BMC:使用内核缓存和堆栈预处理加速Memcached
明天,yoann ghigoff等。将介绍他们的论文BMC:在NSDI 2021,使用安全的内核缓存和堆栈预堆叠处理加速Memcached。在本文中,提议通过在XDP钩子处实现透明,第一级缓存来加速Memcached使用EBPF。它不是每天看到在应用协议上使用的BPF!
此博客文章是本文的摘要及其主要结果。披露,我曾经与一些作者合作。
memcached是一个受欢迎的key-value存储,最常用作其他应用程序的缓存.bmc充当memcached前面的第一级缓存:
我们呈现BMC,用于MEMCACHED的内核缓存,用于在执行标准网络堆栈之前服务请求。尽管EBPF的安全约束,我们表明可以实现复杂的缓存服务。
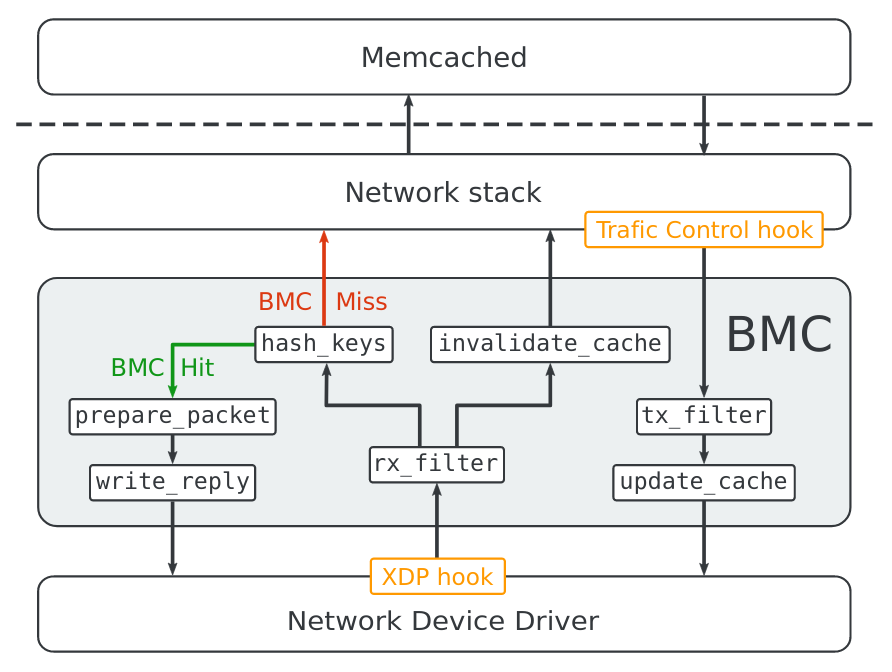
BMC依赖于EBPF和拦截XDP和TC挂钩的数据包,同时进入和出口。我们将看到,实现的挑战之一是解决EBPF验证者的复杂性约束。
由于BMC在商品硬件上运行并需要修改Linux内核和Memcached应用程序,因此可以广泛地部署在现有系统上。
这通常是基于BPF的应用程序。这里特别是,因为BMC是透明的缓存,它不需要更改MEMCACHED。
BMC专注于加速UDP的小型Get请求的处理,以实现高吞吐量,因为从Facebook的以前的工作表明,这些请求构成了重要的部分Memcached流量。
我喜欢作者在纸质早期说明目标流量.They目标小UDP请求,但由于BMC充当一级缓存,因此它们总是可以向Memcached退回以获取不受支持的请求。
这提供了使用低延迟的请求的能力,并且当BMC无法处理请求时返回MEMCACHED应用程序。
当然,如果您的Memcached应用程序仅在TCP上侦听,BMC将不会有很多使用。
作者首先查看Memcached及其CPU瓶颈的UDP性能。在用户空间中,MEMCACHED包括良好优化的数据结构来处理键值对,具有LRU算法,以驱动“陈旧”数据。
MEMCACHED的数据管理已得到很好的优化,并依赖于SLAB分配,LRU算法和哈希表来分配,删除和检索存储在内存中的项目。
然而,内核占MEMCACHED的大部分CPU消耗,主要是通过网络发送和接收数据。作者评估了超过一半的CPU时间在内核中,随着线程数量的增加而增加,随着线程的数量增加。
上面列出的内核函数说明了锁定争用浪费了很多CPU循环,因为使用了单个UDP套接字。在比较BMC对此慢动作中的比较时,作者修补程序归功于SO_REUSEPORT.支持多个套接字来支持多个套接字。支持多个套接字有所帮助跨越核心,使用8个核心时的性能改进。补丁MEMCACHED与BMC进行了更现实的比较,从毕竟Facebook使用类似的优化(但没有SO_REUSEPORT)。
Vanilla Memcached尚未包含这种优化有点令人惊讶。这是我写这一点的时间,作者尚未试图提交修补程序上游(尚未)。
由于本文的大部分讨论了作者如何围绕验证者的复杂性约束,他们在潜入设计之前提供了一点关于BPF的BPF字节码验证。
分析所有条件分支以探索程序的所有可能执行路径。如果验证者达到BPF Exit指令,则特定路径有效,并且验证者的状态包含有效返回值,或者验证者达到等同于一个的状态已知有效。然后验证者返回到未开发的分支状态,并继续此过程,直到检查所有路径。
这个简洁的解释包含很多信息,因此让我们解开它。BPF验证者必须确保通过程序的所有路径有效,因此在下面的示例中,意味着Abcef和Abdef应该有效。它漫命,验证者infers所有堆栈插槽和寄存器的界限和类型(上述验证器状态)。该信息用于验证指令的正确性(例如,内存负载是有界的,直到达到出口指令,直到达到出口指令Point Path被视为有效。该点,验证者背包到未开发的分支并继续,所以在我们的示例中,它可以分析Abcef然后返回到D分析第二条路径的DEF。
分析的指令数量随着分支的数量呈指数增加,因此验证者具有一个额外的尺寸,状态灌注。具体指令1,它将当前状态与先前验证的状态进行比较。如果当前状态相当于前一级的状态。验证状态,然后没有必要走路的其余部分。在我们的示例中,在第二次分析E时,如果验证者的状态相当于它第一次走路时的状态,它将跳过F的分析。
最后,验证者保持指令预算:在放弃之前将分析的指令有多少指令。最近的内核(v5.2 +),此预算为100万条指令,构成主要复杂性约束。我将参考该数量指令需要完全验证程序作为该计划的复杂性。
要充当透明的缓存,BMC必须构建其自己的Memcached数据子集的副本。到该结束,BMC拦截所有集合和获取请求,如下所示。它通过拦截响应来了解新的(key,值)条目获取来自Memcached(更新案例)的请求。对于已经请求的键,BMC可以在不涉及MEMCACHECACE(查找案例)的情况下回复。
最后,在拦截SET请求时,BMC只是使其对应的(key,value)条目(无效情况).since一个设置请求更新键的值,BMC需要确保它不会在下一个错误的键回答错误键获取请求。
您可能想知道为什么BMC在拦截SET请求时不简单地更新其本地缓存。作者提供了两个原因:
我们选择不使用BMC拦截的SET请求更新内核缓存,因为TCP的拥塞控制可能在执行后拒绝新段.OWore,使用SET请求更新内核高速缓存要求BMC和MEMCACHED进程中的请求保持BMC缓存一致的顺序相同,这很难保证过度昂贵的同步机制。
由于变量大小的键和值,作者无法重用BPF的哈希表,因此他们必须自行构建。
它是一个直接映射的缓存,这意味着散列表中的每个桶只能在时间存储一个条目.bmc使用32位fnv-1a [21]哈希函数来计算散列值。
他们的哈希表非常简单,并且没有提供任何碰撞解决,可能是因为在BPF中这样做就在指令方面是昂贵的。在哈希碰撞的情况下,可以始终通过MEMCACHED在USEMACE中处理请求。
BMC缓存由所有内核共享,并且不需要全局锁定方案,因为它的数据结构是不可变的。然而,使用旋转锁来保护每个缓存条目。
BPF实施和随后的评估构成了这项工作的关键。要计算哈希和复制键和值,BMC循环2通过数据,byte逐个字节。这当然是非常昂贵的指示和天真的实现迅速吃整个验证者指令预算。
BMC使用循环从网络数据包复制键和值到其缓存,反之亦然。
为避免在每个请求上花费太多指示,作者首先限制请求BMC将处理:
为了确保单个EBPF程序的复杂性不超过验证者可以分析的最大指令数,我们经验将最大键长度BMC可以处理到250字节,最大值长度为1000字节。根据Facebook的工作负载分析[13],约95%的观察值小于1000字节。
少数请求BMC无法处理的Memcached在Userspace中提供服务,因此这里唯一的缺点是缓存效率的小损失。
这些限制不足以使BPF计划保持在100万条指令限制下。因此,作者需要将其分成较小的程序,由尾部呼叫加入,如下图所示。
因此,对MEMCACHED请求的处理分为7个BPF程序,每个程序都有自己的任务,包括计算键散列,准备回复数据包或将数据写入本地缓存或回复数据包。
说到回复数据包,您可能会想知道BMC如何创建它,因为BPF没有帮助程序来创建和发送数据包。事实证明,它们只是在BPF开发人员之间变得常见的方式回收所接收的数据包:
此EBPF程序增加了接收数据包的大小,并修改其协议标题以准备响应数据包,交换源和目标以太网地址,IP地址和UDP端口。
作者通过测量其BPF程序的尺寸和复杂性来开始评估,我绘制下面(不要错过的是复杂性的第二y轴)。他们使用LLVM 9.0与V1指令集和Linux V5.3。
首先,我们可以首先注意到通过数据包的Playload循环的程序(Update_cache,hash_keys,Invalidate_cache和write_reply)具有更高的复杂性。在指令数量和复杂性之间也没有明显的关系。这可能似乎是违反直观的,但到期为了使用循环:如果验证者需要行走循环的所有迭代,那么具有很少的指令的程序可能具有很高的复杂性。即使hash_keys具有比prepaster_packet更少的指令(142与178),所以它使用循环以迭代键的每个字节,它具有更高的复杂性(788K对181)。
X86和EBPF指令之间的相关性更清晰。JIDED程序通常需要多于其字节码对应物的指示,部分原因是X86 PROLOGUE&结尾和一些助手的内联4。
然后,作者潜入吞吐量评估。他们将BMC与其修补的Memcached,命名的MemcachedSR和未被捕获的Memcached进行比较。
它们将2.5 GB内存分配到BMC和10 GB以MEMCACHED在用户空间中,这使得与生产服务器相比相当小的MEMCACHED 5.THEIR评估工作负载由100万个键值对组成,其中ZIPF分布后请求密钥具有偏斜0.99.这一高度偏斜的分布非常赞成任何缓存机制,如BMC.PRODUCTING工作量也高度倾斜(CF.Book的纸张,图5),但如果两个是可比的,则目前尚不清楚。歪斜似乎可能对BMC的表现产生强烈影响。
作者首先衡量吞吐量,因为核心的数量增长。此评价表明:
当然,性能也取决于给予BMC可以在给出其限制的情况下处理多少。因此,作者将性能评估为支持的请求的数量(具有小于1KB的值)的增加。
我们可以看到,即使具有少量支持的请求(25%),BMC已经重链MEMCACHED的性能。
本文有很多评估,我不会在此处重现,包括:
表示BMC的评估即使使用总存储器的0.1%,也可以提高性能。这主要是由于偏斜的关键分布,但令人印象深刻!
与Memcached,Seastar的基于DPDK的实现的比较,使用较少的CPU资源在较少的同时表现出BMC优势。
这些强度吞吐量结果的原因是使用XDP,这允许BMC回答Linux网络堆栈中非常早期的请求。然而,堆栈中的这一点在此时的TCP请求将困难,这就是BMC的原因目前仅限于UDP请求。这也限制了BMC对Redis等其他键值存储的相关性。
因为redis请求仅在TCP上传输,所以将BMC调整为Redis需要支持TCP协议。这可以通过从EBPF程序发送确认或通过拦截通过TCP堆栈来重用现有的TCP内核实现来完成。
正如作者所指出的那样,它们可以拦截Linux堆栈中的TCP请求更高,但性能效益将更小。
虽然静态内存分配验证了BMC的EBPF程序,但它也浪费了内存.BMC遭受内部碎片,因为每个缓存条目都是由它可以存储和插入小于此绑定的数据的最大数据大小。
很难说这项工作如何是制作MEMCACHED服务器。赛道6似乎表示MEMCACHED可能更常见于TCP,除了可能在Facebook上也不清楚CPU - 而不是内存 - 是大多数MEMCACHED服务器上的瓶颈。
在任何情况下,都可以令人兴奋地看到应用程序协议。作者设法为应用程序协议创建了高性能缓存,尽管BPF验证者的约束,但虽然我会喜欢查看其他关键分布的吞吐量评估,本文的评估相当广泛。他们强调了BMC与Memcachedsr的各种权衡。去看看!
BMC和MEMCACHEDSR的源代码在GitHub上,具有在家中重现的步骤。
如何确定修剪点取决于内核版本,但它们可能包括辅助呼叫或分支目标。 ↩ SEASTAR通过TCP进行了更好的表现,MEMCACHED具有通过UDP套接字的锁定争用。 这可能是因为用户对TCP性能更感兴趣吗? ↩