来自未来的Web应用程序:浏览器中的数据库
如果您查看Web应用程序的生态系统并逐衡衡量,则哪些应用程序将到列表顶部?
如果你问我,我认为谷歌文档和无花果是主要的竞争者。它们' re如此无缝它会滑倒我们的思想,他们可以脱机,他们'重复游戏,他们处理冲突,他们支持复杂的撤消/重做。
这让我很兴奋到来,因为今天难度的边缘是什么' s难以成为明天的新正常。我认为平均应用程序将多种多样,更像Google文档和图。
怎么可能?我们需要找到新的抽象,使Google文档能够简单地写作今天的Crud应用程序。
一个方法可以看出,是看我们今天要去的所有Schleps,看看我们可以做些什么。
亲爱的读者,这篇文章是我试图遵循这个计划。我们今天会参观什么'今天建立一个Web应用程序:我们跳过我们面临的问题,评估Firebase,Supabase,Hasura和朋友等解决方案,看看'离开了。我想到了最后,你'我会同意我的同意,最有用的抽象之一看起来像浏览器中的功能强大的数据库。
我们拥有的第一份工作是在不同的地方获取信息并将其显示。例如,我们可以显示朋友列表,朋友们数,一个与特定的朋友群体的模态等
我们面临的问题是所有组件都需要查看一致的信息。如果一个组件看到了朋友的不同数据,那么你可能会得到错误的"伯爵和#34;在一个视图与另一个视图中显示出来或不同的昵称。
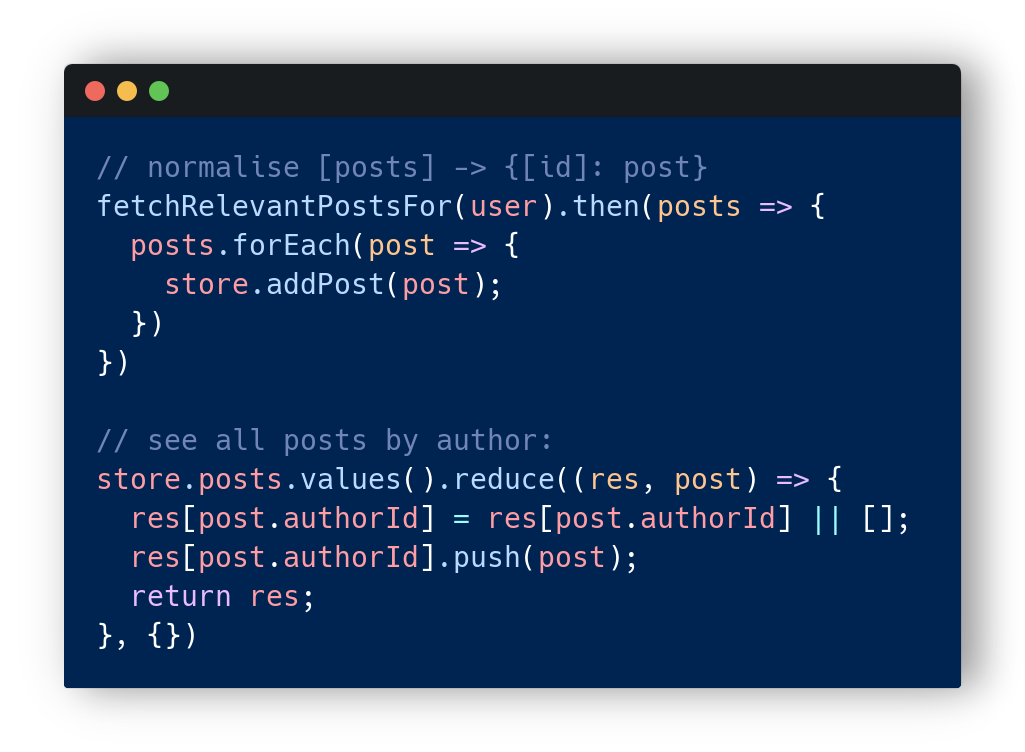
要解决这个问题,我们需要有一个核心的真理来源。所以,每当我们获取任何东西时,我们都会向它标准化并将其倾向于一个地方(通常是商店)。然后,每个组件读取和转换它所需的数据(使用选择器),看到类似的东西并不罕见:
//正常化[帖子] - > {[ID]:post} fetchrelevantposts for(user).then(posts => {posts.foreach(post => {store .addpost(post);})//查看作者:商店的所有帖子。帖子.values().Reduce((res,post)=> {res [post。authorid] = res [post。authorid] || []; res [post。authorid] .push(帖子);退货; },{})
这里的问题是,我们为什么要做所有这项工作?我们编写自定义代码以按摩此数据,而数据库现在已经解决了这个问题很长一段时间。我们应该能够查询我们的数据。为什么我们不能刚做:
下一个问题正在保持数据最新。说我们删除了一个朋友 - 应该发生什么?
我们发送API请求,等待它完成,并将一些逻辑写入"删除"我们对那个朋友的所有信息。这样的东西:
但是,这可以快速处理毛茸茸的:我们必须记住我们商店中的每个地方可能受到这种变化的影响。这就像在我们的头上玩垃圾收集器。我们的头不擅长这一点。
一种方式避免它,是跳过问题,只是重新获取全世界:
任何解决方案都不是非常好的。在这两种情况下,都有隐含的不变性我们需要注意(根据这种变化,我们需要了解哪些其他更改?),我们在申请中介绍滞后。
只要我们对数据库进行更改时,RUB就是这样做的就是没有我们必须如此规范的工作。为什么不能在浏览器中自动发生?
从friend_one_id =的友谊中删除?和friend_two_id =? - 浏览器在删除所有朋友和帖子信息中神奇地更新
B的问题是,B的问题是,我们不得不等待友谊删除以更新我们的浏览器状态。
在大多数情况下,我们可以使体验具有乐观的更新 - 毕竟,我们知道呼叫可能是成功的。为此,我们做一些这样的事情:
这更烦人。现在我们需要手动更新成功操作和故障操作。
这是为什么?在后端,数据库能够做乐观的更新1 - 为什么我们不能在浏览器中做到这一点?
删除friend_one_id =的友谊=?和friend_two_id =? - 如果操作失败,则乐观更新本地商店,我们撤消
数据不仅仅是从自己的行为中的改变。有时我们需要连接到其他用户的变化。例如,有人可以联合我们,或者有人可以向我们发送一条消息。
为了做出这项工作,我们需要做我们在API端点中所做的相同工作,但这次在我们的WebSocket连接上:
但是,这引点了两个问题。首先,我们需要再次播放垃圾收集器,并记住可能受事件影响的每个地方。
其次,如果我们做乐观的更新,我们有竞争条件。想象一下,您运行了一个乐观的更新,将形状的颜色设置为蓝色,而陈旧的反应更新进来,说它是红色的。
1.乐观更新:“蓝色”2.陈旧的反应更新:“红色”3.成功更新,通过插座进来:“蓝色”
现在,你会看到一个闪烁。乐观的更新将进入蓝色,反应更新会将其更改为红色,但一旦乐观更新成功,新的反应更新将再次将其转回蓝色。 2
像这样的解决这些东西让您处理了一致性问题,在...数据库上进行策划文献。
它不一定是这样。如果每个查询是否有反应是什么?
现在,友谊的任何更改都会自动更新订阅此查询的视图。您不必管理更改,您的本地数据库可以弄清楚"最近的更新"是,删除大部分复杂性。
后端开发的大部分最终是数据库和前端之间的一种胶水。
// db.js函数getrelevantposts for(userid){db .exec("从用户选择* fly ...")} // api.js app .get(" commustionposts" ,(req,res)=> {res.status(200).send(getrelevantposts(req.seyid);})
这是如此重复,我们最终创建脚本以生成这些文件。但为什么我们根本需要这样做?无论如何,它们通常非常靠近客户。为什么我们不能将数据库暴露给客户?
好吧,我们没有的原因是因为我们需要确保正确设置权限。例如,您应该只看到您的朋友的帖子。为此,我们将中间件添加到我们的API端点:
但是,这最终越来越令人困惑。 websockets怎么样?新代码更改有时会介绍更新您未指望的数据库对象的方法。突然间,你遇到了麻烦。
在这里询问的问题是为什么API级别的身份验证?理想情况下,我们应该有一些非常接近数据库的东西,确保任何数据访问通过权限检查。像postgres这样的数据库上有行级安全性,但这可能会快速快速3.如果你可以&#34怎么办;描述"数据库附近的实体?
在这里,我们撰写了身份验证规则,并确保您尝试编写的任何方式并更新用户实体,您可以保证您被允许的方式。突然间,而不是大多数代码都会影响权限,只有几个。
例如,我们需要支持" undo /重做",用于友谊行动。用户删除朋友,然后按" undo" - 我们如何支持这一点?
我们不能只删除友谊关系,因为如果我们这样做,那么我们就不会知道这个人是否是"已经是朋友"或者只是问现在成为朋友。在后一种情况下,我们可能需要发送朋友请求。
要解决此问题,我们会展示我们的数据模型。我们已经拥有"友谊事实&#34,而不是单一的友谊关系。
[{状态:"朋友" ,friend_one_id:1,friend_two_id:2,at:1000},{状态:"断开连接" ,friend_one_id:1,friend_two_id:2,at:10001},]
这是有效的,但大多数数据库都没有为它设计:查询不适用于我们期望的,优化比我们预期更难。我们最终必须小心我们如何进行更新,以防我们最终意外删除记录。
突然间,我们成为"类型的数据库工程师&#34 ;,吞噬文献在查询优化上。
这种要求似乎是独一无二的,但它变得更加常见。如果您处理金融交易,则需要这样做的内容以审计目的。撤消/重做是许多应用程序的必需品。
并且上帝禁止发生错误,我们不小心删除了数据。在一个事实世界中,没有这样的事情 - 你可以撤消删除。但唉,这不是我们大多数人住的。
有一个模特将事实视为一流的公民(DATOMIC,我们很快就会谈论),但现在他们是如此外国,这很少达到工程师。如果是不是那么外国,那就怎么了?
还有更多的难度例子。离线模式怎么样?许多应用程序长期运行,可以在没有互联网连接的情况下进行期间。我们如何支持这一点?
我们必须再次演变我们的数据模型,但这一次真的保持一切作为A"事实",并且具有客户端数据库,可以基于它们在内部状态发展它。一旦连接,我们应该能够协调变化。
这极难。从本质上讲,任何实现这一目标的人都成为一个全站式的数据库工程师。但是,如果我们在浏览器中有一个数据库,它就像一个"节点"在分布式数据库中,这将不会自动发生?
事实证明,基于事实的系统实际上使这更容易。许多人认为我们需要诉诸运营变换,以这样做的事情,但由于图4,只要我们有一个单一的领导者,我们可以彻底地展示了一下胜利的语义。简化这一点,只是事实就足够了。当时间更严重的决议来临时,你可以打开OT兔子洞。
想象一下...离线模式关闭蝙蝠。在此之后,大多数应用程序都会是什么?
我们谈到了客户的反应性。在服务器上,它也担心。我们必须确保数据更改时更新所有相关客户端。例如,如果a"帖子"添加了,我们需要确保通知与此帖子相关的所有可能订阅。
这可以得到毛茸茸的。很难知道所有可能与之相关的主题。它也很容易错过:如果在addpost之外的查询更新数据库,我们永远不会知道。这项工作由开发人员弄清楚。它开始简单,但变得更加复杂。
然而,数据库也可以了解所有这些订阅,并且可以处理更新相关查询。但大多数人都没有。 Rethinkdb是闪亮的例子,这很好。如果您选择的查询语言是可能的,那么怎么办?
最终,我们最终需要将数据放在不同的地方:缓存(redis),搜索索引(Elasticsearch)或分析引擎(Hive)。这样做变得非常令人艰难。您可能需要介绍某种队列(Kafka),因此所有这些派生源都保持最新。其中大部分涉及供应机器,引入服务发现以及整个Shebang。
为什么这么复杂?在正常数据库中,您可以做些像:
为什么我们不能为其他服务做到这一点?在他的数据密集型应用程序中,Martin Kleppman建议了这样一种语言:
db |> Elasticsearch db |>分析dB。用户|> redis // bam,we' ve连接的弹性搜索,分析和redis到我们的数据库
哇,我们已经达到了J.但是只有在开始构建您的应用程序后,这些只是您开始面临的问题。怎么样?
也许今天开发人员的最严格的问题是开始的艰难。如果要存储用户信息并显示页面,您会做什么?
之前,这是一个索引.html和ftp问题。现在,它是webpack,typecript,构建流程valore,通常多个服务。有这么多的移动碎片,难以迈出一步。
这似乎只有一个问题,只有缺乏经验的人需要争辩,如果他们只是花了一些时间,他们会变得更快。我认为它比这更重要。大多数项目生活在边缘 - 他们不是你作为一天工作的东西。这意味着甚至几分钟的原型延迟可能会杀死更多项目。
使这一步骤更容易大大增加我们使用的应用程序数量。如果它比index.html和ftp更容易怎么办?
哇,这是很多问题。它看起来可能黯淡,但如果你只是看几年后,它会令人惊讶的是有多少改善。毕竟,我们不需要再滚动自己的机架了。本着绘画早期的精神,许多伟大的人员正在努力解决这些问题的解决方案。他们中有什么?
我认为Firebase在移动Web应用程序的发展方面做了一些最具创新性的工作。他们正确的最重要的事情是浏览器上的数据库。
使用Firebase,您可以以同样的方式查询您的数据。通过创建此抽象,他们解决了A-e。 Firebase处理乐观的更新,默认情况下是无功。它通过提供对权限的支持来消除对端点的需求。
他们的力量也为k:我认为它仍然拥有市场上最佳的地原型。您只能从index.html开始!
首先,查询力量。 Firebase的选择模型可以使抽象更简单地管理,但它会破坏您的查询功能。通常,你通常会陷入一个你必须去标准化数据的地方,或者查询它变得棘手。例如,要记录像友谊的多对多关系,你需要做这样的事情:
您将在两个不同的路径(Usera / Friends / Userbid)和(UserB / Friends / Useraid)中致正常化友谊。抓取完整数据要求您手动复制连接:
在您的应用中,这些关系非常迅速发出。如果一个解决方案帮助您处理它,这将是很棒的。
二,权限。 Firebase允许您使用有限的语言编写权限。在实践中,这些规则很快就会变得毛茸茸 - 指出人们诉诸自己的较高级别语言并编译到Firebase规则。
我们在Facebook上尝试了很多问题,并得出了您需要一种真正的语言来表达权限。如果Firebase有那种,那将是更强大的。
使用其余的项目(审核,撤消/重做,写入的离线模式,派生数据) - Firebase还没有解决它们。
Supabase试图做Firebase为Mongo做了什么,而是对于Postgres来说。如果他们这样做,那将是一个非常有吸引力的选择,因为它会解决Firebase的最大问题:查询强度。
到目前为止,supabase有一些伟大的胜利。他们的auth抽象很棒,这使它成为少数平台之一,这与Firebase一样易于开始。
他们的实时选项允许您订阅行级更新。例如,如果我们想知道友谊创建,更新或更改,我们可以写这个:
这实际上可以让你远。它可能会得到毛茸茸的。例如,如果创建了朋友,我们可能没有用户信息,我们必须要获取它。
这一点到Supabase的主要弱点:它没有A"浏览器上的数据库"抽象呢。虽然您可以进行查询,但您负责归一化和按摩数据。这意味着它们无法自动完成乐观的更新,反应查询等。
他们的许可模型也类似于Firebase,因为他们推迟了Postgres'行级安全性。这可能很棒,就像Firebase很快就会变得毛茸茸。这些规则通常可以减慢查询优化器,并且SQL本身变得更加困难,更难推理。
GraphQL是从客户端声明方式定义所需数据的绝佳方法。像Hasura这样的服务可以拍摄像Postgres这样的数据库,并尽可能聪明的事情,就像给你一个GraphQL API。
Hasura非常引人注目。他们做了一项聪明的工作,可以获得加入,可以让你对你的数据很好。使用翻转,您可以将任何查询转换为订阅。当我第一次尝试将查询转为订阅时,它肯定感到神奇。
今天与GraphQL工具的大问题一般,是他们的原型时间。您经常需要多个不同的库和构建步骤。他们的写故事也有点不那么引人注目。乐观的更新不仅仅是自动发生 - 你必须自己破坏它。
我们看过三个最有前途的解决方案。现在,Firebase解决了蝙蝠的最大问题。 Supabase为您提供了牺牲更多客户端支持的查询强度。 Hasura为您提供更强大的订阅和更强大的本地状态,以牺牲Time-to-prodotype为代价。据我所知,没有人正在处理冲突解决方案,撤消/重做,强大的反应性查询。
在某些方面,未来正在发生。例如,我认为Figma是未来的一个应用程序:它处理卸下句柄脱机模式,撤消/重做和多人游戏。
如果我们想制作这样的应用程序,那么数据的理想抽象是什么样的?
从浏览器中,这种抽象必须像Firebase一样,但具有强烈的查询语言。
您应该能够查询您的本地数据,并且它应该像SQL一样强大。您的查询应该是有关的,如果有更改,则会自动更新。它也应该为您处理乐观的更新。
接下来,我们需要一个可组合的许可语言。 FB的EntFramework是我继续回归的例子,因为它有多强大。我们应该能够在实体上定义规则,并且应该保证我们不会意外地看到我们不允许看到的东西。
最后,此抽象应该让我们轻松实现离线模式,或撤消重做。如果发生了本地写入,并且服务器上的写入冲突,则应有一个与大部分时间都正确的协调。如果有问题,我们应该能够在正确的方向上轻推。
无论我们选择的抽象,它应该让我们在我们脱机时运行写作的能力。
最后,我们应该能够表达数据依赖性,而无需旋转任何内容。用简单的
在Clojure World中,人们长期以来一直是DATOMIC的粉丝,这是一个基于事实的数据库,可让您"看到每一个随时间的变化" Nikita Tonsky还实现了DataScript,一个客户端数据库和查询引擎,具有与Datomic相同的语义!
他们已被用于构建支持脱机的应用程序,如Roam,或者像前体这样的协作应用程序。如果我们要在前后包上包装像样的数据库,并且在前端上的DataScript的数据库,它可能会成为"客户端上的数据库,具有强大的查询语言"!
DATOMIC使您可以轻松订阅新的已提交的事实到数据库。如果我们在最顶级的服务,那么何时何地进行了查询并听取这些事实。从更改,我们将更新相关查询。突然间,我们的数据库变得实时!
我们的服务器可以接受代码片段,它在获取数据时运行。这些碎片将负责权限,给我们一个强大的许可语言!
最后,我们可以编写一些DSL,这使您可以根据用户的首选项向弹性搜索,redis等管道提供数据。
如果我们要使用像样性类似的数据库,我们将不再使用SQL了。 DATOMIC使用基于逻辑的Query语言 ......



