让Netflix的数据基础设施更具成本效益
在Netflix,我们对我们的数据基础设施进行了大量投资,该基础设施由数十个数据平台、数百个数据生产者和消费者以及PB级的数据组成。
在许多其他组织中,管理数据基础设施成本的有效方法是设置预算和其他沉重的围栏来限制支出。然而,由于我们数据基础设施的高度分布式性质,以及我们对自由和责任的强调,这些过程是反文化的,效率低下。
因此,我们的效率方法是提供成本透明度,并将效率背景尽可能靠近决策者。我们的最高杠杆工具是一个定制仪表盘,它充当数据生产者和消费者的反馈回路-它是Netflix数据用户成本和使用趋势的单一整体真实来源。这篇文章详细介绍了我们创建数据效率仪表板的方法和经验教训。
Netflix的数据平台可以大致分为静态数据和运动数据系统。静态数据存储(如S3数据仓库、Cassandra、Elasticsearch等)物理存储数据,基础架构成本主要归因于存储。诸如Keystone、Mantis、Spark、Flink等运动系统中的数据增加了与处理瞬态数据相关联的数据基础设施计算成本。每个数据平台包含数千个不同的数据对象(即资源),这些数据对象通常由不同的团队和数据用户拥有。
要获得每个团队的统一成本视图,我们需要能够聚合所有这些平台的成本,同时保留按有意义的资源单元(表、索引、列族、作业等)进行细分的能力。
S3库存:提供对象及其相应元数据的列表,如配置为生成库存列表的S3存储桶的大小(以字节为单位)。Netflix Data Catalog(NDC):内部联合元数据存储,代表Netflix所有数据资源的单一综合知识库。Atlas:为系统生成操作指标(CPU使用率、内存使用率、网络吞吐量等)的监控系统。
作为成本数据的真实来源,AWS计费按服务(EC2、S3等)分类,并可根据AWS标签分配给各种平台。然而,该粒度不足以按数据资源和/或团队提供对基础设施成本可见性。我们采用了以下方法来进一步分配这些成本:
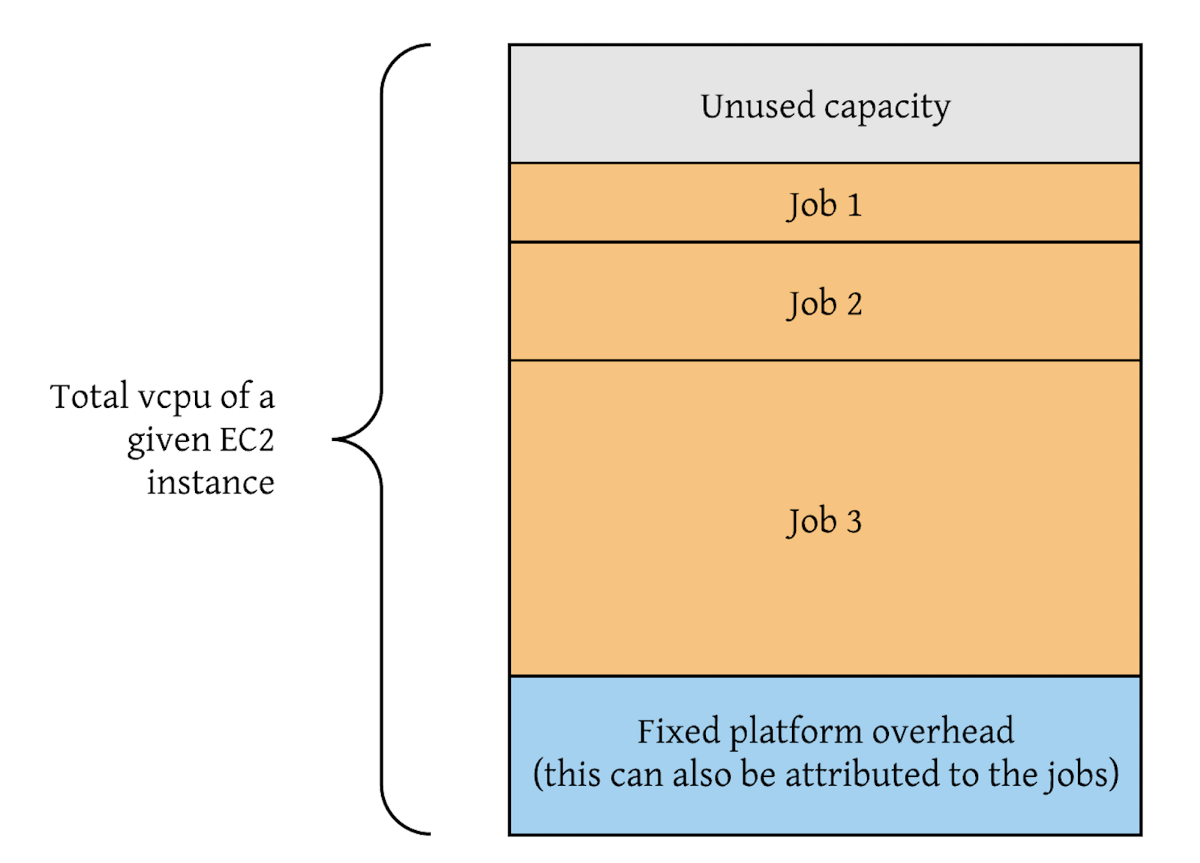
基于EC2的平台:确定平台的瓶颈指标,即CPU、内存、存储、IO、吞吐量或其组合。例如,Kafka数据流通常是网络受限的,而Spark作业通常是CPU和内存受限的。接下来,我们使用Atlas、平台日志和各种REST API确定每个数据资源的瓶颈指标消耗情况。根据每个资源的瓶颈指标消耗(例如,火花作业的CPU利用率百分比)来分配成本。平台的详细计算逻辑可能会因其体系结构而异。以下是在CPU受限计算平台中运行的作业的成本属性示例:
基于S3的平台:我们使用AWS的S3清单(具有对象级粒度),以便将每个S3前缀映射到相应的数据资源(例如配置单元表)。然后,我们根据AWS计费数据中的S3存储价格将每个数据资源的存储字节数转换为成本。
我们使用德鲁伊支持的自定义仪表板将成本上下文传递给团队。我们成本数据的主要目标受众是工程和数据科学团队,因为他们拥有基于此类信息采取行动的最佳环境。此外,我们还为工程领导提供更高层次的成本背景。根据用例的不同,可以根据数据资源层次结构或组织层次结构对成本进行分组。快照和时间序列视图均可用。
注意:以下包含成本、可比较业务指标和职务的片段并不代表实际数据,仅用于说明目的。
在工程投资物有所值的特定场景中,我们不仅提供透明度,还提供优化建议。由于数据存储具有很高的使用率和成本势头(即一次性积累),因此我们根据数据使用模式自动执行分析,以确定最佳存储持续时间(TTL)。到目前为止,我们已经为我们的S3大数据仓库表启用了TTL建议。
我们的大数据仓库允许表的个人所有者选择保留时间。根据这些保留值,存储在日期分区的S3表中的数据由数据看门人进程清理,该进程每天删除比TTL值旧的分区。从历史上看,大多数数据所有者无法很好地理解使用模式以决定最佳TTL。
S3访问日志:AWS为发出的任何S3请求生成日志,提供有关访问的S3前缀、访问时间和其他有用信息的详细记录。表分区元数据:由内部元数据层(Metacat)生成,该层将配置单元表及其分区映射到特定的底层S3位置并存储此元数据。这对于将S3访问日志映射到请求中访问的DW表很有用。回看天数:访问分区的日期与访问该分区的日期之间的差值。
最大的S3存储成本来自事务表,事务表通常按日期分区。使用S3访问日志和S3前缀到表分区的映射,我们能够确定在任何给定日期访问哪些日期分区。接下来,我们查看过去180天内的访问(读/写)活动,并确定最大回看天数。这个回溯天数的最大值决定了给定表的理想TTL。此外,我们还根据最优TTL计算可以实现的潜在年度节约(基于今天的存储水平)。
从控制面板中,数据所有者可以查看详细的访问模式、建议的TTL值与当前的TTL值,以及潜在的节约。
检查数据成本不应该是任何工程团队日常工作的一部分,尤其是那些数据成本微不足道的团队。在这一点上,我们投资于电子邮件推送通知,以提高数据使用量较大的团队的数据成本意识。同样,我们仅为具有材料成本节约潜力的表格发送自动TTL推荐。目前,这些电子邮件每月发送一次。
什么是资源?我们拥有的全套数据资源是什么?这些问题构成了成本效率和分配的主要组成部分。如前所述,我们正在跨动态和静态系统提取各种平台的元数据。不同的平台以不同的方式存储它们的资源元数据。为了解决这个问题,Netflix正在建立一个名为Netflix Data Catalog(NDC)的元数据存储。NDC支持更轻松的数据访问和发现,以支持现有数据和新数据的数据管理要求。我们使用NDC作为成本计算的起点。拥有联合元数据存储可以确保我们有一个普遍理解和接受的概念,来定义存在哪些资源以及哪些资源由各个团队拥有。
时间趋势带来的维护负担比时间点快照高得多。在数据不一致和接收延迟的情况下,显示随时间推移的一致视图通常是具有挑战性的。具体地说,我们应对了以下两个挑战:
资源所有权的更改:对于时间点快照视图,此更改应该自动反映出来。但是,对于时间序列视图,所有权的任何更改也应该反映在历史元数据中。
出现数据问题时状态丢失:资源元数据从各种来源提取,其中许多是API提取,如果在数据摄取期间作业失败,则可能会丢失状态。API提取一般都有缺点,因为数据是瞬时的。重要的是要探索替代方案,比如将事件添加到Keystone,这样我们就可以将数据持久化更长一段时间。
当面对拥有高度分散的数据用户群的无数数据平台时,整合使用情况和成本上下文以通过仪表板创建反馈循环可以极大地提高效率。在合理的情况下,创建自动化建议以进一步减轻效率负担是有必要的-在我们的案例中,数据仓库表保留建议具有很高的ROI。到目前为止,这些仪表板和TTL建议已使我们的数据仓库存储空间减少了10%以上。
未来,我们计划根据使用模式对资源使用不同的存储级别,识别并积极删除未使用的数据资源的上下游依赖关系,从而进一步提升数据效率。