MetricsDB:用于在Twitter上存储指标的时间序列数据库

我们在前面的博客文章中介绍了可观察性工程的高级概述,并在这里介绍了它的后续内容。我们的时间序列指标摄取服务增长到每分钟超过50亿个指标,存储1.5 PB的逻辑时间序列数据,每分钟处理25K查询请求。从历史上看,我们使用曼哈顿(我们的关键价值商店)作为存储后端。就存储和每分钟请求而言,可观察性拥有曼哈顿最大的集群,该规模成为支持我们客户请求的其他用例的限制因素。我们尝试了各种短期缓解方法,例如批处理写入和合并相关指标来处理这些问题。这些变化在短期内有助于提高可操作性,但可伸缩性仍然是一个问题。我们怀着两个目标探索了替代的OSS存储选项。第一,更好地服务于我们目前的规模和未来五年我们将有机增长的规模。第二,提供我们所缺少的功能,例如对指标上的精确和附加标记的支持。我们找不到满足要求的好选项,于是决定使用Facebook的内存中TSDB:Gorilla中描述的压缩算法来构建我们自己的压缩算法。我们沿着这条路线走下去,并在2017年底生产了我们新后端MetricsDB的初始版本。
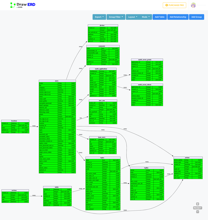
ClusterManager:每组分区都有自己的ClusterManager,负责将分区分配给后端服务器。HDFS用于存储从分区到服务器的映射。当我们添加容量时,ClusterManager负责重新分配分区。协调器和BackendServer在映射更改时从ClusterManager获取更新-它们不直接从HDFS读取。ClusterManager还在后端服务器上执行运行状况检查,并用于协调后端服务器的部署。只有在确保拥有相同分区的其他副本是健康的之后,我们才会更新后端服务器。
BackendServers:所有BackendServers负责处理少量分区的指标。每个BackendServer将所有指标的最新两小时数据保存在内存中。BackendServer还缓存经常访问的指标和时间范围的较旧数据。服务器每两小时将内存中的数据检查点到持久存储,即Blobstore。我们正在使用Blobstore作为持久存储,以便我们的流程可以在我们最新的共享计算平台上运行,管理开销更低。
协调员:协调员负责将请求路由到所有副本集,并验证是否满足所需的仲裁限制。
多区域支持:我们之前的数据存储曼哈顿不支持区域,迫使我们为我们支持的每个区域维护多个数据集。MetricsDB与多区域兼容,可处理来自多个不同区域的指标。我们目前只在我们的主要区域运行MetricsDB。持久化数据通过Blobstore的内置复制复制到其他区域。
指标分区:可观察性是写入繁重的工作负载。仅有约2%的写入指标曾被读取。为了快速识别和解决事件,在更细的粒度上支持更多的指标也很重要。我们从曼哈顿的经验中了解到,在每个请求中发送一个指标会带来扩展挑战。我们通过使用自定义分区方案对从“收集代理”一直到存储系统的写请求进行批处理来解决这个问题。此自定义分区方案在(区域+服务+源)上使用一致的哈希将请求路由到特定的逻辑后端分区,并将每分钟的单个指标写请求数从50多亿降至1000万以下。这还可以均匀分布请求,因此大服务和小服务可以共存并共享分片,从而避免了自定义配置为不同服务设置不同数量的分片的开销。在生产中,我们能够在高负载分区和最低负载分区之间实现每分钟200个请求的极小差异。
压缩效率:Gorilla白皮书确定了对可观察性数据非常有效的压缩算法,可实现95%的空间压缩。我们已经实现了这些算法,并在生产中取得了类似的结果。
93%的时间戳可以存储在1位中,几乎70%的度量值可以存储在1位中。此外,只有约15%的指标需要超过2个字节来存储值。总体而言,这有助于减少1.2PB的存储使用量。
MetricsDB的复制因子为3。我们最初将系统设计为至少需要两次成功写入才能确认写入,并计划仅从单个副本读取。我们选择了单一副本读取方法,假设使用监控堆栈的所有工程师通常关心指标的趋势和聚合(请求计数或成功率),而不是单个数据点。然而,我们发现许多客户在丢失数据时设置警报来识别不健康的服务。如果第一个响应的副本没有最近一分钟的数据,则会触发这些丢失数据警报。我们切换到仲裁读取(2/3)来解决此问题。
聚合中的不一致还有一个额外的问题。在多次重试后,当其中两个复制副本中的写入失败时,会观察到此情况。在这种情况下,只有一个副本将具有特定指标的数据。当包含该复制副本时,聚合将显示不同的值,而不包括该复制副本时,聚合将显示不同的值。等待所有请求的所有三个后端响应是不可接受的,因为这将导致较高的尾部延迟。为了解决此问题,我们引入了两级超时。MetricsDB协调员有较低的“第一级超时”来等待所有三个副本的响应。当超时到期时,如果协调器从至少两个副本接收到响应,则协调器将返回。如果我们仍然没有收到两个响应,则第二个超时将导致返回实际失败。这略微增加了P99延迟(延迟仍然比键值存储好一个数量级),但使数据更加一致。我们正在使用Kafka队列添加更好的副本协调,以进一步提高一致性。
我们在共享计算群集上启动了MetricsDB,以加快上市时间并将团队的运营开销降至最低。MetricsDB是Twitter上第一个运行共享计算平台的有状态服务。在专用群集上运行不是一种选择,因为群集的大小太小而不安全。我们不会有足够的机架多样性,单个服务器出现故障也会损害服务可用性。
在共享计算集群上,可以随时清空或重新启动实例,以便由计算团队进行维护。如果同时清空两个或更多副本,这会导致可用性问题,因为我们的计算团队不知道MetricsDB拓扑。我们最初求助于手动协调和特别工具来处理该问题。Compute团队通过添加对有状态服务(如基于协调器的SLA更新和SLA感知更新)的支持来帮助我们。
虽然MetricsDB将延迟减少了5倍,但为具有大量低延迟源的服务执行读取时间聚合是具有挑战性的。例如,向仪表板加载超过10,000个源的时间序列数据,超过两周的数据通常会超时。为了提高此类查询的响应性,我们添加了一个新服务,该服务执行写入时聚合,称为“计数器”。柜台架构有两个主要变化:
与原始数据点相比,聚合的数据不一致是一个更大的问题。复制副本可能会丢失部分数据,并为同一时间戳计算不同的聚合值。这些在读取路径上是不可能协调的。为了解决这个问题,我们在协调器和后端服务器之间引入了Apache Kafka。我们还将AppendLog从计数器集群中移除,因为Kafka充当AppendLog。
如前所述,对于原始数据点,我们使用了基于(区域、服务、源)的分区。为了聚合每个服务的指标,我们引入了一个新的分区方案(区域、服务、指标),以便属于相同服务的指标位于同一分区上。这为进行聚合提供了更好的数据局部性。在实践中,这也比(区域、服务、源)分区提供了略微更好的平衡。然而,与基于源的分区相比,基于度量的分区在摄取路径上带来了更多的挑战,因为来自收集代理的写请求需要基于分区方案被拆分成多个请求。Apache Kafka Producer可以选择批处理请求,这帮助我们减少了队列和存储的请求数量。
在第一个版本中,我们为基于服务的所有指标提供了最常见的聚合&SUM&39;和';COUNT&39;。我们计划在不久的将来支持其他类型的聚合。
使用自定义存储后端而不是传统的键值存储,总体成本降低了10倍,延迟也降低了5倍。更重要的是,这使我们能够添加其他需要更高规模的功能。此外,基于服务的写入时间聚合显著提高了响应速度,同时降低了MetricsDB的负载。我们计划增加对维度的支持,很快就会精确到粒度。
如果没有基础设施工程领域每个人的辛勤工作和奉献精神,我们就不可能取得今天的成就。特别感谢亚历克斯·安杰洛(Alex Angelo)、查理·卡森(Charlie Carson)、张红刚、穆罕默德·塞尔达尔·索兰(Muhammed Serdar Soran)、王宁、拉维·卡普甘蒂(Ravi Kapuganty)、Vishnu Challam