机器学习模型缺少合同
设计软件的一种有用方法是通过合同。对于代码库中的每个功能,您都需要先编写其约定:明确指定该功能的预期输入和有效输入(前提条件),以及提供适当输入后该功能将执行的操作(背面条件)。这通常在函数的文档字符串中明确说明。考虑一下来自Python(用C实现)的math模块中的示例:
该合同功能强大,因为在发布代码时,其他开发人员无需自己测试功能,也无需考虑其内部实现。他们可以读取该功能的有效输入范围并立即开始使用。相反,他们知道如果不满足先决条件,那么后任条件都不得到保证。
如今,经过预训练的机器学习模型正越来越多地作为功能和API部署。它们是公司内部代码库[1]的一部分,已在外部发布以通过API使用[2],并且在研究中,预训练的模型已作为审阅和可重复性过程的一部分发布[3]。
预训练模型本质上是一个函数:它接收特定的输入样本并作为输出进行预测。作为这些模型的用户,我们需要知道哪些数据可以有效地输入模型中,哪些数据可能导致不可靠的预测。通常,用所有可能的数据自己测试模型是不可行的,并且不可能检查内部实现,因此,如果我们为合同提供了有效输入数据的明确规范,则可以立即自信地开始使用模型。但是,为机器学习模型指定“有效数据”要比听起来困难得多。让我们考虑一些挑战,以公开发布的模型为例,这些挑战全部取材于今年的NeurIPS会议:在麻省理工学院的这篇论文中,作者收集了丰富的随时间记录的风暴事件卫星图像数据集。有益的是,作者还向社区发布了该数据集上的一些预训练模型。
我尝试使用一种预训练的临近预报模型(用于预测下一个小时的风暴运动模式),方法是将作者自己的数据集中的卫星图像输入模型,然后开始进行毫无意义的预测。用不同的方式对图像进行归一化似乎没有帮助。我追溯了作者提供的示例jupyter笔记本,并看到了以下代码行:
事实证明,应该以一种非常特定的方式对输入图像中的某些通道进行重新缩放,以使模型产生合理的输出。尽管此信息对于模型的正常运行至关重要,但并未以任何方式将其与预训练模型打包在一起。在这种情况下(通常是这种情况),即使数据未正确缩放,模型也不会引发任何错误。它杂乱无章地进行着,做出了荒谬的预测,让我自己意识到有些事情是错误的。
与输入数据的预处理有关的信息应包含在预训练模型的文档中;否则,我们需要自己弄清楚如何准备用于推理的数据。但是至少可以想象这些预处理细节可以包含在技术文档中。有时候,不只是预处理...
就像我们将看到的那样,第三个示例特别有问题,因为很难预先指定模型可以接受哪种图像以及在哪里失败。作者发布了一种最新的超分辨率模型,该模型接受图像的低分辨率或标准分辨率,并输出高分辨率版本。这是已发布的预训练模型运行良好的示例:
多么奇怪!我当然不希望这幅蓝色图像成为最新的超分辨率模型的输出。当然,使用用于锐化图像的经典图像处理算法不会发生这种故障模式。但是对于这种机器学习模型,我们对内部实现一无所知,而且由于没有合同,因此我们不知道可以信任该模型的图像!
在花费了数小时的时间来处理模型后,我无法弄清楚模型可以正确解析哪些图像,哪些图像可以产生这些奇怪的蓝色输出。由于该模型缺少合同,因此在工程上浪费了很多时间:我花了大量时间在本地加载和运行模型,只是意识到它不适用于我的某些数据。
我们机器学习开发人员经常认为,如果我们能够在测试集上获得良好的性能,那么我们的模型就可以部署和发布了。我们对下游用户如何使用带有看起来可能与我们的训练和测试集看起来完全不同的数据的模型不够关注。但是,这种情况越来越多:随着机器学习模型以通用API的形式发布或在内部部署,但是数据流随时间变化,我们不能再假设模型的测试性能可以指示其性能在现实世界。
我们需要提供合同,以使用户清楚哪些输入数据对我们的模型有效。否则,机器学习模型将正常运行,直到无法运行。建立在机器学习模型之上的系统将失败。
同时,我们已经发现很难通过明确的指令来指定有效的输入数据。该怎么办?我有两个建议:
我们开发了更好的方法来确定样本是否属于我们模型的“有效数据分布”。合同本身可能就是“合同功能”,如果输入样本与我们的培训分布“足够”相似,它会评估输入样本是否有效。正在开发这种用于检测分布内和分布外数据的方法[4],尽管在实践中使用它们时有一些注意事项[5]。
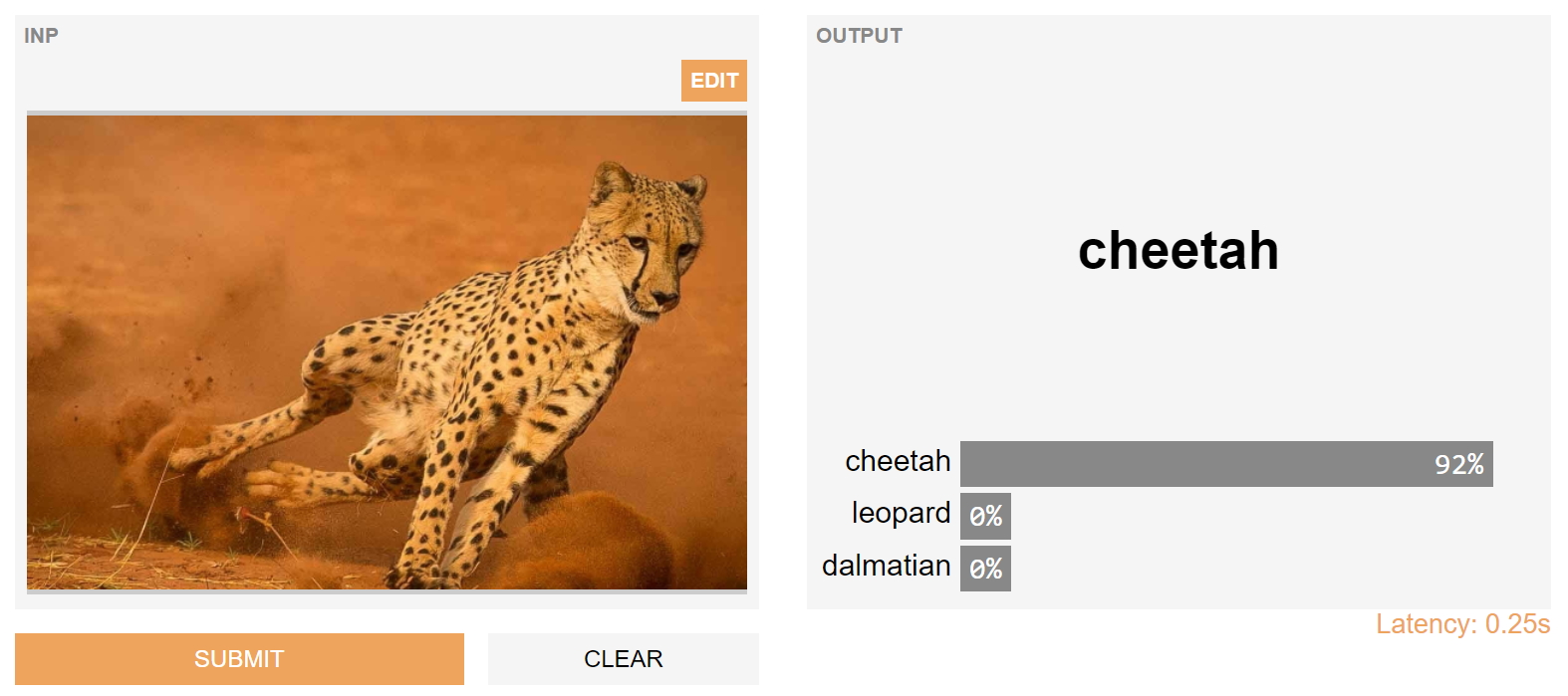
我们使测试模型变得更加容易,以便在模型开发过程中更轻松,更早地识别出模型故障。 这有助于模型创建者了解并传达其库的前提条件,并帮助最终用户快速了解模型是否适合其使用。 这是我们的开源gradio库背后的动机。 实际上,上述模型中确定的故障点都可以通过库轻松完成。 当然,我们可以同时采用这两种解决方案-我们使识别模型故障点变得更加容易,但同时也为开发机器学习模型投入了合同功能。