今日CenturyLink/Level(3)故障分析
今天,一家主要的ISP和互联网带宽提供商CenturyLink/Level(3)经历了一次严重的停机,影响了Cloudflare的一些客户以及互联网上大量的其他服务和提供商。在我们等待CenturyLink/Level(3)的验尸报告时,我想写下我们看到的时间线,Cloudflare的系统是如何绕过问题的,为什么尽管我们采取了缓解措施,我们的一些客户仍然受到影响,以及问题的可能根本原因是什么。
在世界协调时10:03,我们的监控系统开始观察到到达客户源服务器的错误数量增加。这些错误显示为“522错误”,表明从Cloudflare的网络连接到我们客户的应用程序所在的位置存在问题。
CloudFlare连接到众多网络提供商中的CenturyLink/Level(3)。当我们发现来自一个网络提供商的错误增加时,我们的系统会自动尝试访问不同提供商的客户应用程序。考虑到我们可以访问的提供商数量,即使一个提供商出现问题,我们通常也能够继续路由流量。
在这种情况下,从522个错误增加的几秒钟内开始,我们的系统自动将流量从CenturyLink/Level(3)重新路由到我们连接的备用网络提供商,包括Cogent、NTT、GTT、Telia和Tata。
我们的网络运营中心也收到了警报,我们的团队开始采取额外的措施来缓解我们的自动化系统从世界协调时10:09开始无法自动解决的任何问题。即使失去了作为我们的网络提供商之一的CenturyLink/Level(3),我们仍成功地为大多数客户和最终用户保持网络中的流量流动。
下图显示了Cloudflare网络与我们连接的网络提供商中的六个主要一级网络之间的流量。红色部分显示CenturyLink/Level(3)流量,该流量在事件期间降至接近零。您还可以看到我们如何在事故期间自动将流量转移到其他网络提供商,以减轻影响并确保流量持续流动。
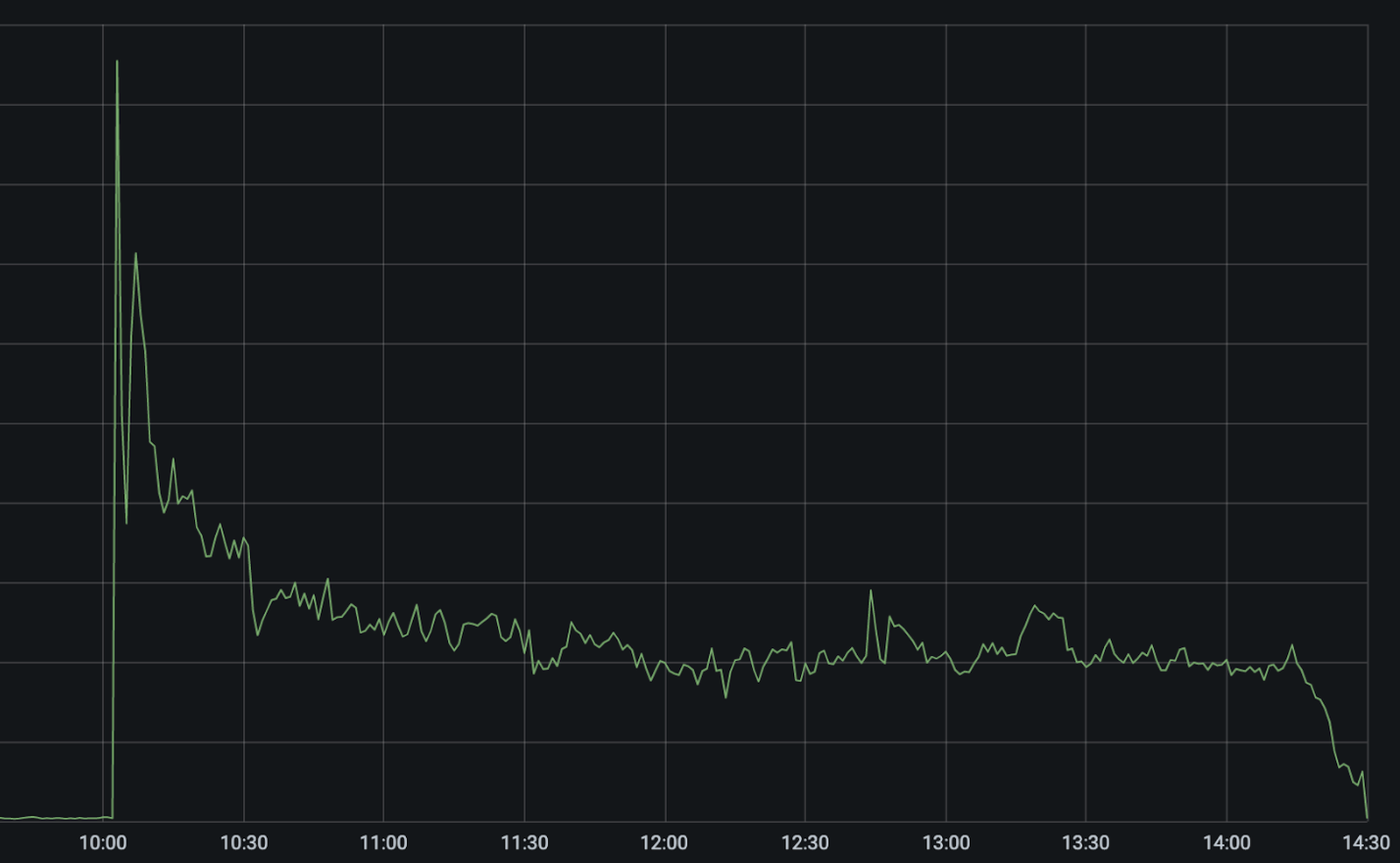
下图显示了事件发生期间整个网络中的522个错误(表明我们无法访问客户的应用程序)。
协调世界时10:03的急剧上升是CenturyLink/Level(3)网络故障。我们的自动化系统立即开始尝试在替代网络提供商之间重新路由和重新平衡流量,导致错误立即减少一半,然后在这些路径自动优化时降至峰值的25%左右。
在10:03 UTC和10:11 UTC之间,我们的系统自动禁用了我们连接的48个城市的CenturyLink/Level(3),并通过备用网络提供商重新路由流量。我们的系统在移出流量之前会考虑其他提供商的容量,以防止级联故障。这就是为什么故障转移虽然是自动的,但并不是在所有位置都是即时的。我们的团队能够应用额外的手动缓解措施,将错误数量再减少5%。
不幸的是,仍然有更多的错误表明我们仍然无法联系到一些客户。CenturyLink/Level(3)是世界上最大的网络供应商之一。因此,许多主机提供商只能通过其网络实现到Internet的单宿连接。
用旧的互联网作为“高速公路”的比喻,就像只有一个通往城镇的出口。如果出口被堵住了,那就没有办法到达镇上了。这种情况在某些情况下变得更加严重,因为CenturyLink/Level(3)的网络不支持路由撤销,即使在Cloudflare这样的网络被撤销之后,它们仍在继续向这些网络通告路由。对于仅通过CenturyLink/Level(3)连接到Internet的客户,或者如果CenturyLink/Level(3)在它们被撤回后继续宣布错误的路由,我们无法联系到他们的应用程序,并且他们继续看到522个错误,直到CenturyLink/Level(3)在UTC时间14:30左右解决了他们的问题。
网络的另一边(“眼球”)也有同样的问题。个人需要在互联网的高速公路上有一个入口。互联网入口基本上是您的ISP提供的。CenturyLink是美国最大的ISP之一。
由于此次停机似乎导致CenturyLink/Level(3)网络全部离线,因此在问题解决之前,CenturyLink客户将无法联系到Cloudflare或任何其他互联网提供商。在全球范围内,我们看到全球流量在中断期间下降了3.5%,几乎所有这些都是由于CenturyLink在美国各地的ISP服务几乎完全中断。
虽然在CenturyLink/Level(3)发布验尸报告之前,我们不能确切知道发生了什么,但我们可以从BGP公告中看到线索,以及它们在中断期间是如何在互联网上传播的。BGP是边界网关协议。这是Internet上的路由器如何向彼此宣布它们后面有哪些IP,因此它们应该接收什么流量。
从世界协调时10:04开始,有大量的BGP更新。BGP更新是路由器发出的通知路由已更改或不再可用的信号。在正常情况下,互联网每15分钟可以看到大约15MB-2MB的BGP更新。在事件开始时,BGP更新的数量激增至每15分钟超过26MB的BGP更新,并在整个事件期间保持在较高水平。
这些更新显示了CenturyLink/Level(3)主干内部BGP路由的不稳定性。问题是,是什么导致了这种不稳定。CenturyLink/Level(3)状态更新提供了一些提示和指向,指出流规范更新是根本原因。
在CenturyLink/Level(3)的更新中,他们提到错误的Flowspec规则导致了这个问题。那么什么是Flowspec呢?Flowspec是BGP的扩展,它允许使用BGP轻松地跨网络甚至在网络之间分发防火墙规则。Flowspec是一个强大的工具。它允许您几乎立即在整个网络中高效地推送规则。当你试图对攻击之类的事情做出快速反应时,这是很棒的,但如果你犯了错误,这可能是危险的。
在Cloudflare,在我们的历史早期,我们自己使用Flowspec来推送防火墙规则,例如,为了减轻大型网络层DDoS攻击。7年多前,我们自己遭遇了由Flowspec引起的停机。我们自己不再使用Flowspec,但它仍然是推送网络防火墙规则的通用协议。
我们只能推测CenturyLink/Level(3)发生了什么,但一个看似合理的情况是,他们发出了Flowspec命令,试图阻止针对其网络的攻击或其他滥用。状态报告表明Flowspec规则阻止BGP本身被公告。我们没有办法知道Flowspec规则是什么,但这里有一个Juniper格式的规则,它可以阻止他们网络上的所有BGP通信。
然而,一个谜团仍然存在,为什么全球BGP更新在整个事件中都保持在较高水平。如果规则阻止了BGP,那么最初您会看到BGP公告增加,然后它们会恢复正常。
一种可能的解释是,令人不快的Flowspec规则出现在一长串BGP更新的末尾。如果是这样的话,可能发生的情况是CenturyLink/Level(3)的网络中的每个路由器都将收到Flowspec规则。然后他们会阻止BGP。这将导致他们停止接收规则。他们会重新开始,按照自己的方式检查所有的BGP规则,直到再次达到令人不快的Flowspec规则。BGP将再次被丢弃。将不再接收Flowspec规则。循环还会继续,一遍又一遍。
这样做的一个挑战是,在每个周期中,BGP更新队列将在CenturyLink/Level(3)的网络内继续增加。这可能已经到了路由器的内存和CPU过载的地步,给让他们的网络恢复在线带来了一系列额外的挑战。
这是一次严重的全球互联网中断,毫无疑问,CenturyLink/Level(3)团队收到了即时警报。他们是一家非常成熟的网络运营商,拥有世界级的网络运营中心(NOC)。那为什么要花四个多小时才解决呢?
再说一次,我们只能推测。首先,可能是Flowspec规则和大量BGP更新强加给他们的路由器,使得他们很难登录到自己的接口。在CenturyLink/Level(3)的请求中,其他几个一级提供商采取了行动,去对等他们的网络。这将限制CenturyLink/Level(3)网络接收的BGP公告的数量,并帮助它有时间迎头赶上。
其次,也可能是Flowspec规则不是由CenturyLink/Level(3)自己发布的,而是由他们的一个客户发布的。许多网络提供商将允许Flowspec对等。对于希望阻止攻击流量的下游客户来说,这可能是一个强大的工具,但在出现问题时会使追踪违规的Flowspec规则变得更加困难。
最后,当这些问题在周日清晨发生时,也不会有任何帮助。网络CenturyLink/Level(3)的规模和规模极其复杂。事故时有发生。我们感谢他们的团队让我们了解整个事件发生的情况。#哈格普斯。
停电后尸检