UtahFS:加密文件存储
对我来说很重要的一个要求是,在能够读取文件的一部分之前,不应该需要下载并解密整个文件。这一点很重要的一个地方是音频和视频文件,因为它使回放可以快速开始。另一个例子是ZIP文件:许多文件浏览器都有能力浏览压缩的档案,比如ZIP文件,而不需要解压缩。要启用此功能,浏览器需要能够读取存档文件的特定部分,仅解压缩该部分,然后移动到其他位置。
在内部,UtahFS从不存储大于配置大小(默认情况下为32KB)的对象。如果文件具有超过该数据量,则该文件被分解成多个对象,这些对象由跳过列表连接。跳过列表是链表的一个稍微复杂的版本,它允许读取器通过在每个块中存储额外的指针来快速移动到随机位置,这些指针指向比前面只有一跳更远的地方。
当因为文件被删除或截断而不再需要跳过列表中的块时,它们会被添加到一个特殊的“垃圾桶”链表中。然后,当在其他地方需要块时,垃圾桶列表的元素可以被回收,例如,用于创建新文件或将更多数据写入现有文件的末尾。这最大限度地提高了重复利用率,意味着只有在垃圾桶列表为空时才需要创建新块。一些读者可能认为这是“计算机编程艺术:第一卷,第2.2.3节!”中描述的链接分配策略!
使用链接分配的原因从根本上说是因为它对大多数操作来说是最有效的。但是,它也是分配内存的方法,它将与我们在接下来的三节中讨论的密码学最兼容。
既然我们已经讨论了如何将文件拆分成块并通过跳过列表进行连接,现在我们可以讨论一下数据实际上是如何受到保护的。这方面有两个方面:
第一个是机密性,它向存储提供商隐藏每个块的内容。这只需使用从用户密码派生的密钥,使用AES-GCM对每个块进行加密即可。
虽然简单,但该方案不提供前向保密或后妥协安全。正向保密意味着如果用户的设备遭到破坏,攻击者将无法读取已删除的文件。后安全意味着一旦用户的设备不再受到威胁,攻击者将无法读取新文件。不幸的是,提供这两种保证中的任何一种都意味着将需要在设备之间同步的密钥存储在用户设备上,如果丢失,将导致档案不可读。
该方案也不能防止脱机密码破解,因为攻击者可以获取任何加密块,并一直猜测密码,直到找到有效的密码为止。使用Argon2会使猜测密码的成本更高,并建议用户选择强密码,这在一定程度上缓解了这一问题。
我绝对愿意在未来改进加密方案,但我认为上面列出的安全属性对于初始版本来说太困难和脆弱了。
数据保护的第二个方面是完整性,它确保存储提供商没有更改或删除任何内容。这是通过在用户数据上构建Merkle树来实现的。Merkle树在我们关于证书透明度的博客文章中有详细描述。Merkle Tree的根散列与随每次更改而递增的版本号相关联,并且根散列和版本号都使用从用户密码派生的密钥进行身份验证。此数据存储在两个位置:对象存储数据库中的特殊键下和用户设备上的文件中。
每当用户想要从存储提供商读取数据块时,他们都会首先请求远程存储的根目录,并检查它是否与磁盘上的相同,或者版本号是否高于磁盘上的版本号。检查版本号可防止存储提供程序在未检测到的情况下将归档恢复到以前的(有效)状态。然后,可以对照最新的根哈希验证读取的任何数据,从而防止任何其他类型的修改或删除。
在这里使用Merkle Tree与使用证书透明性具有相同的好处:它允许我们验证单个数据片段,而不需要一次下载并验证所有内容。另一个用于数据完整性的常用工具称为消息验证码(MAC),虽然它要简单得多,效率也更高,但它没有办法只进行部分验证。
我们使用Merkle树无法防止的一件事是分叉,即存储提供商向不同的用户显示不同版本的存档。然而,检测分叉需要用户之间的某种八卦,这目前超出了初始实现的范围。
不经意RAM或ORAM是一种密码技术,用于读取和写入随机存取存储器,其方式对存储器本身隐藏了执行了哪项操作(读取或写入)以及操作执行到了存储器的哪一部分!在我们的例子中,“内存”是我们的对象存储提供者,这意味着我们对他们隐藏了我们正在访问哪些数据以及为什么要访问。这对于防御流量分析攻击很有价值,在这种攻击中,对UtahFS这样的系统有详细了解的对手可以查看其发出的请求,并推断加密数据的内容。例如,他们可能会看到您定期上传数据,但几乎从不下载,并推断您正在存储自动备份。
ORAM最简单的实现包括始终读取整个内存空间,然后随时使用所有新值重写整个内存空间,以读取或写入单个值。查看内存访问模式的对手不会知道您实际想要的值,因为您总是触摸所有东西。然而,这将是令人难以置信的低效。
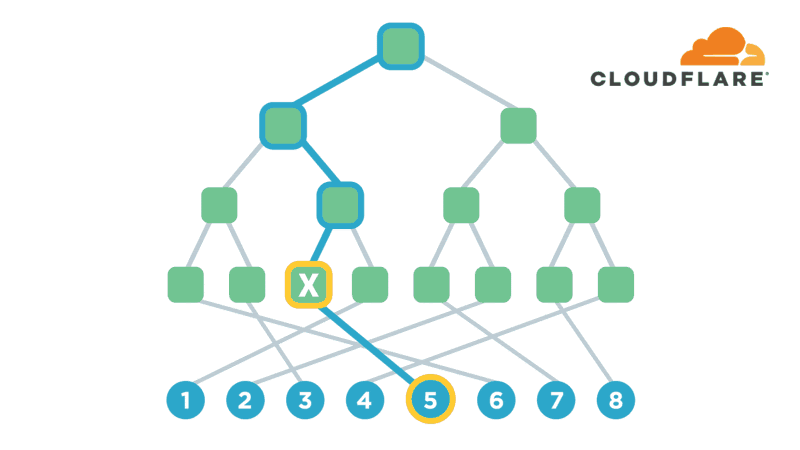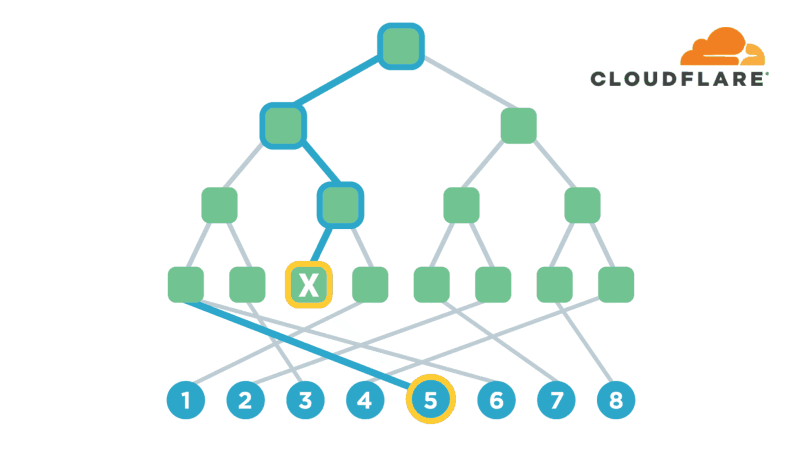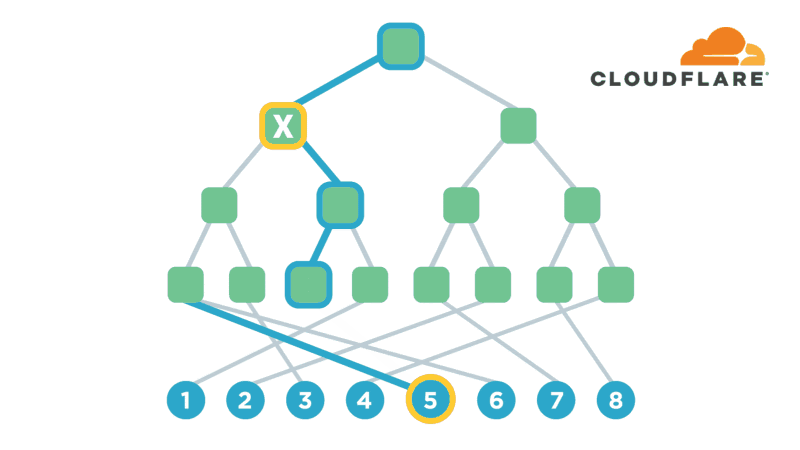
我们实际使用的结构称为path Oram,它稍微抽象了这个简单的方案,使其更有效率。首先,它将内存块组织成一个二叉树,其次,它保存一个客户端表格,该表格将应用程序级指针映射到二叉树中的随机叶子。诀窍在于,值被允许驻留在其分配的叶和二叉树的根之间的路径上的任何内存块中。
现在,当我们想要查找指针指向的值时,我们在表中查找分配给它的叶,并读取根和叶之间路径上的所有节点。我们正在寻找的价值应该在这条路径上,所以我们已经拥有了我们需要的东西!在没有任何其他信息的情况下,对手看到的只是我们从树上读取了一条随机路径。
然而,我们仍然需要隐藏我们是在读还是在写,并重新随机化一些内存,以确保此查找不会与我们将来进行的其他查找相关联。因此,为了重新随机化,我们将刚刚读取的指针分配给一个新叶,并将值从之前存储它的任何一个块移动到一个既是新叶又是旧叶的父块中。(在最坏的情况下,我们可以使用根块,因为根是所有内容的父级。)。一旦将值移动到合适的块并由应用程序完成消费/修改,我们就会重新加密我们获取的所有块,并将它们写回内存。这会将值放入根及其新叶之间的路径中,而只更改我们已经获取的内存块。
这种结构很棒,因为我们只需触及分配给二叉树中单个随机路径的内存,它是相对于内存总大小的对数工作量。但是,即使我们一次又一次地读取相同的值,我们每次都会接触到树中完全随机的路径!但是,额外的内存查找仍然会导致性能损失,这就是为什么ORAM支持是可选的。
在这个项目上工作对我来说真的很有价值,因为虽然系统的许多单独层看起来很简单,但它们是大量改进的结果,很快就会变成复杂的东西。不过,这很困难,因为我必须自己实现很多功能,而不是重用别人的代码。这是因为构建端到端加密系统需要仔细地将安全性集成到每个功能中,而做到这一点的唯一好方法是从一开始。我希望UtahFS对其他对安全存储感兴趣的人有用。
UtahFS加密存储