GPT-3与3M自由文本琐事响应
在那里,我是科林,一个人,而不是人工智能的遗传产出。侦察员的荣誉。
我写的是,因为(似乎)GPT-3文章的第一个月开始以一个引人注目的赛,一个挑衅的中间,并在作者之前结束了一个越来越多的GobbledyGook,揭示了揭示前的一切都是由GPT编写的-3。
回到2017年,我共同创立了一个在线琐事平台(水冷却器琐事)与两个亲密的朋友。我们希望以超过300万自由文本琐事响应,我们对GPT-3测试我们的用户。
具体来说,我们想看看GPT-3是否是琐事中的无法应任的对手 - 一个臭名昭着的挑战性域,而不是跳棋或国际象棋。
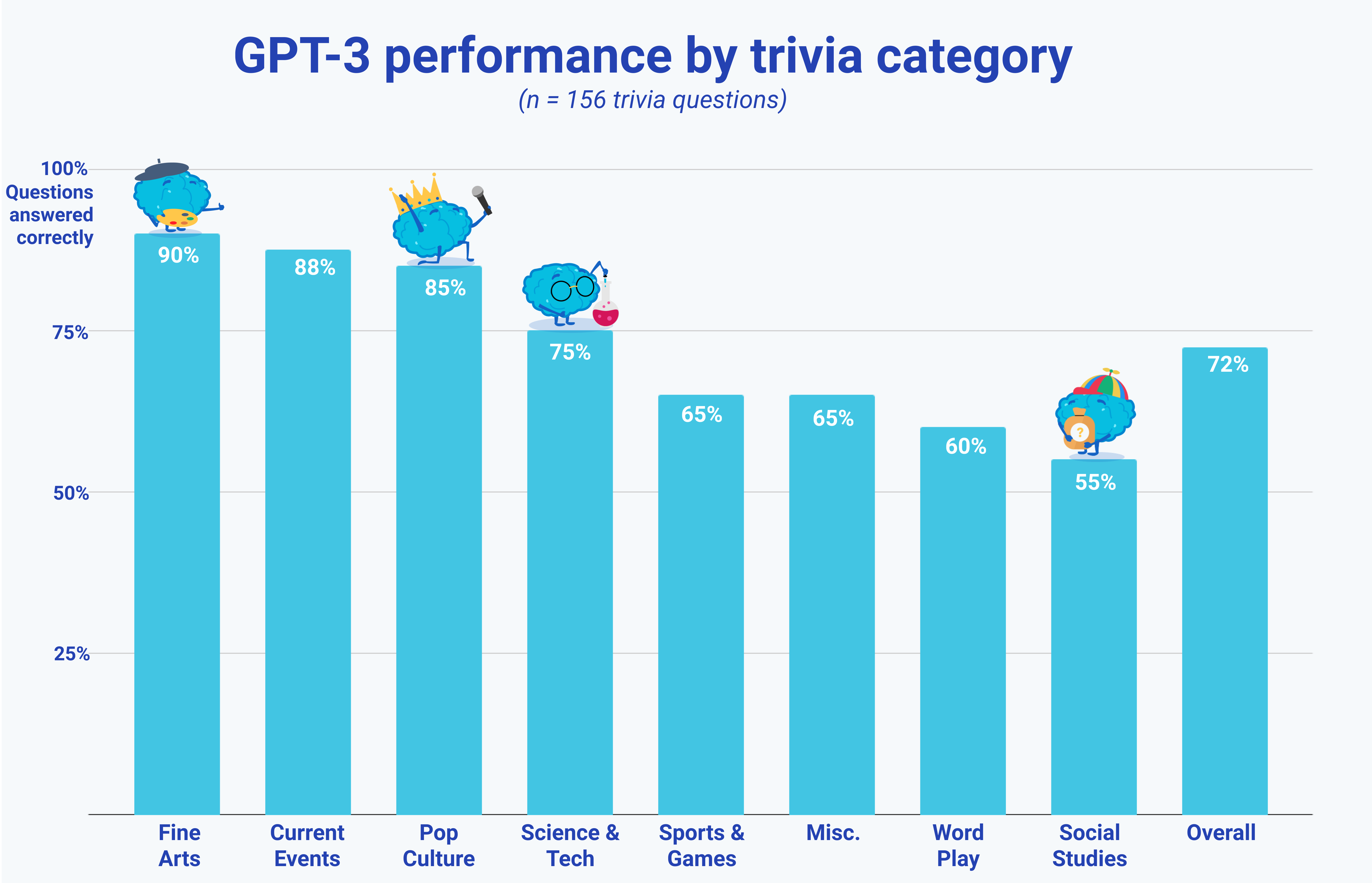
扰流板:GPT-3获得了156个琐事问题的73%是正确的。这与52%的用户平均值有利相比。然而,这不是全征服的壮举:37%的参与者在他们最近的测验中获得了73%。这里的全套GPT-3回应。
机器人在美术和当前事件中是最好的,最糟糕的是播放和社会研究。我有背景,数据,图表,下面的所有好东西。
好问题。它是一种计算机程序,它使用机器学习来产生人类的文本。但不要考虑你最不喜欢的银行网站上的聊天。从钢铁侠特许经营更像贾维斯一样。这是公开的机器学习的最前沿,它真的很擅长它所做的。它是塑造的副本,写入计算机代码,并将人类句子转换为完全形成的图表。
“鉴于任何文本提示,API将返回文本完成,试图匹配您给出的模式。您可以通过展示您希望的几个例子来“编程”它;它的成功通常因任务的复杂程度而异。“
对于此练习,我们使用默认的“q& a”提示GPT-3。这是我们使用的GPT-3版本。这是关于GPT-3的博客文章。
Credit of截止日期:Wct Dennis的朋友写了脚本,将水冷却器琐事问题送到GPT-3并访问Openai API。丹尼斯是一个建造gamemonk的琐事书呆子。谢谢你,朋友!
这是一周的Trivia测验,通过Slack或电子邮件发送,并在全球各地的成千上万的工作团队使用。它激发了谈话和建造团队Camaraderie。数百名球队告诉我们这是他们最喜欢的每周队的仪式。这是90秒的解释者视频。
我们所有的问题都有免费的文本响应,我们拥有330万次响应与元数据的ocks。上次我们数据剥夺了我们写了大约255个不同的Arnold Schwarzenegger拼写。
2011年,IBM的Watson超级计算机在两个危险之中竞争!与传奇参与者Ken Jennings和Brad Rutter的比赛。深蓝色后面的计算公司再次成功。 Watson轻松赢得了比赛,两场比赛奖金为77,147美元与24,000美元(詹宁斯)和21,600美元(鹿特)。
胜利被广泛欢呼,因为危险之中,对人类的计算机进行了粉碎成功,因为危险之中!的瞳孔和独特的措辞使其比棋盘的有限空间更具挑战性。
然而,琐事 - 费利利斯魔术术语,作为最高水平的危险态度!比赛往往归结为蜂鸣器技能(速度,时机)oreso而不是琐事知识。在这个前面,沃森真的无与伦比;它的机器人武器可以推出詹宁斯和垃圾的嗡嗡声。
一个体面的启发式是假设所有球员都试图在每个问题上嗡嗡作响。当以这种方式观察时,当参与者嗡嗡声时,性能的最佳衡量标准只是效正。(游戏1统计,游戏2统计数据)
外带:沃森真的很擅长琐事,与最伟大的危险运动员相提并论,但并不明显比他们更好。
Takeaway更重要的是:IBM的数十家技术人员花费了三年多的时间,Untold ultors建造了专门为危险训练的计划!实力。不到10年后,一种没有大型主机或冷却风扇的通用开放性技术可以在同一水平上竞争。
另一个经典例子的机器学习与琐事之间的交叉例子?计算机科学家和危险员工的培训策略! Champion Roger Craig。
如上所述,水冷却器琐事是所有免费文本问题(而不是多项选择)。这意味着我们有一些手动分级,可以创建300万份反应的数据集。
我们希望在这些类别中给予GPT-3一个健康的问题和困难。特别是,我们热衷于评估我们最艰难,最简单的问题的GPT-3(难以评估我们的用户在300万分级答复中所做的程度)。
我们将问题发送到仅限于那些至少500个响应的问题,问题内容没有过期,以及那些不依赖于附加图像的问题。这是全套156个问题。
正如大多数预期的那样,GPT-3在当前的事件和美术上表现出色,杂项(许多双张驱动的食物问题)和单词播放(上面讨论)作为棘手的区域。最令人惊讶的结果?社会研究的表现不佳,主要是在该类别中的单词交叉问题的单词竞争程度驱动。
我们预计GPT-3将对我们的用户做好工作的问题,以及我们用户做出恶意工作的问题的恶化工作。这是真的。该计划的问题提出了91%,以上75%的参与者得到了正确的问题,52%的人在25%的参与者或更少的问题上得到了正确。
这个不太令人惊讶。我们有一种称为“两者goofer”的问题,该问题要求一对满足给定线索的一对押韵词。它类似于危险中的押韵时间类别或旧报纸拼图艺术主义。我们在摊牌中有三个问题,GPT-3错过了所有三个。
我们在每个问题开始时有一个声明的双字短语,以添加一些Flair和参与者的线索潜行。在下面的图像中,它将是Kooky王国。
对于GPT-3,这些线索是净负数。在几个情况下,机器人覆盖程序在移除线索时正确地回答。
这让我们想起了Watson在危险中无法使用美国城市的最终危险类别作为暗示这个问题的答案,答案不会是多伦多。
混淆GPT-3的其他线索是答案的长度的内联迹象。下面,我们明确要求五个字母的动作,GPT-3给了我们两个单词的八个字母。
对于每个团队的每周测验,我们添加了一个“表情符号最高级”。使用我们的手动评分,我们庆祝我们考虑有趣或书呆子或热门的结果的回复。
当答复包括比必要的更多信息,我们授予🤓emoji。 GPT-3非常容易发生这样的答案。通常,它只是一个问题的重建而不是提供批发新信息。一些例子:
计算机擅长琐事。当沃森帮助危险时,这是真实的10年前!设置评级记录,现在甚至更真实地使用机器学习技术以加速速度进展。
好消息是,琐事从来没有关于谁得分最正确的答案。对于水冷却器琐事,每当每周有空闲时间时,人们都会单独填写他们的问题。这意味着Googling正确的答案是非常可能的;然而,作弊的情况非常罕见。这个乐趣来自你的大脑凹陷的事实,并学习你的同事如何通过美国地理学中的第三个最小的状态。
因此,即使机器人越来越好,更易于获得,琐事也不会随时随地作为连接和乐趣的源泉。哦,水冷却器琐事完全免费四周,需要60秒才能开始。