留出了ttl地狱
决定高速缓存的数据的TTL("时间才能生活,或者待命,保留多长时间)可以成为程序员的一种巨大的数字。通过TTL缓存可以获得正确的速度。但是你能负担多少正确性?在有意义地混淆之前,您可以在某个地方向用户展示错误的值?在他们账户中怀疑问题之前多久并成为客户服务的负担?
缓存很重要,因为它有一个大的加速。具有天真的程序,但使用缓存井的程序通常更快,然后是具有巧妙代码的程序,该程序并未与#39; t。使用缓存通常会更改系统的隐式复杂性类 - 向下和持续时间。
不幸的是,它也公平地说缓存是不利的。关于应用级别高速缓存的某种势利。它'更专业地尊重,可以在A&#34中重写该计划;系统编程语言" (阅读:快速,编译,严重)大于将memcache自由应用于您的PHP应用程序(阅读:A"带帮助" apache2,仅由jokers使用)。这是一个耻辱,特别是因为经常重写并开始(或从未完成过),PHP应用程序保持在PROD,坚定不移和不动产,并且容易验收。
在本文中,我将详细说明不放弃速度的正确性的缓存策略。这些策略都消除了TTL,而是使用主动失效。
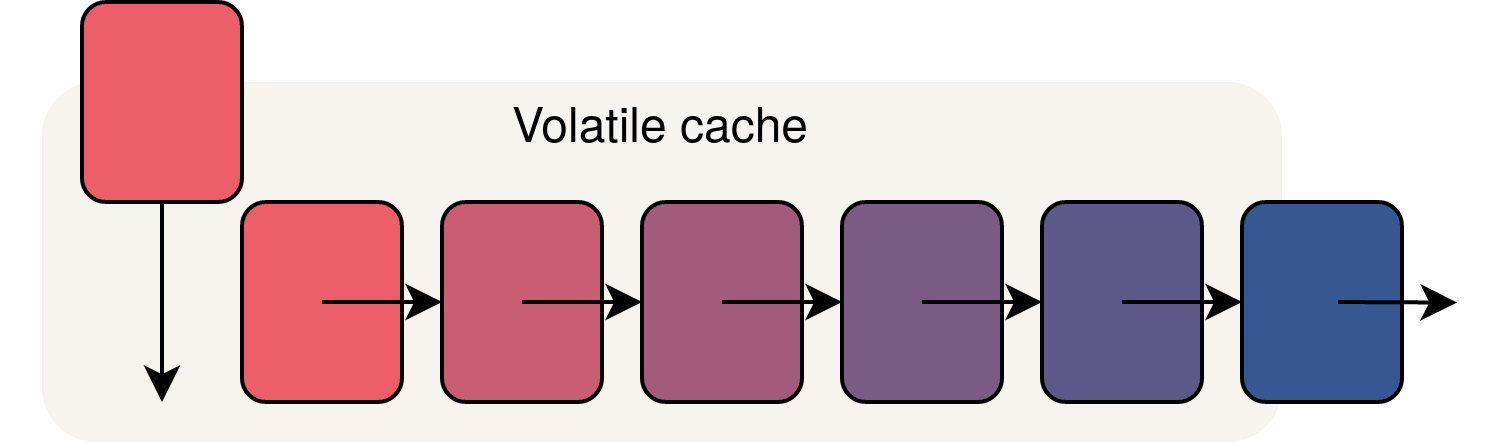
最简单的策略是从不使其失效。一些数据并没有变坏。 CSV上传的内容#42345 Won' t改变。既不是某些标记格式的产品数据的HTML转换。一个人的原因,人们不考虑这个策略是他们错误地担心缓存会"填写" Volatile Caches Don'那样的工作。
您不需要通过TTL的橡胶杆管理挥发性高速缓存的内容。易失性缓存将管理其自己的内容:通过驱逐。
应用程序缓存,无论是memcache还是适当配置的redis(见下文),在A&#34下运行;最近最近使用" (LRU)算法。很少使用 - "冷" - 根据需要进行数据,以便为更频繁使用的空间 - "热" - 数据。这确保了整个缓存尽可能热,鉴于可用空间。目的是有一个"完整"始终缓存。
Don' t混合驱逐 - LRU部分,到期 - TTL部分。可以在已过期之前进行数据。它通常会是:大多数高速缓存Don'在寻找东西时考虑TTL。
有时你想缓存会改变的东西。例如,您的应用程序' s用户对象:用户名,电子邮件地址,邮政地址等。此数据键随时间而变化,但也会非常频繁地访问,通常在每个请求或每个操作的一部分中都已频繁访问。
这里最好的方法是在更新持久存储中的数据时更新缓存。这样,缓存的情况保持最新,而不需要任何模糊TTL和所有相关的猜测,以便保持有效的时间。布里尔。
在此策略下,读取将主要来自缓存,只需要写入永久商店或数据库。缓存释放不是问题:当缓存没有保持某些东西时,您将返回到数据库的读取(对于我在此页面上讨论的每个策略的要求)。
有点奖金是,许多数据库可以在作家逃脱时争夺读者争夺锁的争夺者。
有时对数据的更改可能会影响缓存中的多个事物。例如:您可能会在其User_ID和Email_Address下保存缓存中的用户对象。每当您更改用户时,您都会在内存中有一切,因此您可以轻松更新两个缓存值。您可以在编辑用户的代码库中的一个地方封装这个。快乐的时光。
当你在手头上and#39时,麻烦的是你的所有数据你需要做那些更新。例如,当用户喜欢文章时,当您的大多数喜欢的文章作者的列表中的缓存需要更新,但是您不会在内存时在内存中的所有数据'重新处理a单身像。您可以在每次中都将其拉动,以便在缓存中重新计算此列表 - 或者您可以简单地使缓存中的列表无效,并在下次需要时重新生成它。
它可能会因场景而异,但通常无效将使速度将额外数据拉到程序中,只是为了馈送缓存。它没有总体'下次再生'所需的价值并不知道,你永远不知道,你可能是幸运的:也许用户赢得了'在它再次改变之前看它。
此策略通常具有链接数据,但极其经常具有聚合数据。无效的写入可以应用于相当广泛,但具有很大的限制:您需要知道缓存密钥以使它们无效。始终可能。
当没有有限的,知识,键列表时无效,因为从更改中的敲击效果是最佳解决方案是缓存"命名方式"
命名方式如下所示:您有一个特殊的命名空间值,您将作为其他缓存数据的键的一部分包含。通常,但并不总是,命名空间值是最后一个变化的单调增加时间戳。
/ namespaces / user657将存储最后一次用户的单调越来越多的时间戳#657更改了他们的个人资料,例如1514937600。
每个逻辑缓存查找现在都需要两个实际查找 - 首先是名称空间键,然后为实际键。当用户更改某些内容时,您更新其命名空间键的内容以及旧名称空间键下的所有键现在都无法访问,因此无效。当他们冷静下来时,他们会被驱逐出来。
明显的缺点:每个命名的缓存访问现在都需要两个往返而不是一个。它往往值得。首先,因为命名方式允许更广泛地使用缓存而不是 - 你'再缓存你不能' t否则。第二个原因是两个缓存往返旅行通常仍然更快,再生或检索它是什么。作为缓存未命中,高速缓存命中率最快地迅速。
小心:有很多方法可以天真地"改善"这种策略在不起作用的方式'我赢得了' t'详细介绍了可惜"改进的"版本,除了指出像这样的方案所需的两种不变性正常工作:
命名空间键需要至少与它下面的最热门的钥匙一样热,否则它的危险是持续被驱逐前方的危险。祝福"优化"这避免了不得不检索它 - 这将导致LRU缓存将其视为寒冷。
事实上,这种失效假设没有其他方法可以访问陈旧的子键。要小心尝试用基于标记的方法替换分层命名空间,这允许这些陈旧的子亮度在预期的无效后继续检索。
HTTP有一个缓存系统内置它,但它' s一个仅限TTL系统。虽然广泛地说,策略#1继续工作:刚刚设置一个荒谬的长TTL和浏览器,CDN将遵守它 - 在他们关心的范围内。
策略#4在HTTP中也很好,除了在这种情况下,它通常被称为"缓存破坏"常用用法是将版本字符串或将时间戳放入URL路径或查询字符串,以确保浏览器仅下载最新的JavaScript捆绑包。
有时CDN提供明确的清除API,但这主要是人们部署到静态文件的更改的同意。传统的CDN清洗往往需要几分钟才能完成,所以可能没有依赖于应用程序级别的东西虽然vIrce.io在其中'重新在CDN内运行一点的代码可能更好。
缓存对您自主主机(如纸色和Apache)交通服务器(如varnish和apache)交通服务器)的反向代理可以使用非标准推送动词,以便明确控制缓存内容。如果您可以明确无效,您可以使用策略#2和#3。如果您手上有文件,为什么不填充您的反向代理和#39; s缓存?
总体而言,关于在HTTP级别缓存的好事是它将工作从Applications Server' s板上工作。
缓存ISN'所有的阳光和彩虹。以下是一些问题,以避免和一些提示。
一个实际问题是,偶尔程序员将屈服于基础软件架构并开始使用缓存作为数据库并将真实数据放在那里。
有些人犯下了这个罪,因为获得了由组织批准的新数据师' S中央银空技术咨询委员会是一个官僚主义的噩梦。同时,缓存服务器坐在那里,看起来像一个你可以堵塞的东西。因此,在不需要向任何人提出许可的情况下,保持一些静态数据似乎是一个很好的地方。 "当然,这种数据总是足够热,不得被驱逐"有人认为。但最终他们的特殊数据会变冷,当Memcache将其东西放入太空时,牙齿会有很大的哀号和咬牙切齿。 "愚蠢的缓存!你怎么敢!"
其他时间,原因是缓存具有的额外功能。 Redis拥有大量内置的功能,远远超越缓存:它可以作为消息总线,服务查找器,工作队列,甚至作为一种非关系数据库。但是,Redis' S内存限制和驱逐策略是全局设置的,针对整个实例全局设置,默认值不适合缓存 - 它们的目标是redis的非易失性使用。
redis' s默认最大内存设置(maxmemory)是无限制的,这意味着实例将永远扩展 - 即使超出物理内存 - 没有震动。对于缓存,设置严格小于物理内存的最大内存限制。默认的撤消策略(MaxMemory-Policy)不是震动,而是在内存已满时引发错误。再次,不适合缓存你想要驱逐的地方。将此设置为AllKeys-LRU。
大多数托管服务,如AWS' Elasticache,对驱逐政策有不同的默认值:Volatile-lru。此设置仅考虑驱逐具有TTL集的键。这意味着"聪明"并允许通过过载TTL标志来允许对高速缓存数据进行额外用法。事实上,Volatile-Lru是一种巨大的陷阱,具有很多令人惊讶的失败模式。对于其中,它可以鼓励程序员将非缓存数据放入Sysadmins将其视为易失性和暂行的服务器中。对于另一个,Don' t知道这个特殊设置的程序员通过错误地插入没有TTL的缓存数据来填充实例。
您可以将REDIS设置为A"数据结构"服务器或您将其设置为缓存。你可以' t兼顾。如果您选择使用REDIS作为缓存,请确保缓存实例仅用为您的缓存。您的系统间消息总线应该在不同的配置中与不同配置的redis。
它'重要的是从来没有要求缓存命中 - 甚至可以作为一个软要求。驱逐可能发生在不方便的时期 - 例如当系统的其他一些部分都在负载时 - 而且有没有对缓存未命中的任何负面后果。
一个特别顽皮的事情是仅在缓存中存储网络会话。缓存未命中被解释为倒霉的用户的非自愿退出,没有任何错误并违反任何人。相反,使用上面的策略#2并将其存储在数据库中的网站上,使用您的缓存作为加速。
摇动这样的问题,值得尝试用特殊的缓存运行自动测试:击中率为0%或随机命中率的问题。没有任何东西应该被缓存未命中丢失,因此失败的任何测试都值得调查。
上面的代码没有错,但它只允许策略#1:永远不会使其无效。如果您需要无效/更新代码必须更多地涉及:
来自pyappcache导入rediscache my_cache = rediscache()def get_slow_thing_v2(thing_id):thing = my_cache。 get_by_str(thing_id)如果是none:thing = get_slow_thing_from_a_database_layer()my_cache。 set_by_str(thing_id,thing)返回the def update_something_slow(thing_id,new_thing):my_cache。 set_by_str(thing_id,new_thing)set_thing_in_a_database_layer(new_thing)
第二个版本是Worder但是可以在设置某些内容时更新缓存。
另一个优点是您可以按键检索来自其他地方的缓存的值 - 它' s不再与get_something_slow_v1相关联。这并不是很多在微不足道的案件中,但在更大的系统中表现得很重要。如果您可以通过参数缓存,为什么不纯粹基于函数参数的函数参数在缓存上开发固定的固定。
如果您在Python工作并希望缓存的东西,请考虑使用我的库:pyappcache(此处的代码,在此处的代码)。
Python还有其他好的库,包括DogPile.cache,Cachew,您可以直接使用Redis-PY或PyliBMC。
这一切都不是暗示,使用缓存总是值得的。它更加用于编程缓存的工作,需要运行额外的备用服务,并且当然是错误的错误。 "拉秋葵效果"缓存错误使它们特别令人沮丧,都既可以体验和调试。
一切都是如此,如果应用了Memcache的斑点,则可以在那里有大量的系统,这可能会下降一些AWS实例大小。想想环境,如果这激励你。
一个提示:它最好首先开始无效。释放某人:"不询问您可以缓存的内容 - 请问您可以无效的内容"如果你可以和#39; t无效,它不太可能在第一个地方缓存它。在您开始尝试缓存某些内容之前,请检查您是否可以使其无效的所有位置无效。
请随时向我发送一封关于这篇文章的电子邮件,特别是如果您不同意它。
当我通过电子邮件警报或RSS Feed写新的东西时,您可以收到通知。 如果您享受了本文,因此由于对我感到慈善,请测试我的网站项目,Quarchive,讨论福斯社交书签风格网站,并给我发电子邮件! 我喜欢Memcache维护者的这种解释,而是为什么它不是一个好主意,只是为了在缓存中存储会话。 我喜欢的两个页面描述了memcache的(温和过时,大图)设计:Tinou'用于假人和Joshua Thijssen的Memcache' s memcache内部。 Memcache' S文档很好,而且清楚未完成的内容包括一些诀窍,我哈登' 在尝试执行此操作之前,使用它的redis'使用它的文档是必需的。 与Redis中的大多数事情一样,有锋利的边缘。 它很重要的是要知道默认值会导致缓存使用情况的问题。