Lyra音频编解码器可实现3 kbps比特率的高质量语音通话
我们经常写关于AV1或H.266之类的新视频编解码器的信息,最近,我们介绍了AVIF图片格式,该格式相对于WebP和JPEG具有更高的质量/压缩率,但是在音频编解码器方面也有很多工作要做。
值得注意的是,我们注意到Opus 1.2在2017年发布时以低至12 kbps的比特率提供了不错的语音质量,2019年Opus 1.3的发布进一步改善了编解码器,仅9 kbps的高质量语音就可以实现。但是Google AI最近推出了用于语音压缩的Lyra极低比特率编解码器,它以低至3kbps的比特率实现了高语音质量。
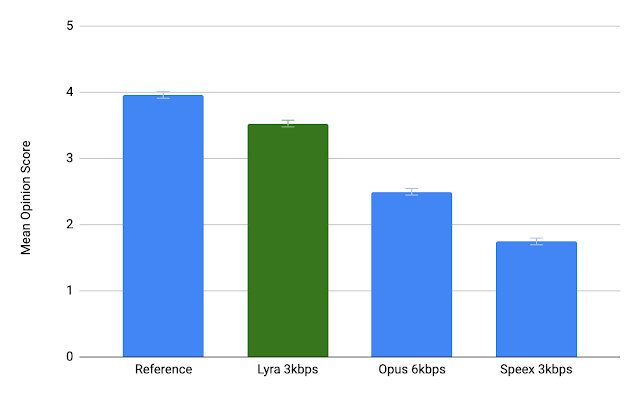
在我们详细研究Lyra编解码器之前,Google比较了一个以3 kbps的Lyra,以6 kbps的Opus(Opus的最小比特率)和以3 kbps的Speex编码的参考音频文件,用户报告说Lyra听起来是最好的,并接近原版。您实际上可以自己尝试。
对于所有样本,Speex 3kbps听起来都非常糟糕。我感觉Opus 6kbps和Lyra 3kbps的声音与干净的语音样本大致相同,但是Lyra在嘈杂的环境中可以更好地重现背景音乐。
那么,天琴座是如何工作的呢? Google AI解释了Lyra编解码器的基本体系结构依赖于特征(对数梅尔频谱图)或独特的语音属性,它们代表不同频段的语音能量,每40毫秒从语音中提取一次,然后压缩以进行传输。在接收端,生成模型使用这些功能来重新创建语音信号。
Lyra的工作方式类似于美国国防部(US DoD)为军事应用和卫星通信,安全语音和安全无线电设备开发的混合激励线性预测(MELP)语音编码标准。
Lyra还利用听起来自然的生成模型来保持低比特率,同时获得高质量,这与较高比特率编解码器所实现的模型相似。
我们以这些模型为基准,开发了一种新模型,能够使用最少的数据来重建语音。与当今大多数流媒体和通信平台中使用的最新波形编解码器相比,Lyra利用这些新的自然声音生成模型的功能来保持参数编解码器的低比特率,同时实现高质量。波形编解码器的缺点是,它们通过逐个信号压缩并发送来实现高质量的编码,这需要更高的比特率,并且在大多数情况下不需要获得自然的语音。
生成模型的一个关注点是它们的计算复杂性。 Lyra通过使用更便宜的循环生成模型WaveRNN变体来避免此问题,该模型以较低的速率工作,但并行生成不同频率范围内的多个信号,随后将其组合为所需采样率的单个输出信号。这个技巧使Lyra不仅可以在云服务器上运行,而且可以在中端手机上实时运行在设备上(处理延迟为90ms,这与其他传统语音编解码器一致)。然后,该生成模型在数千小时的语音数据上进行训练,并类似于WaveNet进行优化,以准确地重新创建输入音频。
即使在信号质量差,带宽低和/或网络连接拥塞的情况下,Lyra仍可实现可理解的高质量语音呼叫。它不仅适用于英语,因为Google已使用开源音频库用70多种语言的扬声器对数千小时的音频进行了训练,然后通过专家和众包的听众来验证音频质量。
该公司还期望借助AV1视频编解码器和Lyra音频编解码器的结合,在56kbps的拨号调制解调器连接上实现视频通话。最早使用Lyra音频编解码器的应用程序之一将是Google Duo视频通话应用程序,该应用程序将在带宽非常低的连接上使用。该公司还计划使用GPU和AI加速器进行加速,并已开始研究Lyra所使用的技术是否也可以用于创建音乐和非语音音频的通用音频编解码器。可以在Google AI博客文章中找到更多详细信息。
让·卢克(Jean-Luc)于2010年开始从事兼职工作,之后辞去了软件工程经理的职务,开始撰写每日新闻,并于2011年晚些时候进行全职评论。



