不,C++仍然不支持

虽然这个标题假定了答案(毕竟,糟糕的说唱意味着这个判决是不值得的),但我认为C++让实现安全性、内存安全或线程安全变得非常困难的名声仍然是当之无愧的,尽管多年来它已经变得好了很多。我的意思是:该程序的c++-17版本比使用c++0x要好几年,而且它让细心的程序员可以编写出很好的程序。
这篇帖子以一个简单的多文件字数统计为例:统计当前目录及其所有子目录中所有";.txt&34;文件中的所有字数,其中的字数被定义为以不区分大小写的方式与regexp&34;([a-z]{2,})";匹配的字数。
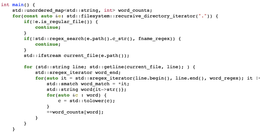
首先,我将浏览该博客文章中的示例,并找出一些剩余的错误。然后,我们将在Rust中构建一个(IMO)更好的版本,它更快、更安全、更简洁。让我们从处理文件并将计数添加到哈希表的正文开始:
当从安全角度检查此代码时,有几件事立即浮现在脑海中。首先,它使用文件系统::RECURSIVE_DIRECTORY_Iterator命令来标识当前目录中的文件,在处理它们之前测试它们的类型和名称。然后,它使用std::ifstream打开文件。
从我用词的方式来看,您可能已经猜到这是TTCTTOU的错误--检查时间到使用时间(Time-to-Check-to-Time-of-Use)。该程序验证该条目是否为常规文件,但稍后将其打开,并假定检查结果有效。我们应该问问自己:
如果文件在目录列表和打开之间被删除,会发生什么情况?
如果文件已替换为管道或其他非常规文件,会发生什么情况?
对于第二种情况,很明显,程序将尝试打开它并对其进行操作;因此,从程序员的意图来看,这是一个错误。在这种情况下,它是一个巨大的错误吗?完全没有,但类似的漏洞已经导致了严重的安全问题。对于第一种情况,我不确定-我打赌其他许多C++程序员也不确定。答案是std::ifstream是安全的,它的行为方式就像访问了EOF一样,但我并不确定这一点,直到我在谷歌上搜索了很多次,并编写了一个测试程序来验证它。偶然的正确总比错误好,但是我们应该在我们的程序中争取更多的东西。最后,它的编写方式对未来的多线程不是很有帮助。这不是练习的重点,但我认为这是值得考虑的,因为许多现代数据处理程序都采用了从单线程到多线程的进化道路。这样的构造会招致线程错误:
(1)它将安全大小范围的计算与该范围的使用分开;(2)它无缘无故地破坏性地修改WORD_ARRAY,只是为了方便打印前10项。而且在C++中为事物添加多线程仍然有些痛苦。(2)它将安全大小范围的计算与该范围的使用分开;(2)它无缘无故地破坏性地修改word_array,只是为了便于打印前10项。以下是我更喜欢将Rust作为系统语言的一些原因。它并不是特别短-Python或shell版本的所有这些都可以用几行代码来表示!但是它稍微短了一点,而且它更清楚哪里被偷工减料或者正确处理了错误:好的,这39行代码,但不包括Cargo.toml文件,它是另外4行非样板文件(这四个依赖项相当类似于C++版本中的#include行,所以应该被计算在内)。(这四个依赖项相当类似于C++版本中的#include行,所以应该被计算在内),但不包括Cargo.toml文件,它是另一个非样板文件(这四个依赖项非常类似于C++版本中的#include行,所以应该计算在内)。
稍微短了一点。但我喜欢Rust版本的一点是,关于错误处理的猜测少了很多。文件打开失败了吗?我们知道它被跳过了,因为如果打开的结果不好,filter_map会丢弃该文件。“我们知道globwald或构造正则表达式中的错误都会得到处理,因为?如果函数返回错误,将导致函数返回错误。功能越强。Take(N)惯用语比C++版本中的等效代码更容易出错,因为我们知道,如果条目少于N项,它就会提前返回。
虽然现代C++允许细心的程序员编写好的程序,但它仍然允许粗心的程序员以产生错误的方式做事。铁锈就没有那么多了:它会缠着你,让你更仔细地盖住角落里的箱子。
生锈并不能神奇地使避免TTCTTOU问题变得更容易-使用std::fs::Metadata(Path)编写代码与在C++版本中一样简单。但是它确实增强了我的信心,即如果该错误存在,代码就会处理文件不存在的问题。但它仍然会以沉着的方式打开一个特殊的文件或目录。它也很容易转换成多线程程序:只需将FOR x在……中。循环到for_each中,并使用raon crate.par_bridge()使for_each中的函数并行执行。
当然,这无法编译,因为我们忘记了对重新插入计数的哈希表使用任何锁定:
错误[E0596]:无法将`wordcounts`借用为可变变量,因为它是`Fn`闭包中的捕获变量。
因此,我们要么将其切换到并行哈希表,要么使用互斥来保护它。我将采取简单的方法,在使用表之前将其锁定,并进行足够的优化,使其比单线程版本更快。在本例中,我将每行解析为小写单词,并将其存储在向量中,然后锁定哈希表,然后批量插入该行的单词:
不错--大约有十行代码被修改,形成了一个基本的并行代码版本。
C++版本有一些优点反映了Rust标准库的不成熟。它能够很容易地使用Partial_Sort来减少按计数排序的工作量;我必须找到lazysorcrate,它不是标准库的一部分,它做同样的事情。
两者都很快;根据C++编译器的不同,锈色的可能更快,也可能不更快。)(更新:更多基准,由@cb321在黑客新闻上提示,并将基准切换到容易下载的东西:查尔斯·狄更斯;A Tale of Two Cities";(更新:更多基准,由@cb321在黑客新闻上提示):查尔斯·狄更斯";双城记";)-i7-7920HQ,MacOS Rust版本:90ms(rustc 1.47.0(18bf6b4f02020-10-07))C++版本:340ms(Apple clang版本12.0.0(clang-1200.0.32.2))-至强(R)Gold6130(Skylake,Ubuntu20.04)rut:76ms(rustc-1.47.0)C++:60ms(GCC版本9.3.0(Ubuntu 9.3.0-10ubuntu2)),-O3,无PGO。
并行版有很多更大的文件,使用四核处理器可以在0.307秒内数出4个2MB的样本文件-这不是很线性的缩放,但对于几分钟的调整来说还不错。同时,单线程C++版本在MacOS上停留了大约3.55秒。
尽管Rust版本的长度较短,但可能比C++版本花了我更长的时间来编写。我不得不花更多的时间弄清楚返回了哪些函数,以便处理它们可能的返回类型,并且不得不花更多的时间搜索文件系统元数据等内容,这可能是因为我是这门语言的新手。但是,使其正确并使其并行所需的时间较少,尽管我在这门语言方面经验较少。在我做的很多事情中,我都会做这样的权衡。
更新:来自burntsushi的一些很好的反馈是关于不必要地使用globwalt引入了很多额外的依赖。这是一个很好的观点,说明了在GitHub上使用随机板条箱太容易的风险--或者,可能是关于拥有一个不那么成熟的stdlib的固有危险。代码的更新版编译起来更快,这是一个很好的观点: