存储系统中的相关失败
Warning: Can only detect less than 5000 characters
足以容忍独立故障的冗余方案可能不足以容忍相关的失败,如我们的数据集中所示。:PDL和NOMDL仅在REP(3),RS(6,3),RS(10,4)下的独立故障下),RS(12,4)和LRC(12,2,2)为零。但是,这些冗余方案的可靠性在我们数据集中的故障模式下降低了。原因是一些相关的失败在短时间内发生(查找3),并且在短时间内,在短时间内可能发生额外的失败,其在同一节点或机架上的现有相关失败(查找2),导致网络竞争带宽资源和修复过程的放缓。这增加了数据丢失的可能性。
延迟恢复不如渴望恢复,以便在数据集中容忍相关的失败。他们比较急切恢复(一旦失败,检测到失败的开始修复)(推迟修复直到第二个,第三,...失败):DataSet中失败下懒惰恢复的可靠性降低的原因是,当失败的块的数量达到更大的块故障阈值时,在短时间内也更可能发生额外的相关失败(调查结果2和3)。因此,最适当的阈值故障次数是一个,
例如,RS(10,4)系统可以容忍4个故障。如果失败是独立的,推迟修复,直到检测到3个故障似乎是安全的。但失败是相关的,因此在修理之前发生故障4和5的可能性可以完成高。
值得注意的是,作者包括全面的书目和相关工作概述,其中一些我以前讨论过。亮点包括在日期顺序:2006年和#39;在分布式存储系统的高效副本维护中,在PlanetLab的数年中检测到相关的数据。
在来自同一NSDI会议的第二篇论文中,Nath等人在广域储存系统中容忍相关失败的微妙之处(我的重点):实际上,失败独立的假设很少。节点故障通常是相关的,系统中的多个节点发生在同时(近)。这些相关失败的大小可能非常大。例如,Akamai在2004年5月和2004年6月经历了大型分布式Denialof-Service(DDOS)攻击,导致许多客户网站的不可用...... PlanetLab在2004年上半年经历了四场失败事件超过35个节点(≈0%)在几分钟内失败。这种大相关失败事件可能具有许多原因,包括系统软件错误,DDOS攻击,病毒/蠕虫感染,节点过载和人为错误。故障相关性与系统不可用的影响是戏剧性的(即按幅度的顺序)......因此,容忍相关的失败是设计高可用分布式存储系统的关键问题。尽管研究人员长期以来一直意识到相关的失败,但大多数系统都是在独立失败的假设下进行评估和比较。
顺便提一下,同年我的共同作者和我讨论了4.2节新闻中的档案存储系统对档案存储系统的影响。
在2007年'理解磁盘故障率:1,000,000小时的MTTF对您意味着什么?施罗德和吉布森在大型存储系统中查看了硬盘替代品:我们通过计算在给定周或月份和前一周的替换数之间的相关系数来确定在连续周或数月内观察到的磁盘替换数的相关性或月份。对于来自泊松过程的数据,我们将期待相关系数接近0.相反,我们在每月和每周级别都找到了显着的相关性相关性。
2010'通过Ford等人在全球分布式存储系统中提供的可用性在Google' S存储系统中的一年内进行了一年的不可用。在第4节中,他们:应用一个聚类启发式,用于分组几乎同时发生的故障,并显示大部分失败发生在爆发中。
量化故障突发与给定失败域有多可能。我们发现大多数大的失败突发都与机架或多次级别事件相关联。
他们写"可用性模型中的关键元素是他们考虑相关失败的频率和幅度的能力。"
同年Schroeder等人在了解潜在扇区错误以及如何保护它们时研究空间而不是时间相关性:在尝试防止LSE时,重要的是要理解错误突发长度的分布。错误突发,我们的意思是逻辑块空间中连续的一系列错误。例如,磁盘内冗余方案的有效性取决于突发的长度,随着大量连续误差可能影响相同奇偶校验组中的多个扇区,防止磁盘内冗余恢复。
2015年'来自Carnegie-Mellon和Facebook的Meza等人的闪存失败的大规模研究由Carnegie-Mellon和Facebook确定了个体SSDS失败的时间相关性:每个机器错误差异的解释可能是那样的错误事件相关。检查数据表明,这确实如此:在最近两周内,第一周内出现错误的99.8%的SSD也发生了错误。因此,我们得出结论,过去可能在过去的错误的SSD很可能在未来继续存在错误。
两个&#34之一;最好的纸张" Usenix' S2020快速会议是在U.多伦多和NetApp的Bianca Schroeder的大规模企业存储部署中的SSD可靠性研究。他们写道:我们的结果强调了同一RAID组内的时间上关联失败的发生。该观察表明......现实数据丢失分析肯定必须考虑相关的失败。
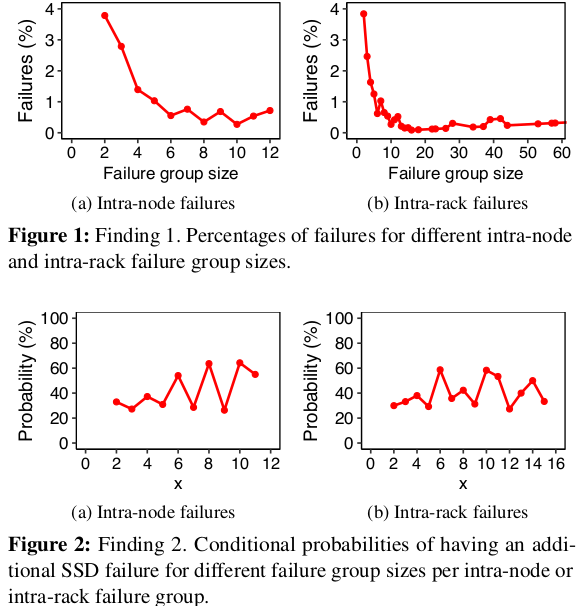
如您所见,Correliations是十年半的重复主题。他们在各个层面检测到各个层面来驱动到RAID群体,现在,感谢Han等人,在数据中心的节点和机架的水平上。不可忽略的SSD故障分别属于节点内和机架故障(分别在我们数据集中的12.9%和18.3%)。此外,节点内和机架故障组大小可能超过一些典型的冗余保护方案的可容忍极限。
在节点内(帧内机架)故障组中具有额外的内部节点(内部机架)故障的可能性取决于现有的内部节点(内部机架)故障。
甚至在一分钟内,在短时间内发生不可忽略的节点和内部齿条故障的一部分。
内部节点和帧内故障的相对百分比在驱动模型上变化。从同一节点(机架)中的相同驱动模型中放置太多的SSD导致高百分比的节点内(帧内机架)故障。此外,AFR和环境因素(例如,温度)影响节点内和齿槽内故障的相对百分比。
节点内的内部节点和帧内故障存在不可忽略的部分,对于大多数驱动模型。
具有较高密度的MLC SSD通常具有较低的节点和齿槽故障的相对百分比。
内部节点和机架故障的相对百分比随着年龄的增长而增加。由于使用的额定寿命增加,较旧时代的节点内和机架内故障更可能发生在短时间内。
内部节点和齿槽故障的相对百分比越差显着越差。对于不同阈值的故障时间间隔和容量,在节点内 - 节点的相对百分比之间没有明显的趋势。
智能属性与节点内和帧内故障有限,并且对于内部节点和机架故障,最高SRCC值(来自S187)仅为0.23。 因此,智能属性不是用于检测节点内部和机架故障的存在的良好指标。 此外,节点内和帧内故障对每个智能属性的SRCC绝对值没有显着差异。 写主导工作负载总体导致更多SSD故障,但不是AFRS上唯一的影响因素。 其他因素(例如,驱动模型)可以影响AFR。 每个节点(机架)和写主导工作负载更多SSD的应用程序往往具有高百分比的节点内(帧内机架)故障。 在个别应用中,较旧的节点内和机架内的故障趋于在短时间内发生更多的写入主控工作负载。