我如何将GTA Online的加载时间减少70%
GTA在线版。以其缓慢的加载时间而臭名昭著。再次拿起游戏以完成一些新的抢劫案后,我感到震惊(/ s),发现它的加载速度仍然与7年前发布时一样慢。
首先,我想检查是否有人已经解决了这个问题。我发现的大多数结果都指向有关游戏如何如此复杂以至于需要加载这么长时间的ececdata,有关p2p网络体系结构是垃圾的故事(不是说不是),以及一些详细的故事加载方法。模式和此后的独奏会话,以及几个允许跳过启动R *徽标视频的mod。多读一些书告诉我,将这些结合起来可以节省10到30秒!
故事模式加载时间:〜1m 10s在线模式加载时间:〜6m flat启动菜单已禁用,从R *徽标到游戏中的时间(不计算社交俱乐部的登录时间)。老式但不错的CPU:AMD FX-8350 Cheap-o SSD:KINGSTON SA400S37120G我们必须拥有RAM:2个Kingston 8192 MB(DDR3-1337)99U5471良好的GPU:NVIDIA GeForce GTX 1070
我知道我的安装程序已过时,但是加载到在线模式可能需要6倍的时间?使用其他人在我之前发现的从故事到在线的加载技术,我无法衡量任何差异。即使它确实起作用,结果也会降低噪音。
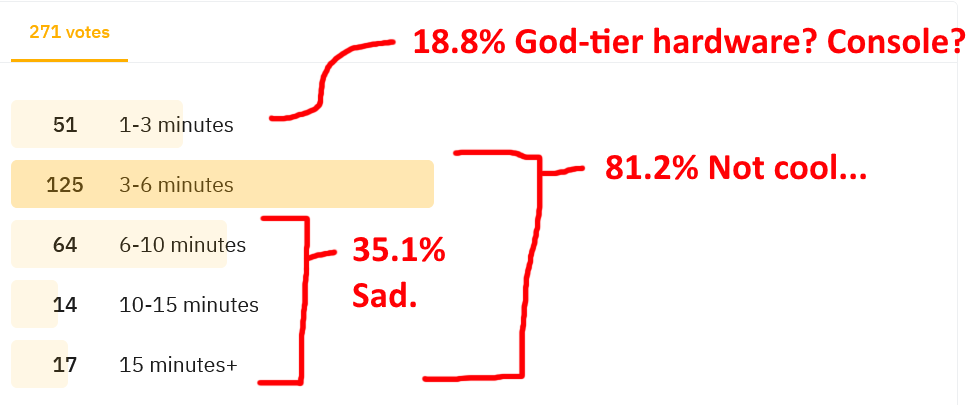
如果要信任此民意测验,则问题将广泛传播,以使80%以上的玩家群受到轻微的骚扰。 R *已经有7年了!
环顾四周,找出谁是幸运的,获得不到3分钟加载时间的〜20%的人,我遇到了一些基准测试,其中包含高端游戏PC和大约2分钟的在线模式加载时间。我会在2分钟的加载时间内杀死骇客!它似乎与硬件有关,但是这里并没有增加…
他们的故事模式为何仍需要近一分钟的时间加载? (M.2并没有计算启动徽标。)此外,将故事加载到在线仅需要一分钟,而我要再获得五个。我知道他们的硬件规格要好很多,但肯定不会好5倍。
有了任务管理器之类的强大工具,我开始研究哪些资源可能成为瓶颈。
在花了一点时间加载用于故事模式和在线模式的通用资源(这与高端PC差不多)之后,GTA决定在我的计算机上最大化单个内核四分钟,并且什么也不做。
磁盘使用情况?没有!网络使用情况?有点,但是几秒钟后,它基本上降为零(除了加载旋转的信息横幅)。 GPU使用率?零。内存使用情况?完全平坦…
虽然我的旧AMD CPU有8核并且确实有很多用,但它是在较早的日子里制造的。当AMD的单线程性能落后于Intel的时候。这可能不能解释所有的加载时间差异,但是应该可以解释其中的大部分差异。
奇怪的是它只用完CPU。我期望大量磁盘读取会加载资源或网络请求负载,以尝试在p2p网络中协商会话。但是这个?这可能是一个错误。
探查器是查找CPU瓶颈的好方法。仅有一个问题-大多数问题都依赖于对源代码进行检测,以获得对过程中正在发生的事情的完美了解。而且我没有源代码。我也不需要微秒级的读数-我有4分钟的瓶颈。
输入堆栈采样:对于封闭源应用程序,只有一个选项。转储正在运行的进程的堆栈和当前指令指针的位置,以按设置的时间间隔构建调用树。然后将它们加起来以获取有关发生情况的统计信息。据我了解,只有一个分析器(在这里可能是无知的)可以在Windows上执行此操作。而且它已经十多年没有更新了。这是卢克·斯塔克沃克(Luke Stackwalker)!有人,请给这个项目一些爱:)
通常,卢克会将相同的功能归为一组,但是由于我没有调试符号,因此我不得不盯着附近的地址来猜测它是否在同一地方。我们看到了什么?不是一个瓶颈,而是两个!
借用了我朋友的行业标准反汇编程序的完全合法副本(不,我真的买不起这东西……这些日子之一,我要学习吉德拉),我去了GTA。
这根本不对。大多数引人注目的游戏都带有针对逆向工程的内置保护,可防止盗版,作弊和修改。并不是说它曾经阻止过他们。
这里似乎存在某种混淆/加密,已经用乱码代替了大多数指令。不用担心,我们只需要在执行我们要看的部分时转储游戏的内存即可。在以一种或另一种方式运行之前,必须对指令进行混淆处理。我周围有Process Dump,所以我使用了它,但是还有很多其他工具可用于执行此类操作。
拆开现在不太混乱的转储会发现,其中一个地址的标签被拉出了某个地方!好吃吗?在调用堆栈中,下一个标记为vscan_fn,此后标记结束,我相当有信心将其称为sscanf。
它正在解析某些内容。解析什么?解开拆解将永远花费时间,因此我决定使用x64dbg从正在运行的进程中转储一些样本。后来经过一些调试步骤,发现它是……JSON!他们正在解析JSON。带有约63k项的条目,价值高达10 MB的JSON。
...,{:" WP_WCT_TINT_21_t2_v9_n2&#34 ;,:45000,::" CHAR_KIT_FM_PURCHASE20&#34 ;,:" BITFIELD&#34 ;,:7,:1,::[" CATEGORY_WEAPON_MOD"]},...
它是什么?根据一些参考,它似乎是“网上商店目录”的数据。我认为它包含您可以在GTA Online中购买的所有可能物品和升级的列表。
但是10兆?没什么!而且使用sscanf可能不是最佳选择,但是肯定还不错吗?出色地…
是的,这将需要一段时间。。。公平地说,我不知道大多数被称为strlen的sscanf实现,所以我不能怪罪于编写此代码的开发人员。我认为它只是逐字节扫描,并且可以在NULL上停止。
原来第二名罪犯被称为第一个罪犯。就像在这个丑陋的反编译中看到的一样,它们都被称为相同的if语句:
第二个问题?解析项目后,它立即存储在数组(或内联的C ++列表?不确定)中。每个条目如下所示:
但是在存储之前?它逐一检查整个数组,比较项目的哈希值以查看其是否在列表中。输入约63k的(n ^ 2 + n)/ 2 =(63000 ^ 2 + 63000)/ 2 = 1984531500检查我的数学是否正确。他们大多数都没用。您有唯一的哈希,为什么不使用哈希映射。
我在反转时将其命名为hashmap,但显然不是not_a_hashmap。而且变得更好。加载JSON之前,hash-array-list-thing为空。而且JSON中的所有项目都是唯一的!他们甚至不需要检查它是否在列表中!它们甚至具有直接插入项目的功能!只需使用它! Srsly,WAT !?
现在一切都很好,但是除非经过我的测试,否则没人会把我当回事,以便为这篇文章写一个clickbait标题。
JSON问题比较棘手,我无法实际替换其解析器。用不依赖于strlen的sscanf替换sscanf更为现实。但是有一种更简单的方法。
如果在字符串范围内再次调用它,则返回缓存的值
size_t(char * str){static char * start;静态字符*结束; size_t len; const size_t cap = 20000; //如果我们有一个" cached"如果(start& str> = start&& str< = end){//计算新的strlen len = end-str; //如果我们快要结束了,请卸载自身//如果(len< cap / 2)MH_DisableHook((LPVOID)strlen_addr);我们不想弄乱其他东西//超快的回报! len返回} //计算实际长度// //我们至少需要对大型JSON进行至少一次测量//对于其他字符串,通常是正常的strlen len = builtin_strlen(str); //如果是真的很长的字符串// //保存它的开始和结束地址if(len> cap){start = str; end = str + len; } //缓慢而无聊的return return len; }
至于哈希数组问题,它更直接-完全跳过重复检查并直接插入项目,因为我们知道值是唯一的。
char __fastcall(uint64_t目录,uint64_t *键,uint64_t *项目){//不会打乱结构uint64_t not_a_hashmap = catalog + 88; //不知道这样做是什么,但是如果(!(*(uint8_t(__ fastcall **)(uint64_t *))(* item + 48))(item))返回0; //直接插入netcat_insert_direct(not_a_hashmap,key和& item); // //当最后一个项目的哈希被击中//时删除钩子//并卸载.dll,我们在这里完成:) if(* key == 0x7FFFD6BE){MH_DisableHook((LPVOID)netcat_insert_dedupe_addr);卸下(); } return 1; }
原始在线模式加载时间:固定为〜6m,仅包含重复检查补丁的时间:4m 30s仅包含JSON解析器补丁的时间:2m 50s具有两个补丁的时间:1m 50s(6 * 60-(1 * 60 + 50))/( 6 * 60)=缩短69.4%的加载时间(不错!)
最有可能的是,这并不能解决每个人的加载时间-不同系统上可能存在其他瓶颈,但这是一个巨大的漏洞,我不知道R *这么多年来一直错过了它。 如果某种方式到达了Rockstar:单个开发人员解决问题的时间不应超过一天。 请对此做一些事情:< 您可以切换到用于重复数据删除的哈希图,也可以在启动时完全跳过它作为更快的解决方案。 对于JSON解析器-只需将库换成性能更高的库即可。 我认为没有更简单的出路。