ViewFlow,一个用于在没有气流的情况下写入数据模型的开源框架
在这篇文章中,我们介绍了ViewFlow,一个新发布的开源框架,允许数据科学家在不编写Airflow代码的情况下创建数据模型。
为了提供具有商业洞察的DataCamp,我们的数据科学家通过创建物化视图来构建其数据模型 - 复杂数据操作的结果。这些物化视图是基于原始数据创建的,并且通常依赖于其他物化视图。我们使用Apache Airflow,这是一个框架,允许用户以编程方式创建和安排数据工作流程。然而,编程apache气流可能是复杂且耗时的。我们在数据工作流程中的视图越多,我们必须编写和维护的空气流代码就越多。
在DataCamp,我们强烈认为,我们的数据科学家应该专注于写作观点(即写入SQL,R或Python代码,提供可操作的见解),而不是编写Airflow代码。
为了使我们的数据科学家能够避免编写Airflow代码,我们构建了ViewFlow。 ViewFlow是一个框架,它会自动将一系列SQL,R Markdown和Python文件转换为Apache Airflow Workflow,即由任务组成的定向非循环图(DAG)。 DAG是逻辑数据模型的气流实现,并且任务是视图的气流实现。
今天,我们很高兴通过释放ViewFlow源代码来宣布对开源社区的贡献!使用ViewFlow,不仅您的数据科学家们能够专注于他们所做的最佳信息 - 但他们将以更快的速度执行此操作,因为他们不需要担心数据工程任务。
在DataCamp,不仅我们教导数据科学,而且我们也做数据科学。我们有一个伟大的数据科学家团队,进行财务分析(ARR,收入份额,订阅,流失,......),内容分析(课程评级,项目完成,用户花费),营销分析(收购,转换,广告),并实施高级分析,例如课程建议或技能评估。
为了进行这些分析,我们的数据科学家会创建物化视图。物化视图来自(潜在复杂的)数据转换,例如聚合,加入或业务规则的实施。
取决于观点'复杂性,我们的数据科学家在SQL,R或Python中创建它们。他们可以自由地使用他们认为是最好的观点的语言。
创建或更新视图后,它们用于开发我们的仪表板,并且每个DataCamp员工都可以访问它们。 DataCamp Employees可以在SQL(例如,通过元数据库),R或Python中查询这些视图。我们再一次为用户提供适合最佳用例的语言。
很想了解我们如何允许用户轻松连接到R或Python的数据仓库?我们创建了两个内部软件包 - DataCampr和DataCampy,它们对我们的数据仓库处理身份验证,并为我们的数据科学家提供了有用方法来查询和修改数据。这些包将是未来博客文章的主题!
这些观点被认为是我们在公司中所做的每种商业决策的真理来源,是为实现新产品特征或为批判性财务决策的财务副总裁的产品经理。
我们使用Apache Airflow来安排创建视图的SQL查询的执行和R和Python脚本。在Airflow中,一个任务创建了一个视图,我们在不同的DAG中组织了这些任务 - 每位业务部门的一个(或多个)DAG(例如,营销,金融,内容)。该组织允许我们具有清晰可读的DAG,在那里很容易找到我们正在寻找的任务(例如,用于调试目的,或者在代码更改后手动触发它)。
我们共有19个DAG,在我们的Redshift数据仓库中创建了500多种景观。这是我们的财务表现:
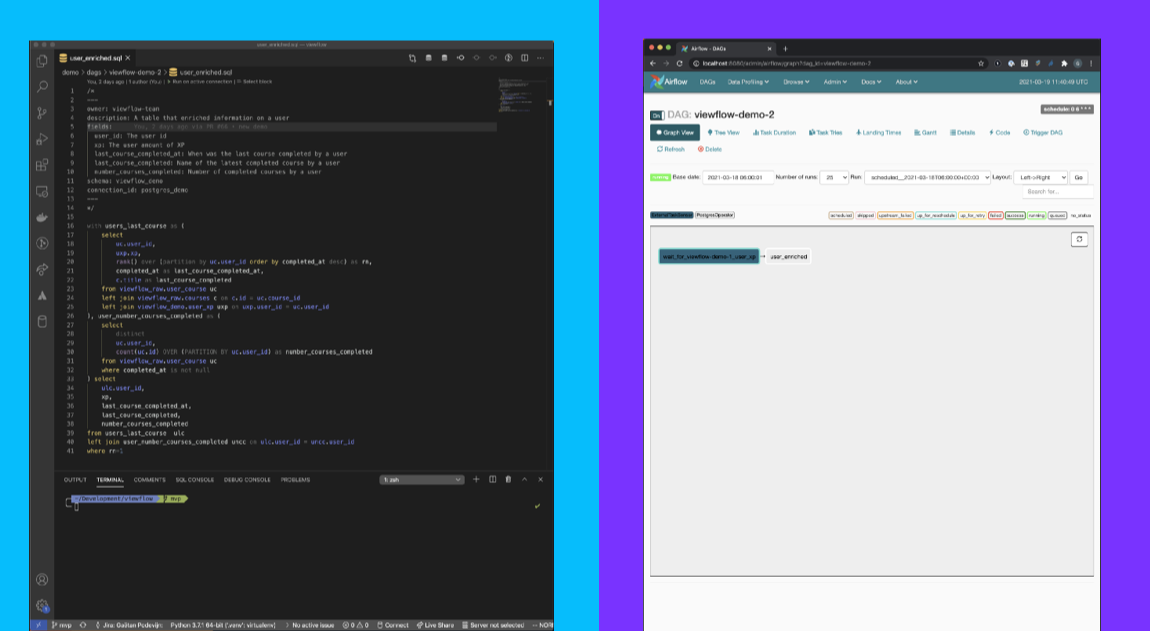
正如您在财务DAG中看到的那样,许多视图都有依赖关系,即它们使用先前创建的视图中的数据。这些依赖关系可以是内部或外部。内部依赖项是同一DAG中的上游视图(即,视图在DAG内连接)。外部依赖性是属于不同DAG的视图。在上面的图像中,内部依赖项被连接的两个任务描述。外部依赖性由具有深色背景(即气流中的外部任务传感器)的任务描述的外部依赖性。
如上所述所示,我们的DAG可能是非常复杂的,具有许多内部和外部依赖性。要在没有ViewFlow编写新视图,我们的数据科学家需要:
使用AirFlow API和正确的气流运算符更新新任务的Python DAG脚本。
编写Python代码以使用AirFlow API定义任务的内部和外部依赖项。
只有第一步创建数据科学价值。最后两个步骤不增加科学价值,但需要实现新视图。
此外,由于几个原因,最后两个步骤可能是有问题的。首先,它们需要具体的气流知识。其次,由于需要在数据科学和数据工程之间的上下文切换以及代码中手动编写逻辑之间的上下文切换,它们易于编程错误。第三,逻辑错误可能不会产生编程错误或异常,并且可以通过所有测试,但会产生难以识别和调试的不良最终用户数据。
例如,如果View C取决于视图A和B的数据(请参阅下图的左侧),但是一个没有手动设置为C的依赖性(参见下图的最右侧) ,然后C可能在更新A之前运行(取决于调度程序如何拾取任务)。在这种情况下,View C将更新,但不是最新的。由于设置逻辑依赖项中的错误,它将包含陈旧的数据。如果该视图用于高赌注业务决策,则该逻辑错误的后果可能很大。
ViewFlow是一个内置在气流顶部的框架,处理Airflow DAG和任务的创建,并自动管理任务依赖项(是内部或外部)。 ViewFlow使数据科学家能够专注于他们首选工具(SQL查询或R脚本或Python)中的视图创建逻辑。这显着降低了数据科学家的数据工程负担。
编写SQL查询或RMD或Python脚本以创建视图并提供其他元数据(例如,查看的描述,列'描述,请参阅下面的代码片段)。
通过照顾创建任务并设置任务的依赖项,ViewFlow提供:
数据科学家的生活质量改进。数据科学家选择他们的首选语言来解决问题,并将其对写数据科学代码的贡献。
减少上下文切换。由于数据科学家不需要编写气流代码并手动设置逻辑依赖性,因此数据科学和数据工程问题是分开的。添加视图不需要两个上下文。
增加速度。通过简化数据科学家'贡献流程,可以更快地添加新视图,并且该团队可能更响应请求。
Datacamp的使命是民主化数据科学。这对我们的用户来说是正确的,但这对我们来说也是如此。我们希望允许每个DataCamp ER(以及每个人,真的)成为数据驱动的。
ViewFlow是我们目标的一步。 viewflow有效地减少了进入的障碍。我们已经看到没有数据科学背景的DataCamp员工(例如,具有熟悉的SQL知识或产品经理的工程师)能够使用ViewFlow创建新视图,而无需编写单行的Airflow代码。
使用ViewFlow,无论您是数据科学家,您需要做的就是编写SQL,Python或R代码以产生新的见解。
ViewFlow对我们非常有用,并保持其承诺:数据科学家应该写视图,而不是气流代码。由于ViewFlow在DataCamp的好处,我们认为它可以帮助其他数据组织变得更加高效。我们很自豪地为开源社区贡献viewflow。
想要看到viewflow在动作中?在当地机器上运行我们的演示!演示创建一个带有ViewFlow的Airflow Docker集装箱以及用作数据仓库的Postgres Docker容器,其中创建了视图。如果为您提供ViewFlow,请务必遵循自述指示并根据您自己判断!
我们决定释放目前特征的子集目前的viewFlow支持(即,SQL和Python视图)。我们在内部使用的ViewFlow版本的某些组件是为Datacamp的特定用例编写的。例如,RMD视图在Amazon Fargate上执行。在其当前状态下,用户可以使用我们目前的所有视图流特征是复杂的。但是,我们强烈认为SQL和Python视图可能非常有用。我们将在未来几个月继续添加新的视图类型(例如,RMD,Jupyter Notebook)。当然,如果您看到ViewFlow中的值并希望贡献,请不要犹豫,创建拉出请求或新功能请求!
如果您想成为致力于民主化数据科学的才华横溢的团队的一部分,请查看我们的开放职位!