名称不是类型安全的
Haskell程序员花了大量时间讨论类型安全。程序构造的哈斯克尔学派主张“捕获类型系统中的不变量”和“使非法状态不可表示”,这两个听起来都是令人信服的目标,但在实现这些目标所使用的技术上却相当模糊。几乎就在一年前,我出版了“解析,不要验证”(Parse,Don‘t Validation)一书,作为弥合这一鸿沟的初步尝试。
随后的讨论在很大程度上是富有成效的和正确的,但一个特别的困惑来源很快就变得清晰起来:哈斯克尔的新型结构。这个想法非常简单--newtype关键字声明了一个包装器类型,名义上与它包装的类型不同,但在表示上等同于它所包装的类型-从表面上看,这听起来像是一条通向类型安全的简单而直接的路径。例如,您可以考虑使用Newtype声明来定义电子邮件地址的类型:
这项技术可以提供一些价值,当与智能构造函数和封装边界结合使用时,它甚至可以提供一些安全性。但是,与我一年前强调的类型安全相比,它是一种有意义的截然不同的类型安全,它要弱得多。就其本身而言,新型只是一个名称。
为了说明构造性数据建模(在我上一篇博客文章中详细讨论)和Newtype包装器之间的区别,让我们考虑一个示例。假设我们需要一个“介于1和5之间(包括1和5)的整数”类型。自然的构造性建模将是具有五种情况的枚举:
ToOneToFive::Int->;可能OneToFive::OneToFive 1=只有一个到OneToFive 2=只有两个到OneToFive 3=只有三个到OneToFive 4=只有四个到OneToFive 5=只有五个到OneToFive_=没有任何来自OneToFive::OneToFive->;Int;Int FromOneToFive 1=1 FromOneToFive 2=2 FromOneToFive 3=3 FromOneToFive 5=4 FromOneToFive->;Int;Int FromOneToFive 1=1 from OneToFive 2=2 from OneToFive 3=3 from OneToFive 4=4 from OneToFive=5。
对于实现我们声明的目标,这将是完全足够的,但是您会发现它很奇怪,这是情有可原的:在实践中使用它将是相当尴尬的。因为我们发明了一种全新的类型,所以不能重用Haskell提供的任何常用数值函数。因此,许多程序员会倾向于使用新型包装器,而不是:
ToOneToFive::Int->;可能OneToFive到OneToFive n|n>;=1&;&;n<;=5=仅$OneToFive n|否则=OneToFive::OneToFive->;Int FromOneToFive(OneToFive N)=n。
如果我们将这些声明放在它们自己的模块中,并选择不导出OneToFive构造函数,这些API可能看起来完全可以互换。天真的是,新型版本似乎既更简单,又同样是类型安全的。然而,也许令人惊讶的是,这实际上并不是真的。
要了解原因,假设我们编写了一个使用OneToFive值作为参数的函数。在构造性建模下,这样的函数只需要对五个构造器中的每一个进行模式匹配,GHC将接受该定义为详尽的:
序数::OneToFive->;text序数一=";第一";序数二=";第二";序数三=";第三";序数四=";第四";序数五=";第五";
对于NewType编码,情况并非如此。Newtype是不透明的,因此观察它的唯一方法是将其转换回Int-毕竟,它是Int。Int当然可以包含除1到5之外的许多其他值,因此我们被迫添加错误情况以满足穷举检查器的要求:
序号::OneToFive->;text序号n=case from OneToFive n of 1-&>;";第一";2->;";第二";3->;";第三";4->;";第四";5->;";第五";_->;错误";错误";不可能:OneToFive值";
在这个精心设计的示例中,这对您来说可能不是什么大问题。但尽管如此,它还是说明了这两种方法提供的保障的关键区别:
构造性数据类型以下游用户可以访问的方式捕获其不变量。这将我们的序号函数从处理非法值的烦恼中解放出来,因为它们已经变得无法表达。
Newtype包装提供了验证值的智能构造函数,但该检查的布尔结果仅用于控制流;它不会保留在函数的结果中。因此,下游消费者不能利用限制域;他们在功能上接受Int。
丢失穷举检查似乎是小菜一碟,但它绝对不是:我们对错误的使用直接在我们的类型系统上打了一个洞。如果我们向OneToFive数据类型添加另一个构造函数,1使用构造数据类型的Ordial版本将在编译时立即检测到非穷举,而使用Newtype包装器的版本将继续编译,但在运行时失败,一直到“不可能”的情况。
所有这些都是因为构造建模本质上是类型安全的;也就是说,安全属性是由类型声明本身强制执行的。非法的值确实是不可表示的:根本没有办法使用五个构造函数中的任何一个来表示6。Newtype声明则不是这样,它与Int没有内在的语义区别;它的含义是通过toOneToFive智能构造函数从外部指定的。任何Newtype意图的语义区别对于类型系统来说都是完全不可见的;它只存在于程序员的头脑中。
我们的OneToFive数据类型相当人为,但是相同的推理适用于其他明显更实用的数据类型。考虑一下我在最近的博客文章中反复强调的非Empty数据类型:
设想将NonEmpty的一个版本表示为普通列表上的新类型可能是说明性的。我们可以使用通常的智能构造函数策略来强制执行所需的非空属性:
Newtype NonEmpty a=NonEmpty[a]NonEmpty::[a]->;可能(NonEmpty A)NonEmpty[]=Nothing NonEmpty Xs=Just$NonEmpty Xs实例可折叠非空,其中toList(NonEmpty Xs)=Xs。
就像使用OneToFive一样,我们很快就会发现未能在类型系统中保留此信息的后果。我们对NonEmpty的激励用例是能够编写安全版本的Head,但是Newtype版本需要另一个断言:
Head::NonEmpty a->;a Head Xs=case to List Xs of x:_->;x[]->;错误";不可能:空的非空值";
这可能看起来不是什么大事,因为这样的情况似乎不太可能发生。但是,这种推理完全取决于信任定义NonEmpty的模块的正确性,而构造性定义只需要信任GHC类型检查器。由于我们通常相信类型检查器工作正常,因此后者是一个更有说服力的证据。
如果你喜欢新的类型,这整个争论可能看起来有点麻烦。我似乎是在暗示新类型并不比注释好多少,尽管注释恰好对类型检查器有意义。幸运的是,情况并不是很严峻-新类型可以提供一种安全,只是一种较弱的安全。
新类型的主要安全优势来自抽象边界。如果未导出NewType的构造函数,则它对其他模块变得不透明。定义NewType的模块(它的“主模块”)可以利用这一点来创建信任边界,在该边界中,通过将客户端限制为安全的API来实施内部不变量。
我们可以使用上面的NonEmpty示例来说明这是如何工作的。我们避免导出NonEmpty构造函数,而是提供我们相信实际上永远不会失败的Head和Tail操作:
模块Data.List.NonEmpty.Newtype(NonEmpty,cons,NonEmpty,Head,Tail)其中Newtype NonEmpty a=NonEmpty[a]cons::a->;[a]->;NonEmpty a cons xxs=NonEmpty(x:xs)NonEmpty::[a]->;可能(NonEmpty A)NonEmpty[]=Nothing NonEmpty xs=Just$NonEmpty Xs Head::NonEmpty a->;A Head(NonEmpty(x:_))=x Head(NonEmpty[])=错误";不可能:空非空值";Tail::NonEmpty a->;[a]Tail(NonEmpty(_:xs))=Xs Tail(NonEmpty[])=错误";不可能:空非空值";
由于构造或使用NonEmpty值的唯一方法是使用Data.List.NonEmpty.Newtype的导出API中的函数,因此上述实现使得客户端不可能违反非空不变量。从某种意义上说,不透明的新类型的值就像令牌:实现模块通过其构造函数发布令牌,而这些令牌没有内在价值。要对它们做任何有用的事情,唯一的方法是将它们“赎回”到发布模块的访问器函数,在本例中是head和ail,以获取其中包含的值。
这种方法比使用构造数据类型弱得多,因为理论上有可能搞砸并意外地提供一种方法来构造无效的NonEmpty[]值。因此,类型安全的新型方法本身并不构成所需不变量成立的证明。但是,它限制了定义模块可能出现不变违规的“表面积”,因此,通过使用模糊或基于属性的测试技术彻底测试模块的API,可以获得不变量确实具有的合理置信度。2个。
这种权衡可能看起来并不是那么糟糕,事实上,它往往是非常好的!使用构造性数据建模来保证不变量通常是相当困难的,这通常使其不切实际。然而,很容易严重低估避免意外提供允许违反不变量的机制所需的谨慎。例如,程序员可以选择利用GHC方便的类型类派生来派生NonEmpty的泛型实例:
这是一个特别极端的例子,因为派生的泛型实例从根本上破坏了抽象,但是这个问题也可能以不太明显的方式突然出现。派生的Read实例也会出现同样的问题:
对于一些读者来说,这些陷阱可能看起来很明显,但这种安全漏洞在实践中非常常见。对于具有更复杂的不变量的数据类型尤其如此,因为可能不容易确定模块的实现是否实际支持这些不变量。正确使用这项技术需要谨慎和小心:
所有不变量必须清楚地告知可信模块的维护人员。对于简单类型(如NonEmpty),不变量是不言而喻的,但对于更复杂的类型,注释不是可选的。
必须仔细审核可信模块的每个更改,以确保它不会以某种方式削弱所需的不变量。
需要纪律来抵制添加不安全陷门的诱惑,如果使用不当,这些陷门可能会危及不变量。
可能需要定期重构以确保可信表面积保持较小。随着时间的推移,受信任模块的责任很容易积累,从而极大地增加了一些微妙的交互导致不变违规的可能性。
相比之下,通过构造而正确的数据类型不会遇到这些问题。在不更改数据类型定义本身的情况下,不能违反不变量,这会在整个程序的其余部分产生连锁反应,使结果立即变得清晰。程序员没有必要遵守规则,因为类型检查器会自动强制执行不变量。这样的数据类型没有“可信代码”,因为程序的所有部分都同样受制于数据类型强制约束。
在库中,由Newtype提供的通过封装实现的安全性概念非常有用,因为库通常提供用于构建更复杂数据结构的构建块。这类库通常比应用程序代码受到更多的检查和关注,特别是考虑到它们的更改频率要低得多。在应用程序代码中,这些技术仍然有用,但是随着时间的推移,产品代码库的混乱往往会削弱封装边界,因此只要可行,就应该优先使用构造的正确性。
上一节介绍了新类型有用的主要方式。然而,在实践中,新类型的常规使用方式不符合上述模式。一些这样的用途是合理的:
Haskell的类型类一致性概念将每个类型限制为任何给定类的单个实例。对于允许多个有用实例的类型,新类型是传统的解决方案,这可以取得很好的效果。例如,Data.Monoid中的Sum和Product新类型为数值类型提供了有用的Monoid实例。
同样,新类型对于引入或重新排列类型参数也很有用。Flip Newtype from Data.Bifunctor.Flip是一个简单的示例,它翻转Bifunctor的参数,以便函数器实例可以在另一端操作:
由于Haskell(目前)还不支持类型级别的lambdas,因此需要使用新类型来处理这类问题。
更简单地说,当值需要在程序的远程部分之间传递并且中间代码没有理由检查值时,透明的新类型对于防止误用非常有用。例如,可以将包含密钥的ByteString包装在NewType中(省略Show实例),以防止代码意外记录或以其他方式公开它。
所有这些应用程序都很好,但它们与类型安全关系不大。为了安全起见,最后一个项目常常被混淆,而且公平地说,它实际上确实利用了类型系统来帮助避免逻辑错误。然而,声称这样的使用实际上防止了误用将是一个错误的描述;程序的任何部分都可能在任何时候检查该值。
太多时候,这种安全的错觉导致了彻底的新型滥用。例如,下面是我工作的代码库中的一个定义:
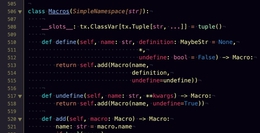
Newtype ArgumentName=ArgumentName{unArgumentName::GraphQL.。名称}派生(Show,Eq,FromJSON,ToJSON,FromJSONKey,ToJSONKey,Hasable,ToTxt,Lift,Generic,NFData,Cacheable)。
这种新型的噪音是无用的。在功能上,它完全可以与其底层名称类型互换,以至于它派生了十几个类型类!在使用它的每一个位置,一旦它从封闭的记录中提取出来,它就会立即打开,所以没有任何类型安全好处。更糟糕的是,将其标记为ArgumentName甚至没有增加任何清晰度,因为包含的字段名已经清楚地说明了它的作用。
这样的新类型似乎是由于希望将类型系统用作外部世界的分类法而产生的。“参数名称”是一个比通用“名称”更具体的概念,因此它当然应该有自己的类型。这有一定的直觉意义,但却相当误导:分类法对于记录感兴趣的领域很有用,但不一定对建模有帮助。在编程时,我们将类型用于不同的目的:
首先,类型区分值之间的功能差异。类型为NonEmpty a的值与类型为[a]的值在功能上是不同的,因为它在结构上完全不同,并且允许其他操作。从这个意义上说,类型是结构化的;它们描述了编程语言内部世界中的值。
其次,我们有时使用类型来帮助自己避免犯逻辑错误。我们可能会使用单独的距离和持续时间类型,以避免意外地做一些无意义的事情,比如将它们加在一起,即使它们都是代表实数的数字。
请注意,这两种用法都是实用的;它们将类型系统视为一种工具。这是一个相当自然的观点,因为静态类型系统是字面意义上的工具。然而,这种观点似乎出人意料地不同寻常,尽管使用类型对世界进行分类通常会产生像ArgumentName这样无益的噪音。
如果一个新类型是完全透明的,并且经常随意地进行包装和解包,那么它可能不会有太大帮助。在本例中,我将完全消除区别并使用name,但在不同标签增加真正清晰度的情况下,可以始终使用类型别名:3。
像这样的新人是安全毯。强迫程序员跳过几个圈子不是典型的安全-相信我,当我说他们会毫不犹豫地愉快地跳过这些圈子的时候。
我想写这篇博文已经很久了。从表面上看,这是对哈斯克尔新类型的非常具体的批评,我之所以选择这样的框架,是因为我写哈斯克尔是为了谋生,而这就是我在实践中遇到这个问题的方式。不过,实际上,核心理念远不止于此。
新类型是定义包装类型的一种特殊机制,这个概念几乎存在于任何语言中,甚至包括那些动态类型的语言。即使您没有编写Haskell,这篇博客文章中的大部分推理可能仍然与您选择的语言相关。更广泛地说,这是我在过去一年里试图从不同角度传达的一个主题的延续:类型系统是工具,我们应该更有意识和有意识地了解它们实际上做了什么,以及如何有效地使用它们。
让我最终坐下来写这篇文章的催化剂是最近出版的标签,而不是新型的。这是一篇很好的博客文章,我全心全意地同意它的总体主旨,但我认为这是一个错失了表达更大观点的机会。事实上,从定义上讲,Tagked是一种新类型,所以这篇博客文章的标题有点误导。真正的问题是更深层次的问题。
当小心使用时,新型是有用的,但它们的安全性并不是固有的,就像交通锥的安全性以某种方式包含在它所用的塑料中一样。重要的是放在正确的上下文中-如果没有这样的上下文,新类型只是一个标签方案,一种给某个东西命名的方式。