Rust如何让我们监控30k API调用/分钟

在比勒,我们是一个通晓多种语言的工程团队。无论是口头语言还是编程语言。除了代理库支持的所有语言之外,我们的堆栈还由用Node.js、Ruby、Elixir和其他几种语言编写的服务组成。像大多数团队一样,我们在工作中使用合适的工具与在时间上使用合适的工具之间进行权衡。最近,我们的一项服务达到了限制,导致我们将该服务从Node.js迁移到Rust。这篇文章探讨了导致需要更改语言的一些细节,以及我们在此过程中做出的一些决定。
我们正在构建一个解决方案来帮助开发人员监控他们的API。每次客户的应用程序调用API时,都会向我们发送一个日志,我们在那里对其进行监控和分析。
在问题发生时,我们平均每分钟处理30K个API调用。这是我们所有客户进行的大量API调用。我们将该过程分为两个关键部分:日志接收和日志处理。
我们最初在Node.js中构建了摄取服务。它将接收日志,与灵丹妙药服务通信以检查客户访问权限,使用Redis检查速率限制,然后将日志发送到CloudWatch。在那里,它将触发一个事件,通知我们的处理工人接管。
我们捕获有关API调用的信息,包括从用户的应用程序发送的每个调用的有效负载(请求和响应)。这些当前被限制为1MB,但这仍然是要处理的大量数据。我们以异步方式发送和处理所有内容,目标是使信息尽可能快地提供给最终用户。
我们在AWS Fargate(弹性容器服务(ECS)的无服务器管理解决方案)上托管了所有内容,并在4000请求/分钟后将其设置为自动缩放。一切都很棒!然后,发票来了😱。
我们将使用Kinesis Firehose,而不是将日志发送到CloudWatch。Kinesis Firehose基本上是AWS提供的Kafka等价物。它允许我们以可靠的方式将数据流传送到多个目的地。由于我们的日志处理工作器几乎没有更新,因此我们能够从CloudWatch和Kinesis Firehose获取日志。随着这一变化,每天的成本将降至以前的0.6%左右。
更新的服务现在通过Kinesis将日志数据传递到S3,从而触发工作人员接管处理任务。我们把零钱拿出来,一切都恢复正常了.。或者我们认为。不久之后,我们开始注意到我们的监控仪表板上出现了一些异常情况。
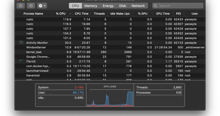
我们在收集垃圾,很多时候。垃圾回收(GC)是某些语言自动释放不再使用的内存的一种方式。当发生这种情况时,程序会暂停。这称为GC暂停。您对内存进行的写入越多,需要进行的垃圾收集就越多,因此,暂停时间会增加。对于我们的服务,这些暂停变得足够高,以至于它们导致服务器重新启动,并给CPU带来压力。发生这种情况时,可能看起来服务器已关闭-因为它是暂时的-我们的客户开始看到我们的代理试图接收的大约6%的日志出现5xx错误。
在某些情况下,暂停时间超过4秒(如左侧所示),我们的实例每分钟最多有400次暂停(如右侧所示)。
经过进一步研究,我们似乎是AWS Javascript SDK中内存泄漏的另一个受害者。我们尝试将资源分配增加到极值,比如在1000请求/分钟后自动缩放,但都不起作用。
由于我们的备份计划不再是一个选项,我们转向了新的解决方案。首先,我们看了那些过渡路径最简单的。
如前所述,我们正在使用Elixir服务检查客户访问权限。此服务是私有服务,只能从我们的私有网络(VPC)内访问。我们从未遇到过该服务的任何可伸缩性问题,并且大部分逻辑已经存在。我们只需从该服务中将日志发送到Kinesis,并跳过Node.js服务层即可。我们认为值得一试。
我们开发了缺失的部件,并对其进行了测试。好多了,但还是不太好。我们的基准测试显示,垃圾收集的水平仍然很高,在使用日志时,我们仍然向用户返回5xx。在这一点上,沉重的负载触发了我们的一个长生不老药依赖项的问题(现在已经解决)。
我们也考虑了戈朗。它本来是一个很好的候选语言,但最终,它是另一种垃圾收集语言。虽然可能比我们以前的实现更有效,但随着规模的扩大,我们很有可能会遇到类似的问题。考虑到这些限制,我们需要一个更好的选择。
在我们的原始实现和备份中,核心问题都保持不变:垃圾回收。解决方案是迁移到内存管理更好、没有垃圾回收的语言。进入铁锈。
所有权是Rust最独特的特性,它使Rust能够在不需要垃圾收集器的情况下保证内存安全。-“铁锈之书”
所有权的概念经常使Rust难以学习和编写,但也是它非常适合我们这样的情况的原因。Rust中的每个值都有一个所有者变量,因此在内存中只有一个分配点。一旦该变量超出作用域,就会立即返回内存。
由于摄取日志所需的代码非常小,我们决定试一试。为了测试这一点,我们解决了我们遇到的问题-向Kinesis发送大量数据。
从这一点上说,我们非常有信心Rust可以成为答案,我们决定将原型充实为生产就绪的应用程序。
在这些实验过程中,我们没有直接用Rust替换原始的Node.js服务,而是重新构建了大部分围绕日志摄取的体系结构。新服务的核心是特使代理,使用Rust应用程序作为侧车。
现在,当用户应用程序中的承载代理向承载发送日志数据时,它将进入特使代理。特使查看请求并与Redis通信,以检查速率限制、授权详细信息和使用配额等内容。接下来,与特使一起运行的Rust应用程序准备日志数据,并通过Kinesis将其传递到S3存储桶中进行存储。然后,S3触发我们的工作人员获取并处理数据,以便Elastic Search可以对其进行索引。此时,我们的用户可以访问仪表板中的数据。
我们发现,使用更少-更小的-服务器,我们能够处理更多的数据,而不会出现任何早期的问题。
如果我们查看Node.js服务的延迟数字,我们可以看到平均响应时间接近1700ms的峰值。
使用Rust服务实现,延迟降低到90ms以下,即使在最高峰值时也是如此,使平均响应时间保持在40ms以下。
原始的Node.js应用程序在任何给定时间都使用了大约1.5 GB的内存,而CPU在150%的负载下运行。新的Rust服务使用了大约100MB的内存和仅2.5%的CPU负载。
与大多数初创公司一样,我们行动迅速。有时,当时最好的解决方案并不是永远最好的解决方案。Node.js就是这种情况。它让我们向前迈进,但随着我们的成长,我们也超越了它。随着我们开始处理越来越多的请求,我们需要使我们的基础设施不断发展以满足新的需求。虽然这个过程开始于一个修复,只是用Rust替换了Node.js,但它导致了对我们的日志摄取服务作为一个整体的重新思考。
我们在整个堆栈中仍然使用各种语言,包括Node.js,但现在将考虑将Rust用于有意义的新服务。