Cloudflare的ClickHouse容量评估框架
我们在Cloudflare上广泛使用ClickHouse。它帮助我们处理内部分析工作负载、BOT管理、客户仪表盘和许多其他系统。例如,在Bot Management能够对我们的流量进行分析和分类之前,我们需要收集日志。防火墙分析工具也需要在某个地方存储和查询数据。同样的道理也适用于我们新的云晕雷达项目。我们正在使用ClickHouse来实现这一目的。这是一个可以存储海量数据并按需返回的大型数据库。这不是我们第一次谈论ClickHouse了,有一篇专门的博文介绍了我们是如何引入ClickHouse进行HTTP分析的。
我们最大的集群有100多个节点,另一个大约是这个数字的一半。除此之外,我们有20多个群集,它们至少有三个节点,复制系数为三。我们目前的插入速度约为每秒9000万行。
我们在ClickHouse架构设计中使用标准方法。在顶层,我们有集群,其中包含碎片、一组节点,节点是一台物理机。您可以在此处找到节点的技术特征。存储的数据在群集之间复制。不同的分片保存不同的数据部分,但每个分片副本的内部是相同的。
作为工程师,我们经常面临这样的问题:我们必须订购多少额外的节点才能支持未来X个月不断增长的需求,而磁盘空间是我们最关心的问题。
ClickHouse在系统表中存储了有关操作过程的大量信息,这很有帮助。从使用ClickHouse的早期开始,我们就添加了Clickhouse_Exporter作为监控堆栈的一部分。我们感兴趣的指标之一是从System.Parts表中公开的。粗略地说,clickhouse_exporter运行SQL查询,询问每个表使用了多少字节。之后,这些指标将从普罗米修斯送到塔诺斯,并保存至少一年。
每次我们想要预测磁盘使用情况时,我们都会使用下面的表达式查询Thanos的历史数据:
这种方法存在一些问题。只有几个人知道笔记本在哪里,以及如何让它们运行。下载历史数据绝非易事。最重要的是,很难查看过去的预测并评估它们是否正确,因为结果除了内部博客帖子外没有存储在任何地方。此外,随着集群和产品的数量和规模的增长,单个团队不可能进行容量规划,我们需要让工程师参与到产品开发中来,因为他们对未来的增长将如何变化有最深入的了解。
我们希望将这一过程自动化,并使计算对我们的同事更加透明,包括那些使用ClickHouse提供服务的同事。老实说,一开始我们甚至不确定这是否可能,以及我们能从中得到什么。
对于我们来说,添加新节点的关键时刻是磁盘空间,因此这是一个开始。我们决定使用System.Parts,就像我们以前在手动方法中使用的一样。
幸运的是,我们开始为最近更改了拓扑的集群这样做。该集群有两个分片,每个分片中有四个和五个节点。拓扑改变后,它被替换为三个分片和每个分片中的三个节点,但机器数量和磁盘上未复制的数据保持不变。然而,它对我们的指标产生了影响:我们之前在一个碎片中有四个复制节点,在另一个碎片中复制了五个节点,我们从第一个碎片中删除了一个节点,从第二个碎片中删除了两个节点,并基于这三个节点创建了一个新的节点。新的分片是空的,所以我们只是添加了它,但是第一个和第二个分片中的数据总量比剩余节点的数量要少。
您可以在下图中看到,由于拓扑结构的变化,我们在4月份出现了这种急剧下降。在所有碎片和复制品中,我们得到了~550吨,而不是~850吨。
当我们试图根据4月份下跌的真实数据来训练我们的模型时,它认为我们有下降的趋势。这是不正确的,因为我们只删除了复制的数据。未复制数据的趋势没有改变。因此,我们决定只考虑未复制的数据。它省去了在硬件出现问题时更改拓扑和更换节点的麻烦。
SUM BY(CLUSTER)(max BY(CLUSTER,Shardgroup)(node_clickhouse_shardgroupinfo{}*on(实例)GROUP_RIGHT(CLUSTER,Shardgroup)SUM(TABLE_PARTS_BYTES{CLUSTER=";%s";})BY(INSTANCE)。
我们继续使用clickhouse_exporter中的system.part,但是我们使用的不是整个数据量,而是每个分片中未复制数据的最大值。
在下图中,有与上图相同的集群,但我们查看的不是整个数据量,而是来自所有碎片的未复制数据。你可以清楚地看到,我们继续增长,数据没有任何下降。
我们面临的另一个问题是,我们将一些表从一个集群迁移到另一个集群,因为我们的空间快用完了,需要立即采取行动。然而,我们的模型不知道部分表格不再存在,我们不希望它们成为预测的一部分。为了解决这个问题,我们查询普罗米修斯以获得预测时存在的表的列表,然后过滤历史数据以仅包括这些表,并使用它们作为训练模型的输入。
在确定正确的指标之后,我们需要为我们的预测过程获取这些指标。我们的长期指标解决方案Thanos存储着数十亿个数据点。查询一个拥有100多个节点的集群,即使是一天也需要大量的时间,我们需要这些数据点一年之久。
因为我们计划使用Python,所以我们使用aiohttp编写了一个小客户端,该客户端同时向Thanos发送HTTP请求。请求以块形式发送,每个请求的开始/结束日期相差一个小时。我们需要一次获得全年的数据,然后逐日追加新的数据。我们有CSV文件:一个集群一个文件。客户端成为项目的一部分,它每天运行一次,向Thanos查询新的指标(前一天),并将数据附加到文件中。
至此,我们已经收集了文件中的指标,现在是做出预测的时候了。我们需要一些时间序列度量的东西,所以我们选择了Facebook的Prophet。它使用起来非常简单,您可以按照文档说明操作,即使使用默认参数也能获得很好的结果。
我们使用Prophet时面临的一个挑战是每天需要向它提供一个数据点。在公制文件中,我们每天都有数千个这样的数据。在每一天结束时接受这一点看起来很合乎逻辑,但这并不是真的。所有表格都有保留期,即我们在ClickHouse中存储数据的时间。我们不知道数据何时被清除,它在一天中逐渐发生。因此,我们决定采取最大数量的一天。
我们选择Grafana来显示结果,尽管我们需要将预测的数据点存储在某个地方。最初的想法是使用普罗米修斯(Prometheus),但由于基数很高,我们对集群和表总共有大约30万分,所以我们通过了。我们决定使用ClickHouse本身。我们希望在同一个仪表盘上同时显示真实和预测的图表。我们在普罗米修斯有真实的数据点,混合数据源可以做到这一点。然而,这个问题与将指标加载到文件中是一样的,对于某些集群来说,在很长一段时间内都不可能获得指标。我们还在ClickHouse中添加了上传真实指标的功能,现在真实指标和预测指标都显示在Grafana中,取自ClickHouse。
我们有一个在Kubernetes中运行的服务来完成所有的工作,我们还为其他指标创建了一个环境。我们可以从Thanos收集指标,并以所需的格式将它们公开给Grafana。如果我们找到了计算IO、CPU或其他系统(如Kafka)等其他资源的正确指标,我们就可以很容易地将它们添加到我们的框架中。我们可以很容易地用另一种算法取代Prophet,我们可以回到几个月前,根据真实数据评估我们的预测有多接近。
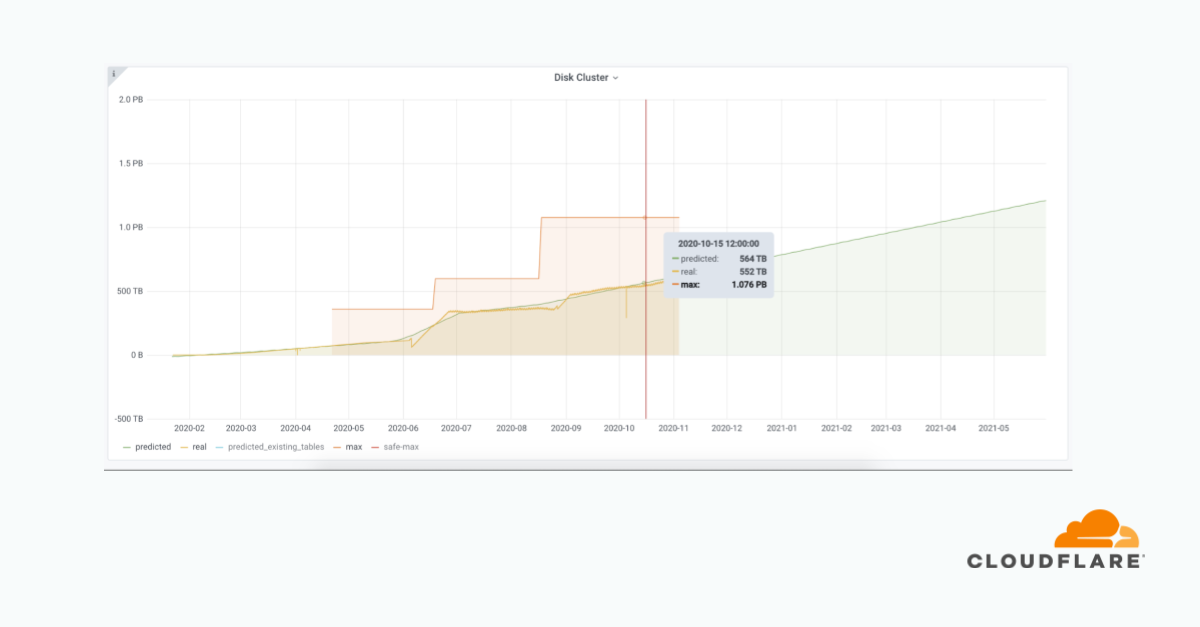
有了这种自动化,我们能够发现我们的磁盘空间即将耗尽,因为有几个集群是我们意想不到的。我们有20多个集群,每天都有更新。这个仪表盘不仅供ClickHouse的直接客户同事使用,也供制定购买服务器计划的团队使用。它很容易阅读,而且不会花费任何开发人员的时间。
这个项目是由Core SRE团队实施的,目的是改善我们的日常工作。如果你对这个项目感兴趣,请查看我们的职位空缺。
我们不知道最后会得到什么,我们讨论、寻找解决方案,并尝试了不同的方法。非常感谢尼古拉·瓦托洛米、亚历克斯·塞米格拉佐夫和约翰·斯科皮斯。
Analytics Bot Management Dashboard ClickHouse