跟踪内核函数:FBT STACK()和arg
在我的上一篇文章中,我描述了FBT如何拦截函数调用并将它们引导到DTrace框架中。这为我在这篇文章中要讨论的内容奠定了基础:stack()操作和内置arg变量的实现。这些功能依赖于堆栈的精确布局,我在前面谈到了它的细节。在这篇文章中,我希望通过一些可视化的帮助来更多地说明这些细节,然后指导您完成这两个与FBT提供者相关的DTrace特性的实现。
但首先,我必须对我上一篇帖子进行更正。事实证明,FBT处理程序不在IST堆栈上执行。它根据内核函数调用的上下文在线程堆栈或CPU的高级中断堆栈上运行,但绝不会在IST上运行。相反,KPTI使用IST堆栈作为临时空间来执行其进入实际处理程序的蹦床。这个小细节很重要。如果使用IST堆栈运行,像dtrace_getpcstack()这样的函数工作的可能性为零,原因稍后会很明显。这也解释了为什么AMD64处理程序在Push q%RBP仿真期间拉下堆栈:如果它与线程/中断在同一堆栈上工作,那么它必须为RBP腾出空间。我可以用视觉解释得更清楚。首先,上一篇文章的图表。
在左边,我们有一个运行在CPU上的内核线程、中断线程或高级中断。右边是断点异常的“中断上下文”,使用IST。图像是正确的,因为有两个不同的堆栈在玩,但是在右侧运行的不是brktrap处理程序。右侧运行的是KPTI蹦床,确保在用户/内核边界之间移动时有一个CR3开关。蹦床还将处理器帧的传真提供给被中断的线程堆栈,这使得KPTI出现在现场并不明智。因此,所有操作都发生在左侧,但是当我们在转到dtrace_invop()的过程中通过#bp处理程序转换时,堆栈看起来是什么样子呢?
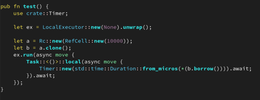
在阶段1中,mac_Provider_tx()在FBT条目检测下调用mac_ring_tx()。线程堆栈上的最后一件事是返回地址,CPU即将执行int3指令。
阶段2紧接在CPU完成INT3指令的执行之后。处理器(通过KPTI蹦床的幽灵)已经将一个16字节对齐的处理器帧推送到堆栈上,并向量进入brktrap()处理程序。
阶段3是在执行一定数量的brktrp()和invoptrap()处理程序之后-记住,DTrace的#bp处理程序模拟#UD。最后一个阶段显示调用dtrace_invop()之前的状态。此时,我们已经在堆栈上增加了一个完整的regs结构,并在此结构之上隐藏了一个返回地址的副本。后者用于填充CPU_DTRACE_CALLER,这是一个稍后变得重要的变量。
探测和操作的分离是DTrace体系结构的一个重要方面。这两者之间的牢固边界使DTrace比它们紧密耦合时更加强大。想想看,我可以在任何探测器中请求调用堆栈,而不仅仅是那些认为该信息有用的探测器。探测使您可以访问上下文,操作使您可以访问该上下文中的数据。如果将操作的执行限制为特定的探测,则会限制您可以询问的有关系统的问题。有了这个设计,你可以问的问题几乎是无穷无尽的。事实证明,要问的一个更有用的问题是:“我的CPU上到底在运行什么该死的东西”?
STACK()操作允许您记录指向探测站点的调用堆栈。在FBT上下文中,这将记录内核线程的调用堆栈,或者中断执行此内核函数的条目或返回。您还可以通过ustack()访问线程的userland堆栈,但我不在这里介绍这一点。
STACK()操作由dtrace_getpcstack()函数实现。要从dtrace_invop()到达那里,需要在DTrace框架中进行更多的调用。最终,到达那里的调用堆栈如下所示。
Case DTRACEACT_STACK:IF(!dtrace_priv_kernel(State))CONTINUE;dtrace_getpcstack((pc_t*)(tomax+valoff),size/sizeof(Pc_T),探测->;DTPR_aframes,dtrace_anchored(探测)?空:(uint32_t*)arg0);
第一个参数是用于存储程序计数器值(也称为函数指针)的数组地址。此数组从当前DTrace缓冲区的某个偏移量开始。第二个参数是该数组的大小。第三个参数是堆栈上的“人工帧”的数量,稍后将对此进行详细说明。第四个参数用于确定调用堆栈中的第一个(最上面)程序计数器是否是传递给dtrace_probe()的arg0中的值。“锚定的”探测器是在调用dtrace_probe_create()时指定了函数名的探测器。例如,FBT提供程序使用内核函数的名称作为探测器的函数名称,因此它锚定在内核函数上。但是,配置文件提供程序没有指定探测函数名称;它不是锚定的,有点特殊情况。我在这篇帖子的末尾谈到了这一点。
这将我们带到dtrace_getpcstack()函数。但首先,我将在图2上展开,以显示函数的源码第60行的堆栈状态。
Void dtrace_getpcstack(pc_t*pcstack,int pcstack_Limit,int aframes,uint32_t*intrpc){struct frame*fp=(struct frame*)dtrace_getfp();struct frame*nextfp,*minfp,*stacktop;int深度=0;int on_intr,last=0;uintptr_t pc;uintptr_t caller=cpu->;cpu_dtrace_caller;If((on_intr=cpu_on_intr(CPU))!=0)stacktop=(struct frame*)(CPU->;CPU_intr_stack+SA(MINFRAME));否则stacktop=(struct frame*)curthread->;t_stk;minfp=FP;aframes++;
要构建调用堆栈,我们首先需要能够遍历堆栈。幸运的是,Illumos在内核中保留了帧指针,这使得这很容易。但在这种特殊情况下,还有更多需要考虑的问题。首先,我们可能有两个堆栈:高级中断的堆栈以及它中断的线程的堆栈。其次,DTrace框架和FBT提供程序已经在此代码和触发此探测的函数之间放置了自己的帧;我们必须从结果中排除这些“人工”帧。最后,为了正确性和安全性,我们需要确保不走出堆栈进入空间。说到堆栈,stacktop变量在内存方面指向堆栈的“顶部”(在x86堆栈上向下增长)。从逻辑上讲,stacktop是堆栈的底部,dtrace_getpcstack()帧是顶部。
WHILE(Depth<;pcstack_Limit){nextfp=(struct frame*)fp->;fr_savfp;pc=fp->;fr_savpc;if(nextfp<;=minfp||nextfp>;=stacktop){if(On_Intr){/**从中断堆栈跳到线程堆栈。*/stacktop=(struct frame*)curthread->;t_stk;minfp=(struct frame*)curthread->;t_stkbase;on_intr=0;Continue;}/**这是我们可以处理的最后一个帧;表示*我们应该在处理此帧后返回。*/LAST=1;}。
只要pcstack中有剩余的槽,主循环就遍历调用堆栈并填充程序计数器。如果我们处于高级中断的上下文中,并且我们已经离开了它的堆栈,那么就跳到线程堆栈。否则,我们就离开了线程堆栈,只留下最后这一帧进行记录。
If(aframes>;0){if(--aframes==0&;&;caller!=0){/**我们刚刚用完人工框架,*并且我们有有效的呼叫者--现在填写*。*/assert(Depth<;pcstack_Limit);pcstack[Depth++]=(PC_T)Caller;Caller=0;}}Else{。
一定要跳过任何人造框架。Aframes值基于提供程序在探测创建时提供的信息(dtrace_probe_create()/DTPR_aframes)以及DTrace框架固有的知识。这两个人知道它们各自在stack()操作和第一个实际帧之间注入了多少帧;我们将这些值相加以知道总共要跳过多少帧。
调用者变量稍微微妙一些;这是我在上一篇文章中讨论返回探测时出错的另一件事。调用者值来自CPU->;CPU_DTRACE_CALLER;FBT提供程序独占使用的每个CPU的值,用于记录调用堆栈的第一个实际帧。但是为什么呢?首先,刷新代码(这是返回探测逻辑,但对于条目探测也是如此)。
/**在AMD64上,我们检测ret,而不是*Left。因此,我们需要设置调用者*,以确保stack()*操作的顶帧是正确的。*/DTRACE_CPUFLAG_SET(CPU_DTRACE_NOFAULT);CPU->;CPU_DTrace_CALLER=STACK[0];
在本例中,我们有一个匹配的返回探测器。我不太确定我是否理解这个评论。调用方的返回地址仍然在中断的线程堆栈上,无论我们检测的是Left指令还是ret指令……。
我说的返回地址在堆栈上是正确的。但是我忘记了一个微妙的细节,中断机制不会创建帧-它不会将帧指针推送到堆栈。如果从dtrace_invop()跟踪RBP链接,就可以直观地看到这一点:它链接回mac_Provider_tx()帧,跳过FBT插入之前CALL指令存储的程序计数器(mac_Provider_tx+0x80)。
If(Last){While(Depth<;pcstack_Limit)pcstack[Depth++]=0;return;}fp=nextfp;minfp=fp;
如果我们已经遍历完调用堆栈,则清零pcstack的其余部分。否则,继续遍历调用堆栈。
Arg0-arg9变量和它们的类型化对应变量args[0]-args[9]允许每个探测器提供最多10个参数。Arg值取决于提供程序。FBT为条目探测传递内核函数参数,并为返回探测传递返回偏移量和值。不管提供程序是什么,所有arg变量的使用最终都在dtrace_dif_variable()结束。
Case DIF_VAR_ARGS:IF(!(mstate->;dtms_access&;dtrace_access_args)){cpu_core[cpu->;cpu_id].cpuc_dtrace_flag|=CPU_dtrace_KPRIV;return(0);}ASSERT(mstate->;DTMS_Present&;dtrace_MSTATE_args);if(NDX&>;=sizeof(mstate->;)}assert(mstate->;DTMS_Present&;dtrace_MSTATE_ARGS);IF(NDX&>;=sizeof(mstate->;Dtms_arg)/sizeof(mstate->;Dtms_arg[0])){int aframes=mstate->;dtms_probe->;dpr_aframes+2;dtrace_Provider_t*pv;uint64_tval;pv=mstate->;DTMS_Probe->;dpr_Provider;if(pv->;dtpv_pops.dtps_getargval!=NULL)val=pv->;dtpv_pops.dtps_getargval(pv->;dtpv_arg,mstate->;DTMS_PROBE->;DTPR_id,mstate->;DTMS_Probe->;DTPR_arg,ndx,aframes);Else val=dtrace_getarg(ndx,aframes);/**这是为了防止编译器*对dtrace_getarg()调用进行尾部优化所必需的。*条件的计算结果始终为TRUE,但*编译器无法事先计算出这一点。*(如果编译器*可以依赖于_Always_Tail-Optimize*对dtrace_getarg()的调用--但它可以';t.)*/if(mstate->;DTMS_Probe!=NULL)return(Val);assert(0);}return(mstate->;DTMS_arg[NDX]);
我不打算解释整件事。我将其显示只是为了表明这些值依赖于提供程序。但在FBT的情况下,我们有两种可能性。
对于arg0到arg4,我们从存储在DTMS_arg[]中的参数缓存中提取,如第3215行所示。提供程序通过调用dtrace_Probe()填充此缓存。
对于arg5到arg9,我们必须从特定于提供程序的回调dtps_getargval获得帮助。当未定义时,就像对于FBT一样,我们后退到DTrace框架函数dtrace_getarg()。从末尾开始解释此功能更有意义。
如您所见,从arg5到arg9只需取消对堆栈的引用。但是我们怎么才能做到这一点呢?
Uint64_t dtrace_getarg(int arg,int aframes){uintptr_t val;struct frame*fp=(struct frame*)dtrace_getfp();uintptr_t*stack;int i;#if Defined(__AMD64)/**总共6个参数通过寄存器传递;因此,任何*index为5或更低的参数都在寄存器中。*/int inreg=5;#endif for(i=1;i<;=aframes;i++){fp=(struct frame*)(fp->;fr_savfp);if(fp->;fr_savpc==(Pc_T)dtrace_invop_callsite){。
与stack()操作一样,我们需要遍历当前堆栈;但是,我们不记录程序计数器,而是在#bp时搜索堆栈指针。这被记录在处理器框架中,作为处理器捕获器机械的一部分。回过头来看看图3,它是处理器框架的RSP指向mac_Provider_tx+0x80的地方。当我们点击dtrace_invop_callsite时,我们知道我们位于dtrace_invop()框架的顶部。我们不能再跟随fr_savfp了,因为我们将遍历处理器帧,那么我们该怎么办呢?
#Else/**在AMD64的情况下,我们将使用指向*regs结构的指针,该结构在我们捕获*陷阱时被推送。要获得此结构,我们必须将*递增到dtrace_invop()中存储的帧结构、调用RIP和*填充之外。如果我们正在寻找的参数*被传递到堆栈上,我们将*从保存的*寄存器中取出真正的堆栈指针,并将我们的参数减去寄存器中传递的参数数量*;如果我们正在寻找的参数被传递到注册器中,我们可以直接*加载它。*/struct regs*rp=(struct regs*)((Uintptr_T)&;fp[1]+sizeof(Uintptr_T)*2);if(arg<;=inreg){stack=(uintptr_t*)&;rp->;r_rdi;}Else{stack=(uintptr_t*)(rp->;r_rsp);arg-=inreg;}#endif Goto Load;
原来,我们可以使用一些指针恶作剧来返回由invoptrap处理程序设置的regs结构。我们通过将fp视为一组帧并遍历当前帧来做到这一点。我们从那里强制转换为指针类型,这样我们就可以遍历各个堆栈条目,跳过填充和隐藏的RIP。那就只剩下我们在规则的开始了。
通过指向regs结构的指针,我们最终可以根据需要的参数选择堆栈。按照ABI的要求,我们知道前六个参数在寄存器中。这些寄存器在REGS结构中连续布局。我们可以指向第一个,假装那是堆栈。前五个参数由DTMS_arg[]中的缓存提供,因此此方法只提供arg5。
最后,从调用方的堆栈提供arg6到arg9。在上图中,省略了mac_Provider_tx()的堆栈帧的大部分。它只有三个参数,但如果它有七个或更多参数,则后面的这些参数将存储在RIP上方的堆栈中。
在取消引用堆栈之前,我们必须调整arg以考虑不在调用方堆栈上的寄存器参数。在本例中,我们减去inreg:arg=6就变成了arg=1。您可能会认为这是从零开始的,就像第一个参数从arg0开始一样。但我们必须考虑到调用方堆栈上的第一件事是RIP,并跳过它。
Void dtrace_getpcstack(pc_t*pcstack,int pcstack_Limit,int aframes,uint32_t*infpc){...IF(INTERPC!=NULL&;&;Depth<;pcstack_Limit)pcstack[Depth++]=(PC_T)Intrpc;
Case DTRACEACT_STACK:IF(!dtrace_priv_kernel(State))CONTINUE;dtrace_getpcstack((pc_t*)(tomax+valoff),size/sizeof(Pc_T),探测->;DTPR_aframes,dtrace_anchored(探测)?空:(uint32_t*)arg0);
下面是设置CPU_PROFILE_PC的APIX中断处理程序。R_pc成员是regs结构的r_rip。
If(pil==CBE_HIGH_PIL){/*14*/cpu->;cpu_profile_pil=oldpil;if(USERMODE(rp->;r_cs)){cpu->;cpu_profile_pc=0;cpu->;cpu_profile_upc=rp->;r_pc;cpu->;cpu_cpcprofile_upc=rp->;r_pc;}否则{CPU->;CPU_PROFILE_PC=RP->;r_PC;CPU->;CPU_PROFILE_UPC=0;CPU->;CPU_cpcprofile_PC=RP->;r_PC;CPU->;CPU_cpcprofile_upc=0;}}。
配置文件提供程序是此机制的独占用户。它的探测点是通过高级中断实现的。高级中断的初始向量化与FBT使用的#bp中断没有什么不同:处理器在当前堆栈上布置一个处理器帧,中断处理程序在其上构建一个regs结构。但请记住,此处理器帧没有帧指针,因此无法查看中断的程序计数器。也就是说,如果foo()调用bar(),而bar()被profile的高级中断中断,我们将看到第一个程序计数器为foo()。但是,我们可以从Regs中获取中断的RIP,并将其隐藏起来以备以后检索。我们不需要担心破坏这个值,因为它只为这个特定的中断级别设置。这就是它被称为INTERPC的原因:它是中断程序计数器。
这让我想知道:既然我们总是有一个regs结构,为什么不同时取消CPU_PROFILE_PC和CPU_DTRACE_CALLER呢?为什么不总是遍历堆栈到Regs并从那里提取RIP呢?我唯一的猜测是,当有人坐在引用调用者内置变量(这只是stack()的第一帧)的热探测器上时,这可能是一种优化。