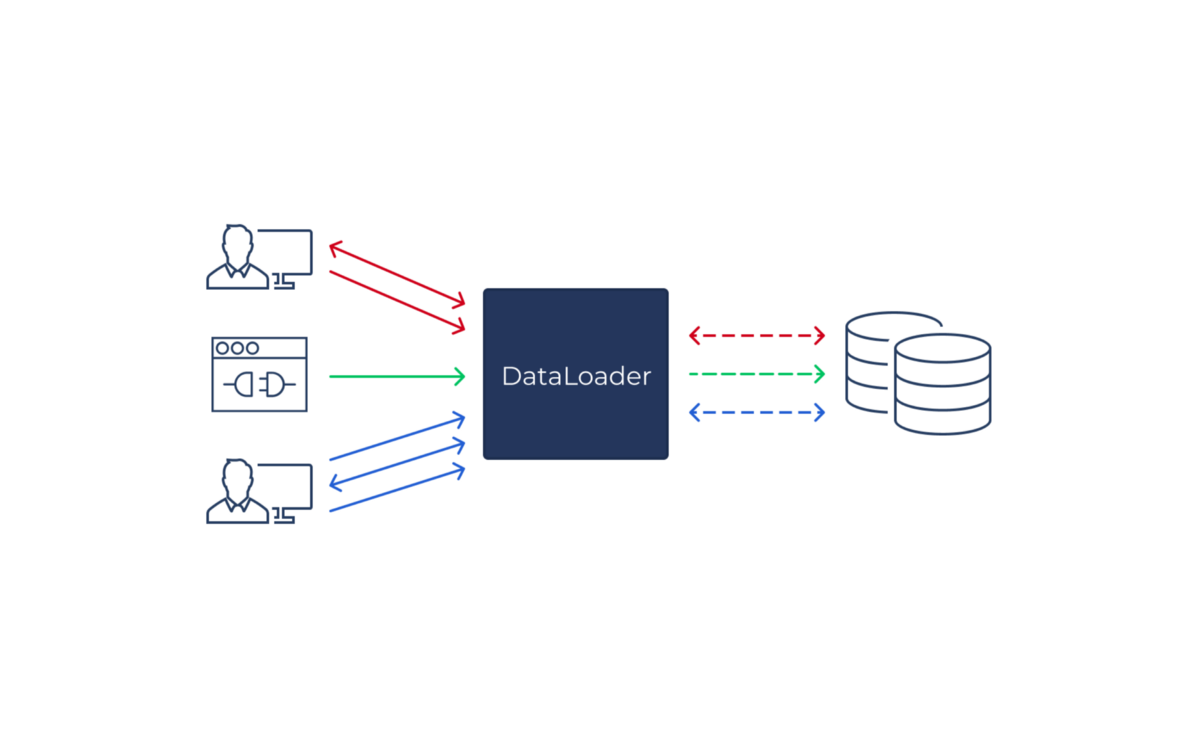
简单地,DataLoader是应用程序代码和一些备用商店之间的抽象,例如数据库,允许批处理请求,以及缓存。
该概念在GraphQL的世界中大量使用,在那里它通常用于弥补N + 1问题。这也是我们第一次遇到这一概念的地方,在提供前正版应用程序的GraphQL API上。
在我们的GraphQL服务器中,我们使用DataLoader来实现每个传入请求的数据库读取的有效批处理和缓存。这对于每个请求的方法,我们构建了一个单独的数据加载器集,然后在请求完成后丢弃。
鉴于此简化的GraphQL查询,DataLoaders如何发挥的简单示例,返回当前用户可以访问的传输列表。对于每个传输,还返回各个载波。
例如,假设用户可以访问5个传输。没有DataLoaders,我们将看出8个数据库查询:
在此示例中,该益处来自于公司yousyId DataLoader,因为它会组组5个呼叫将传输载流子的载体放入单个数据库查询中,因此,保存我们的4个数据库查询。
您可以想象将此示例缩放到更合理的内容,例如访问500传输的用户,使用DataLoaders,数据库查询计数仍然是4,没有DataLoader,它现在是503。
这种方法有助于我们解决上述N + 1问题,同时通过将每个请求进行沙箱对单独的DataLoaders保持隐私 - 缓存结果不在请求之间共享,这意味着任何权限逻辑都不共享。
DataLoaders还通过避免重复数据库查询,以及加快开发人员体验,避免数据库查询中的错误。更常见的是,已经存在代码正在使用的实体的DataLoader。
利用这一点,我们还为apollo-server建立了一个插件,我们在我们之前的帖子中提到了我们在30天内向我们的服务缩放的帖子。此插件分析传入的GraphQL查询的AST,并向适当的DataLoaders熄灭请求 - 无需等待响应 - 实质上启动他们的高速缓存已经拥有实际的GraphQL查询分辨率达到所需的内容调用适当的DataLoaders。
这对我们来说令人难以置信的工作,越多的DataLoaders可以帮助我们避免每个请求的数十个DB查询,使API更快地响应。
我们的早期观察之一是类似于传入的HTTP请求,我们的Kafka消费者通常也在做很多数据库查找。我们的消费者构造的方式是,他们正在处理这些批处理中的批次消息,对于每条消息,一些处理都已完成,结果将一些数据写入DB,或者生成Kafka。
我们注意到,在处理消息期间,如果处理所需的数据库读取,我们最终牺牲了相当的批量消耗的表现。
例如,想象一下,处理消息要求我们从数据库获取一些数据。如果我们获得一批这样的消息,我们受到我们所拥有的DB的并行连接数量的限制,或者我们被迫完全按顺序处理邮件。
这通常导致代码首先在批量邮件中收集一些参数,然后与所有这些都执行数据库查询以获取其他数据,然后再次分割数据,只能单独处理这些消息。
这里的主要观察是我们本质上是重新实施数据面,而是在难以阅读的方式内部,其中包括许多人。
一旦我们意识到Dataloaders可以帮助我们实现相同的结果,但以一种更可读的方式,我们立即在船上。通过一些最小的重构和重新思考,我们提出了更优雅的东西:
在这里,我们向某些实用程序摘要向某些实用程序函数提取了大构建,允许我们构建我们的代码更多模块 - 数据加载代码是单独隔离和可测试的,同时可以使用DataLoader嘲笑(即嘲笑数据库)进行测试方面)。
使用GraphQL使用情况,DataLoaders对缓存结果也很有用。当GraphQL查询的嵌套级别使用相同的DataLoader时,只有最外层实际执行数据库查询。
但是,在Kafka消费者的上下文中,很少是在处理过程中使用相同密钥的相同DataLoader调用了同样的数据加载器的情况 - 代码很可能避免完全避免第二个呼叫。这部分是由于我们的Kafka消息消费者倾向于是一种简单的纯功能,这是一个简单的纯功能,它以非常实用的方式处理 - 读取数据,在处理中使用数据,将结果存储到数据库,并可选择为Kafka生产。
在我们继续之前,在Kafka上有一些背景知识。 Kafka由课题组成,这些主题是分区。这些主题由生产者写入,由消费者群体消耗。消费者团体由消费者实例组成。一个消费者实例可能是消耗同一主题的多个分区,具体取决于有多少消费者实例,与主题中有多少个分区。目标是始终拥有由订阅该主题的消费者组织所涵盖的主题的所有分区。
例如,我们可以拥有一个具有100个分区的主题,但该组中只有3个消费者实例。这意味着每个消费者实例都是处理33(ISH)分区。抛开一些实施方面,我们可能会在一些未来的帖子中深入潜水,实际上这意味着有n个竞争竞争与批次的消息呼叫消费者功能,其中n大致是分区和消费者实例之间的比率群组。
这导致了一个有趣的机会,如果我们不需要DataLoader的缓存方面,并且有许多可能的邮件处理的并行呼叫者,我们可以从呼叫到我们的消息处理器中重用相同的DataLoaders吗?答案是肯定的!
使用Dataloaders,它创建了一次,因为消费者实例开始,我们可以不仅在单个批处理中的邮件中使用它们,还可以跨批量来自不同分区的批量来。这可以大大减少我们制作的数据库查询的数量,同时将代码保持在消费者中更具可读性。
鉴于这些迭代,我们可以分析代码来提出一些绩效的估计值:
当然,在实践中,这些数字变化,但差异仍然存在于数量级。另请注意,通过不同的方法,我们有不同的缩放选项,通过全局数据加载器,我们可以调整批量大小以减少DB查询的数量,使其更大。或添加额外的消费者,制作更多DB查询,但批量较小。
到目前为止,我们只查看了DataLoaders用于加载数据的方案。但是,对数据库的写字呢?他们不能从读数如何讨论批量中受益?当然!
我们确实确实与将数据写入数据库的最后一个改进。为了让更容易区分代码,以及讨论,我们将这些类型的DataLoaders称为MicroGatchers。它们是DataLoaders,通常需要键,作为键,写入数据库的一些更复杂的结构,然后在这些键上执行批处理插入/更新/ UPSERT。
这一次再次出现了一次,大大提高了大多数情况下消费数据的消费者的性能(例如,用于消耗其他计算可能需要的相关实体的数据)。事实上,我们现在拥有甚至没有从数据库读取的消费者的整个消费者,并且只是通过Batchers写入它。
大量数据具有大量数据库查询 - 或者至少是我们最初想到的。使用DataLoaders,此假设受到其核心的挑战。首先在GraphQL侧,在那里它有助于提高API和用户应用程序的响应性。后来,相同的学习帮助我们提高了我们拥有的Kafka消费者的表现。
我们的主要学习是真正拥抱这个概念,而不仅仅是在特定的请求/批处理级别,而且通过将其作为处理这些请求/批次处理的实例来实现。这样,我们完全拥抱并行性提供的可能性,而不通过用请求洪水淹没我们数据库的表现。
重要的是要强调这个学习不仅适用于数据库。 想象一下,有一个RESTFUL的服务,对API进行了一些速率限制。 对此的调用可以被抽象到一个DataLoader中,该数据加载器可以通过例如批量查询,而不是在事件循环迭代之间留在极限内。 可能性DataLoaders优惠多样化,并且可以在许多不同的场景中有用,它是我们工具界中的强大工具,我们可以在不牺牲可读性的情况下使代码更加表现。



