Django中的高效Postgres全文搜索
在本文中,我们将介绍如何在Django中使用基于内置自然语言的Postgres全文搜索。互联网用户在搜索方面变得越来越挑剔。当他们在您网站的搜索栏中输入关键字时,他们期望找到逻辑上排名较高的结果,包括相关的匹配项和拼写错误。
由于用户已经习惯了这些复杂的搜索系统,因此开发人员必须构建使用比简单的LIKE查询更多的应用程序。
从Postgres 8.3开始,可以使用Postgres全文搜索。它可以用于基于语言的语义和知识查找记录,而不是简单的字符串匹配,它非常灵活,并且与其他搜索选项(如LIKE)不同,它在部分匹配中表现良好。
虽然索引可以支持LIKE,但是当在搜索词的左侧使用%运算符时,通常无法很好地发挥作用。通常,这意味着使用以下通配符运算符时,查询计划器将还原为顺序扫描:
搜索多列时,您还需要付出额外的努力,因为需要使用LIKE分别查询每列。还有其他更灵活的选择,例如SIMILAR TO和POSIX正则表达式搜索,但是当您想捕获单词的不同变体(例如,“ jump”,“ jumps”,“ jumped, ”和“跳转”)。
由于LIKE和其他简单方法缺乏语言支持,并且无法处理单词的变体或排名,因此,直接在数据库中实现搜索时,Postgres全文搜索(FTS)通常是更好的选择。使用FTS,您的搜索将匹配该单词的所有实例,其复数形式以及该单词的各种时态。由于FTS捆绑在Postgres中,因此无需安装额外的软件,也无需使用第三方搜索提供商的额外费用。此外,所有数据都存储在一个地方,这降低了Web应用程序的复杂性。
本文将向您展示如何在原始PostgreSQL查询中使用全文搜索,以及如何使用Postgres驱动程序在Django中实现等效查询。在此过程中,您将看到Postgres提供的各种全文搜索方法的一些用例。
PostgreSQL为全文搜索提供了多种本机功能。在以下各节中,您将了解如何使用它们来“向量化”您的结果和搜索查询,以便您可以使用Postgres的全文搜索功能。
在使用FTS搜索文本或文档之前,您需要将其转换为可接受的数据类型,称为tsvector。要将纯文本转换为tsvector,请使用Postgres to_tsvector函数。此功能将原始文本缩小为一组词素,称为词素。
词素很重要,因为它们有助于匹配相关单词。例如,单词“满足”,“满足”和“满足”将转换为“满足”。这意味着对满足的搜索将返回包含其他任何术语的结果。停用词(例如“ a”,“ on”,“ of”,“ you”,“ who”等)会被删除,因为它们出现的频率太高而与搜索无关。 to_tsvector函数返回词素以及一个数字,该数字表示每个单词在文本中的位置。
请注意,该函数的输出取决于语言。您应该告诉PostgreSQL将文本视为英语(或存储结果的任何语言)。要将句子“必须在鲨鱼缸中追赶猴子的飞盘和伐木工人的幻想纪录片”转换为tsvector,请运行以下命令:
选择to_tsvector(“英语”,“飞碟和伐木工人的幻想纪录片,他们必须在鲨鱼缸中追赶猴子”)作为搜索;
这显示了每个单词的词根以及其在文本中的位置。例如,文本中的第二个词“幻想”一词已分解为词素“幻想”,因此您会看到“幻想”:2。
文本搜索系统具有两个主要组件:正在搜索的文本和正在搜索的关键字。对于FTS,必须将两个分量都矢量化。在上一节中,您已经了解了如何将可搜索的数据转换为tsvector,现在,您将看到如何将搜索字词矢量化为tsquery值。
Postgres提供了将文本字段转换为tsquery值的函数,例如to_tsquery,plainto_tsquery和phraseto_tsquery。搜索字词也可以与& (AND),| (OR),和! (NOT)运算符和括号可用于对运算符进行分组并确定其顺序。 to_tsquery将搜索词转换为令牌,并丢弃停用词。
返回词素“ beauti”和“ quick”,因为“ a”和“ very”是停用词:
既然您知道如何从文本数据创建tsvector和从搜索词创建tsquery,则可以使用@@运算符执行全文搜索。
如果您有一个包含电影标题和描述的电影表,则可以使用全文搜索查找所有描述,其中包含单词epic以及tale或story的电影:
对搜索结果进行排名可以确保首先显示最相关的结果。 Postgres提供了两个用于对搜索结果进行排名的功能:ts_rank和ts_rankcd。 ts_rank考虑单词的出现频率,而ts_rank_cd(“ cd”表示“覆盖密度”)则考虑搜索词在被搜索文本中的位置。
如果您运行以下查询,您会发现rank1和rank2的排名相同(0.06078271),因为每个搜索查询都在句子中找到一次:
SELECT ts_rank(to_tsvector(' english','海豚也要浇水,就像大象要去森林'),to_tsquery(' english',' elephant&#39 ;))AS rank1,ts_rank(to_tsvector(' english',' 39; dolphin'))AS rank2;
与文本匹配的令牌越多,排名越高。在下面的示例中,rank1的等级高于rank2,因为在句子中都找到了标记“ elephant”和“ dolphin”,而没有找到“ snake”:
选择ts_rank(to_tsvector(' english',Dolphin要浇水,就像大象要进入森林),to_tsquery(' english',' elephant& ))作为等级1,ts_rank(to_tsvector(' english','海豚要浇水,就像大象要去森林一样),to_tsquery(' english' ,' dolphin& snake')))AS rank2;
您还可以通过权衡一些因素使它们与其他因素相关。例如,当搜索电影表时,可以使用setweight函数将最高的权重赋予电影标题,而将较少的权重赋予描述:
---设置权重SELECT setweight(to_tsvector(' english',' elephant'),' A')|| setweight(to_tsvector(> english',' dolphin'),' B')AS权重; ---运行查询SELECT ts_rank(setweight(to_tsvector(' english',' elephant'),' A')|| setweight(to_tsvector(&#39 ; english',' B'),to_tsquery(' english',' elephant'))AS Elephant_rank, ts_rank(setweight(to_tsvector(' english',' elephant'),' A')|| setweight(to_tsvector(' english',& #39; dolphin'),' B'),to_tsquery(' english',' dolphin'))AS dolphin_rank;
Elephant_rank之所以排名较高,是因为与权重为B的dolphin_rank相比,它与权重为A的大象相匹配。
ts_rank采用可选的第一个参数weight。如果将此参数保留为空,则默认按D,C,B,A的顺序默认为“ {0.1,0.2,0.4,1.0}”。默认情况下,A的权重最高,为1.0,B的权重为0.4,C的权重为0.2 ,D的值为0.1。您可以使用-0.1到1.0之间的任意十进制将A,B,C或D中任何一个的权重设置为不同的值。这使您可以精确控制返回结果的方式,并确保用户看到正确的查询结果。
既然您已经了解了如何使用Postgres的全文本搜索功能,那么您就可以开始将这些想法应用到Django应用中了。
在Django中使用Postgres的全文本搜索是添加准确且快速的搜索的理想方法,因为它易于维护并且使用起来非常快捷。为了在Django中演示全文搜索,请考虑一个PostgreSQL数据库dvdrental,其中包含一个film表,并在实现如下的Django应用程序中具有一个等效的Film模型:
从Django .db导入Models类(模型.Model):film_id =模型.AutoField(primary_key = True)标题=模型.CharField(max_length = 255)描述=模型.TextField(空白= True,null = True)def __str__( self):返回&#39 ;、' .join([&#39film_id =' + str(self .film_id),' title =' + self .title,' description =' + self。描述 ] )
在本文的其余部分,您将看到如何搜索单个数据库表字段,搜索多个字段,对搜索结果进行排名以及如何使用矢量字段和索引优化全文本搜索的性能。您可以从Python Shell运行命令。
在Django中开始使用全文搜索的最简单方法是使用搜索查找。要在胶片模型上搜索描述列,请在过滤模型时在列名后附加__search:
>> >来自< appname> .models导入Film>> >电影对象。过滤器(description__search ='史诗般的故事')< QuerySet [< Film:film_id = 8,title =机场Pollock,description =驼鹿的史诗故事和一个必须面对古代猴子的女孩印度> ,<电影:film_id = 97,标题=新娘阴谋,描述=机器人和猴子的史诗故事,必须在新奥尔良征服一个人。 。 。 ]>
在后台,Django将description字段转换为tsvector并将搜索词转换为tsquery。您可以检查基础查询来验证这一点:
>> >连接.queries [0] [' sql' ](' SELECT" film_id&#34 ;、" film" .title&#34 ;、" film&#34 ;。#description",'电影" .release_year","电影&#34 ;. language_id&#34 ;、电影" .rental_duration",''电影"。&rental_rate&#34 ;、 #34;电影胶片"长度&#34 ;、电影胶片" .replacement_cost",''电影胶片&#34 ;。& 34&quot ;、电影"。" last_update","电影"。"特殊功能",&#39 ;" film" .fulltext"," film"。" index_column"," film"。 " vector_column" FROM" film"' WHERE to_tsvector(COALESCE(" film" .description&#34 ;, \& #39; \'))@@'" plainto_tsquery('史诗般的故事')LIMIT 21")
如果要单独使用tsvector,则可以使用Django SearchVector类。例如,要在标题和描述列中搜索“爱”一词,可以在Python Shell中运行以下命令:
>> >电影。对象。注释(搜索= SearchVector(' title',' description',config =' english')))。过滤器(search =' love')< QuerySet [<电影:film_id = 374,标题=涂鸦之爱,描述=不可思议的相扑摔跤手和猎人,必须在柏林建造作曲家&gt ; ,<电影:film_id = 448,标题=爱达荷·洛夫(Idaho Love),描述=必须在内陆地区与数据库管理员会面的学生和鳄鱼的快节奏戏曲> ,<电影:film_id = 458,标题= Indian Love,描述=疯狂科学家的疯狂传奇,以及必须在废弃的游乐园里杀死宇航员的疯狂科学家> ,<电影:film_id = 511,标题= Lawrence Love,描述=数据库管理员的幻想纱线和必须在柏林追逐女性化主义者的疯牛子> ,<电影:film_id = 535,标题=爱自杀,描述=必须在废弃的游乐园里追逐牙医的猎人和探险家的辉煌全景图> ,<电影:film_id = 536,标题=可爱的叮当,描述=鳄鱼的奇异纱线和必须在内陆发现鳄鱼的法医心理学家> ]>
检查基础查询时,可以看到Django如何使用to_tsvector来查询数据库中的title和description字段:
>> > pp(连接.queries [0] [' sql'])(' SELECT" film"。" film_id&#34 ;," film&#34 ;。"电影&#34 ;.说明",' to_tsvector(\'英语\ :: regconfig,COALESCE(" film" .title&#34 ;, \' \')|| \' \'&#39 ;' || COALESCE(" film" .description&#34 ;, \' \'))AS" search" FROM& #34; film" WHERE' to_tsvector(\' english \' :: regconfig,COALESCE(" film" .title&# 34 ;, \' \')|| \' \'' || COALESCE(" film"。&#34 ; description&#34 ;, \' \'))@@'" plainto_tsquery(' english' :: regconfig,' love' )LIMIT 21")
SearchQuery是Postgres中to_tsquery,plainto_tsquery和phraseto_tsquery函数的抽象。有几种使用SearchQuery类的方法,包括在搜索中使用两个关键字:
与SearchVector不同,SearchQuery支持布尔运算符。布尔运算符使用Postgres中的逻辑使用逻辑组合搜索词:
在搜索中一起使用SearchVector和SearchQuery可以使您在Django中创建功能强大的自定义搜索:
>> > vector = SearchVector(&title"标题'; config =' english')#搜索标题和描述列。 > query = SearchQuery("(' epic' |' beautiful' |' brilliant')&(' tale' |&# 39; story')",search_type =" raw")#.. >电影.object .annotate(search = vector)。过滤器(search = query)< QuerySet [<电影:film_id = 8,标题=机场波洛克,描述=在古代印度必须面对猴子的驼鹿和女孩的史诗故事> ,<电影:film_id = 30,标题= Anything Savannah,描述=史诗般的糕点师傅和女人,她必须在废弃的游乐园里追逐女权主义者> ,<电影:film_id = 46,标题=秋天的乌鸦,描述=必须在撒哈拉沙漠中与麋鹿作斗争的牙医和疯牛的美丽故事> ,<电影:film_id = 97,标题=新娘阴谋,描述=机器人和猴子的史诗故事,必须在新奥尔良征服一个人。 ,<电影:film_id = 196,标题=残酷不可原谅,描述=在尼日利亚必须与牙医搏斗的汽车和驼鹿的辉煌故事> ,<电影:film_id = 202,标题= Daddy Pittsburgh,描述=《史诗般的鲨鱼和学生必须面对墨西哥湾探险家》。 。 。 。 ]>
使用SearchVector和SearchQuery生成Django中的全文搜索查询是一个很好的开始,但是强大的搜索功能也可能需要自定义排名。可以使用SearchRank类在Django应用中对搜索结果进行排名。
>> >从django .contrib .postgres .search导入SearchQuery,SearchRank,SearchVector>> > vector = SearchVector(" title',' description',config =' english')>> > query = SearchQuery("(' epic' |' beautiful' |' brilliant')&(' tale' |&# 39; story')",search_type =" raw")>> >电影.object .annotate(rank = SearchRank(vector,query)).order_by(' -rank')
>> >向量= SearchVector(&title),权重=' A')+ SearchVector('说明',配置=' english',权重=& #39; B')>> > query = SearchQuery("(' epic' |' beautiful' |' brilliant')&(' tale' |&# 39; story')",search_type =" raw")>> >电影.object .annotate(rank = SearchRank(vector,query)).order_by(' -rank')
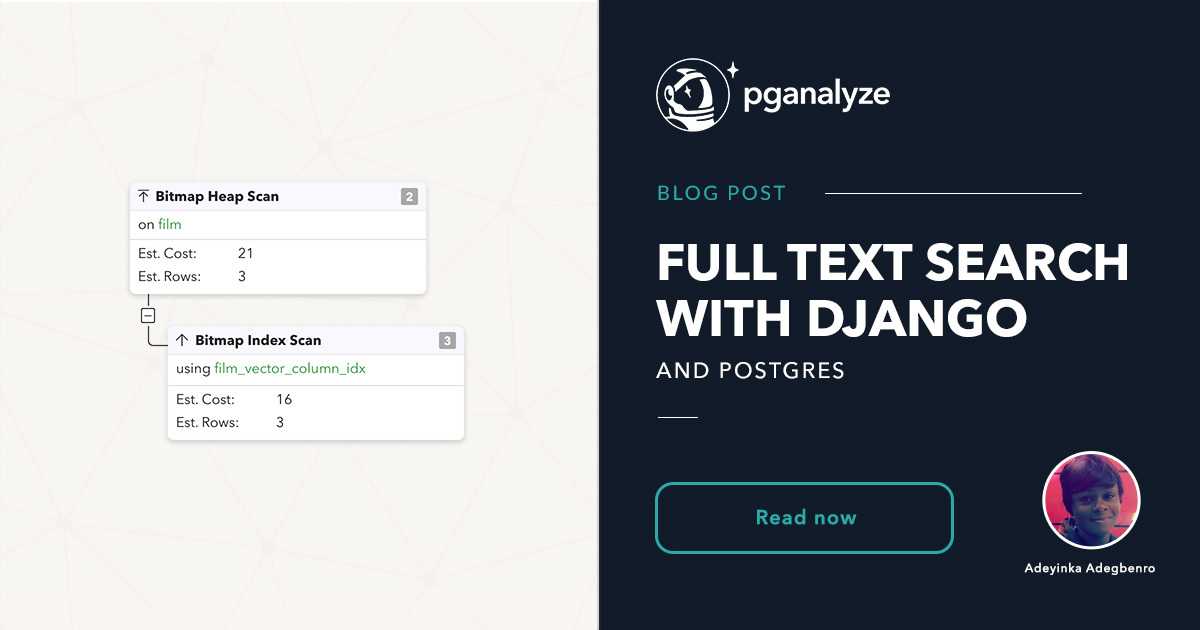
为了从Postgres全文搜索中获得最佳性能,您需要创建一个可以存储tsvector数据类型的索引列。在此新列上执行搜索的速度要比使用SearchVector动态生成tsvector快几个数量级。如果文本已预先转换并存储在列中,则无需进行运行时转换。
要在Django中实现这一新列,您需要将SearchVectorField类添加到模型中。要对该字段建立索引,请按照PostgreSQL全文搜索的建议使用GIN索引。
PostgreSQL提供了两个主要索引来加速全文搜索:GIN(通用倒排索引)和GIST(通用搜索树)。 GIST索引的建立速度更快,并且对于频繁更新的字段很有用,但它可能是有损的(即有时会返回误报)。 GIN仍具有很高的可扩展性,虽然它没有损耗,但它不允许您存储权重。在此处了解有关它们之间的差异和用例的更多信息。
要将此字段和索引添加到模型中,请使用GinIndex和SearchVectorField类,如下所示:
从django .db导入从django .contrib .postgres .search导入模型title =模型.CharField(max_length = 255)描述=模型.TextField(空白= True,null = True)vector_column =模型.SearchVectorField(null = True)#新字段def __str__(self):返回&#39 ;,& #39; .join([&#39film_id =' + str(self .film_id),' title =' + self .title,' description =' + self。描述])类索引=(GinIndex(fields = [" vector_column"]),)#添加索引
接下来,您需要一种方法来确保随时更新Film表上的title和description字段时,都会自动计算并存储vector_column字段。为此,您可以使用PostgreSQL触发器。
由于无法直接在Django模型中使用触发器,因此请在新的迁移文件中添加SQL命令:
打开自动生成的文件,并添加由UPDATE命令设置的触发器。此触发器为新行和现有行计算vector_column字段:
从django .db导入迁移类(migrations .Migration):依赖关系= [('< your_app_name>',' 0002_auto_20210224_0325'),]操作= [迁移.RunSQL(sql = '''在插入或更新标题,描述,vector_column胶片之前,在每个行执行过程中创建触发器vector_column_trigger(ts_vector_update_trigger(vector_column,' pg_catalog.english' );更新电影SET vector_column = NULL;''',reverse_sql ='''如果存在则触发DROP TRIGGER vector_column_trigger ON film;'&# 39;'),]
现在,您的数据库应该有一个名为vector_column的新列,其中包含每部电影的标题和描述的索引tsvector。
运行Postgres 12或更高版本? 您可以通过以下方式创建列,从而利用生成列功能来避免使用触发器来更新tsvector列: ALTER TABLE影片添加COLUMN vector_column tsvector总是以(设置权重(to_tsvector(' english'),coalcece(title,'')),' A') setweight(to_tsvector(' english',合并(description,'')),' B'))ST ......