Building FunctionTrace,一个图形化Python分析器
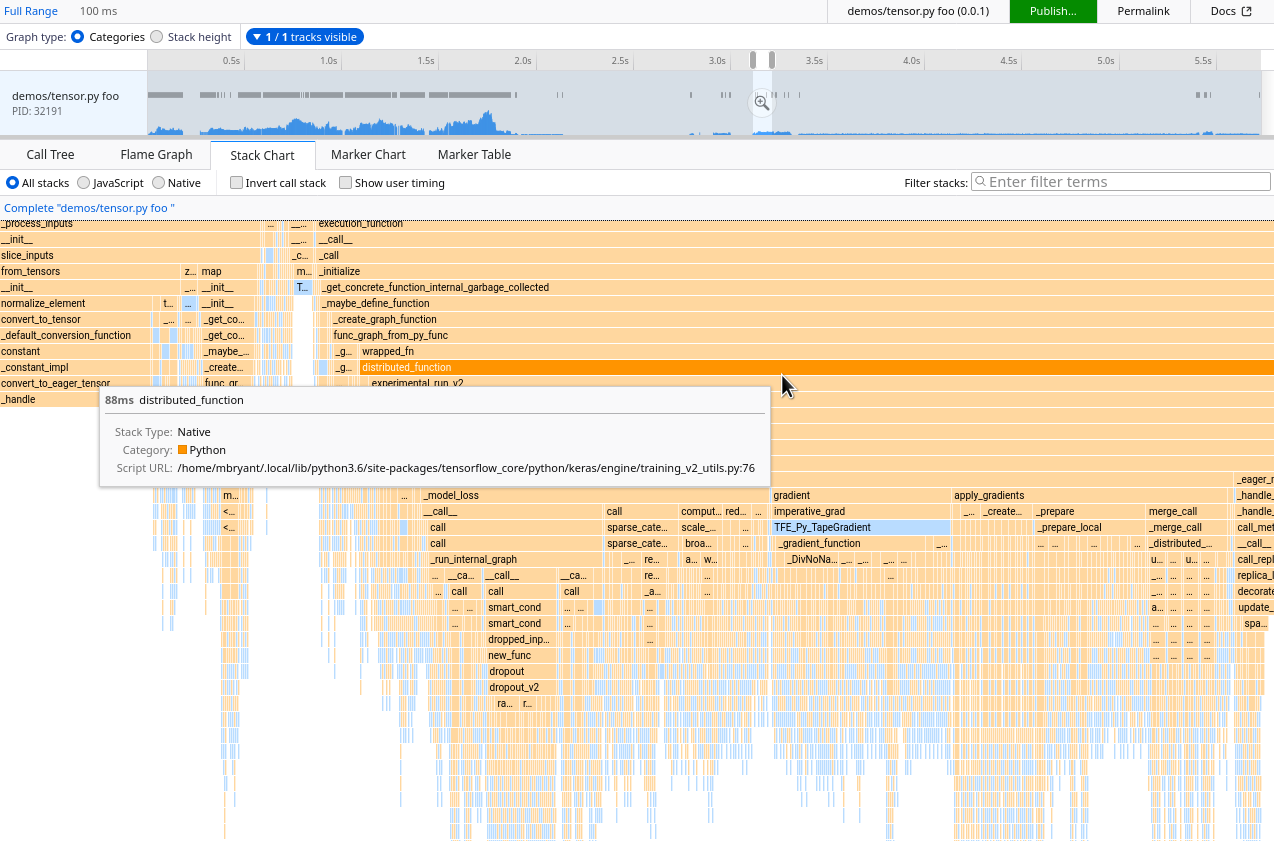
在Project Quantum时代,Firefox Profiler成为Firefox性能工作的基石。当您打开示例录音时,您首先会看到一个功能强大的基于Web的性能分析界面,具有调用树、堆栈图、火焰图等功能。所有数据过滤、缩放、切片和转换操作都保留在一个可共享的URL中。您可以在bug中分享它,记录您的发现,将其与其他录音并排比较,或者将其移交以供进一步调查。Firefox DevEdition有一个内置的分析流程,可以让记录和共享变得顺畅。我们的目标是让所有开发人员都能在性能上进行协作--甚至超越Firefox。
早期,Firefox Profiler可以导入其他格式,从Linux Perf和Chrome的Profile开始。随着时间的推移,单个开发人员添加了更多的格式。今天,第一批采用Firefox作为分析工具的项目正在涌现。FunctionTrace就是其中之一,这里Matt将讲述他是如何构建它的。
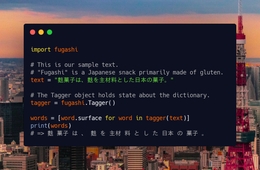
我最近构建了一个工具来帮助开发人员更好地理解他们的Python代码在做什么。FunctionTrace是一个针对Python的非采样分析器,运行在未经修改的Python应用程序上,开销非常低(<;5%)。重要的是,它与Firefox Profiler集成在一起。这允许您以图形方式与配置文件交互,从而更容易发现模式并改进代码库。
在这篇文章中,我将讨论我们为什么构建FunctionTrace,并分享其实现的一些技术细节。我将展示这样的工具如何将Firefox Profiler作为一个强大的开源可视化工具。接下来,您还可以玩它的一个小演示!
随着时间的推移,代码库往往会变得更大,特别是在与许多人一起处理复杂项目时。一些语言对此有很好的支持,比如几十年来积累了IDE功能的Java,或者Rust的强类型系统,使得重构变得轻而易举。随着其他语言的发展,代码库有时似乎变得越来越难以维护。在较旧的Python代码库中尤其如此(至少我们现在都在使用Python3,对吗?)。
要进行广泛的更改或重构您不熟悉的代码片段可能非常困难。相反,当我能够看到程序正在做什么以及它的所有交互时,我会更容易做出正确的更改。通常,我甚至发现自己在改进我从未打算接触的代码片段,因为当显示在我的屏幕上时,低效变得非常明显。
我希望能够理解我工作的Python代码库在做什么,而不需要阅读数百个文件。我找不到令人满意的现有Python工具,而且由于需要大量的UI工作,我基本上对自己构建工具失去了兴趣。然而,当我偶然发现Firefox Profiler时,我迅速了解程序执行情况的希望重新燃起。
Profiler提供了所有的“硬”功能--一个直观的开源UI,可以显示堆栈图表、时间相关的日志标记、火焰图,以及绑定到主要Web浏览器所带来的稳定性。任何能够生成格式正确的JSON概要文件的工具都可以重用前面提到的所有图形分析特性。
幸运的是,在我发现Firefox Profiler之后,我已经有一周的假期安排了几天。我认识另一位朋友,他有兴趣和我一起建造它,并在那个星期请假。
第一个目标对设计有重大影响,而后两个目标增加了工程复杂性。从过去使用这类工具的经验来看,我们都知道看不到太短的函数调用的挫败感。如果采样速度为1ms,但重要函数的运行速度超过1ms,则会遗漏程序内部正在发生的重要内容!
因此,我们知道需要能够跟踪所有函数调用,而不能使用采样分析器。此外,我最近在一个代码库中花了一些时间,在那里Python函数将执行其他Python代码(通常通过一个中间shell脚本)。由此,我们知道我们还希望能够跟踪派生的Python进程。
为了支持多个进程和子代,我们决定采用客户端-服务器模型。我们将检测Python客户端,它会将跟踪数据发送到Rust服务器。在生成可由Firefox Profiler使用的配置文件之前,服务器将聚合和压缩数据。我们选择Rust有几个原因,包括强类型系统、对稳定性能和可预测内存使用的渴望,以及易于原型化和重构。
我们将客户机原型化为Python模块,通过python-m函数跟踪code.py调用。这使我们可以轻松地使用Python的内置跟踪挂钩来记录执行的内容。最初的实施看起来非常类似于以下内容:
Def PROFILE_FUNC(帧,事件,参数):如果EVENT==";调用";或EVENT==";RETURN";或EVENT==";c_CALL";或EVENT==";C_RETURN";:DATA=(EVENT,time.time())server.sendall(json.dumps(data))sys.setprofile(profile_func)。
对于服务器,我们在Unix域套接字上监听客户端连接。然后,我们从客户端读取数据,并将其转换为Firefox Profiler的JSON格式。
Firefox Profiler支持各种配置文件类型,如性能日志。但是,我们决定直接发送到Profiler的内部格式。与添加新的受支持格式相比,它需要更少的空间和维护。重要的是,Firefox Profiler维护配置文件版本的向后兼容性。这意味着我们针对当前格式版本生成的任何配置文件在将来加载时都会自动转换为最新版本。此外,探查器格式通过整数ID引用字符串。这可以通过重复数据删除显著节省空间(同时使用indexmap实现起来微不足道)。
一般来说,最初的基础是有效的。在每次函数调用/返回时,Python都会调用我们的钩子。然后,挂钩将通过套接字向外发送JSON消息,以便服务器将其转换为正确的格式。然而,它的速度慢得令人难以置信。即使在批处理套接字调用之后,我们也观察到一些测试程序的开销至少是8倍!
此时,我们转到使用Python的C API的C语言。在相同的程序上,我们的开销降到了1.1倍。在那之后,我们可以通过lock_gettime()将对time.time()的调用替换为rdtsc操作,从而进行另一个关键优化。我们将函数调用的性能开销减少到几条指令并发出64位数据。这比在关键路径中使用一系列Python调用链和复杂的算法要高效得多。
我已经提到,我们支持跟踪多线程和子进程。由于这是客户端中比较困难的部分之一,因此值得讨论一些较低级别的细节。
我们通过threading.setprofile()在所有线程上安装一个处理程序。(注意:我们在设置线程状态时通过这样的处理程序进行注册,以确保Python正在运行并且GIL当前处于挂起状态。这使我们可以简化一些假设。):
//这由//threading.setprofile()作为新线程的setprofile()处理程序安装。在第一次执行时,它初始化对线程的跟踪(包括创建线程状态),然后//将其自身替换为//正常的Fprofile_FunctionTrace处理程序。static PyObject*Fprofile_ThreadFunctionTrace(..args..){Fprofile_CreateThreadState();//用真实的setprofile()处理程序替换我们的setprofile()处理程序,然后手动调用//它以确保记录此调用。PyEval_SetProfile(Fprofile_FunctionTrace);Fprofile_FunctionTrace(..args..);Py_Return_None;}。
当调用我们的Fprofile_ThreadFunctionTrace()挂钩时,它分配一个struct ThreadState,该结构包含线程记录事件和与服务器通信所需的信息。然后,我们向配置文件服务器发送初始消息。在这里,我们通知它新的线程已经启动,并提供一些初始信息(时间、PID等)。在初始化之后,我们用Fprofile_FunctionTrace()替换钩子,它在将来执行实际的跟踪。
在处理多个进程时,我们假设通过python解释器运行子进程。不幸的是,不会使用-m函数跟踪调用子对象,因此我们不知道如何跟踪它们。为了确保跟踪子进程,我们在启动时修改了$PATH环境变量。反过来,这确保python指向知道加载函数跟踪的可执行文件。
#生成一个临时目录来存储我们的包装器。我们将临时#将此目录添加到我们的路径。tempdir=tempfile.mkdtemp(prefix=";py-functiontrace";)os.environ[";PATH";]=tempdir+os.pathsep+os.environ[";path";]#为我们支持的各种Python版本生成包装器,以确保#它们包含在我们的PATH.print_pythons=[";python";,";python3";,";python3.6";中。,";python3.7";,";python3.8";]对于f.write(PYTHON_TEMPLATE.format(python=python))_pythons中的python:with open(os.path.join(tempdir,python),";w";)as f:With open(os.path.join(tempdir,python),";w";)as f:With OPEN os.chmod(f.name,0o755)
在包装器内部,我们只需使用-m函数跟踪的附加参数调用真正的python解释器。为了结束此支持,我们在启动时添加了一个环境变量。该变量说明我们使用哪个套接字与配置文件服务器通信。如果客户端初始化并看到此环境变量已经设置,则它会识别子进程。然后,它连接到现有的服务器实例,允许我们将其跟踪与原始客户端的跟踪相关联。
今天FunctionTrace的整体实现与上述描述有许多相似之处。在较高级别上,当作为python-m函数跟踪code.py调用时,通过FunctionTrace跟踪客户端。这将加载一些设置的Python模块,然后调用我们的C模块来安装各种跟踪挂钩。这些挂钩包括上面提到的sys.setprofile挂钩、内存分配挂钩,以及各种“有趣”函数上的自定义挂钩,比如builtins.print或builtins.__import__。此外,我们还会派生一个function-trace-server实例,设置一个套接字来与其对话,并确保将来的线程和子进程将与同一服务器对话。
在每个跟踪事件上,Python客户端都会发出一个小的MessagePack记录。该记录包含线程本地内存缓冲区的最小事件信息和时间戳。当缓冲区填满时(每128KB),它通过共享套接字转储到服务器,客户端继续执行。服务器异步侦听每个客户端,将它们的跟踪日志快速消耗到单独的缓冲区中,以避免阻塞它们。然后,对应于每个客户端的线程能够解析每个跟踪事件,并将其转换为适当的结束格式。一旦所有连接的客户端都退出,每个线程的日志就会聚合到一个完整的配置文件日志中。最后,它被发送到一个文件,然后可以与Firefox Profiler一起使用。
拥有Python C模块可以提供显著更高的功能和性能,但也会带来成本。它需要更多的代码,更难找到好的文档;而且几乎没有容易访问的功能。虽然C模块似乎是编写高性能Python模块的未得到充分利用的工具(基于我看到的一些FunctionTrace配置文件),但我们建议保持平衡。对于Python不出色的地方,用Python编写大多数非性能关键代码,并用C调用内部循环或设置代码。
当人类可读的方面不是必需的时,JSON编码/解码可能会非常慢。我们转而使用MessagePack进行客户端-服务器通信,发现它同样易于使用,同时将一些基准时间缩短了一半!
Python中的多线程性能分析支持非常复杂,所以可以理解为什么它似乎不是以前主流Python性能分析器的关键特性。在我们很好地理解如何在保持高性能的同时绕过GIL进行操作之前,我们采取了几种不同的方法和许多分段故障。
如果没有Firefox Profiler,这个项目就不会存在。为未经验证的性能工具创建复杂的前端实在太耗时了。我们希望看到其他针对Firefox Profiler的项目,要么像FunctionTrace那样添加对Profiler格式的本地支持,要么贡献对它们自己的格式的支持。虽然FunctionTrace还没有完全完成,但我希望在这个博客上分享它可以让其他狡猾的开发人员意识到Firefox Profiler的潜力。Profiler为一些关键的开发工具提供了一个绝佳的机会,让它们超越命令行,进入更适合快速提取相关信息的GUI。