Deepfake探测器可以击败,计算机科学家首次展示
计算机科学家首次在2021年1月5日至9日在线举行的WACV 2021大会上展示了旨在检测深度欺诈的系统(即通过人工智能操纵真实镜头的视频)的系统。
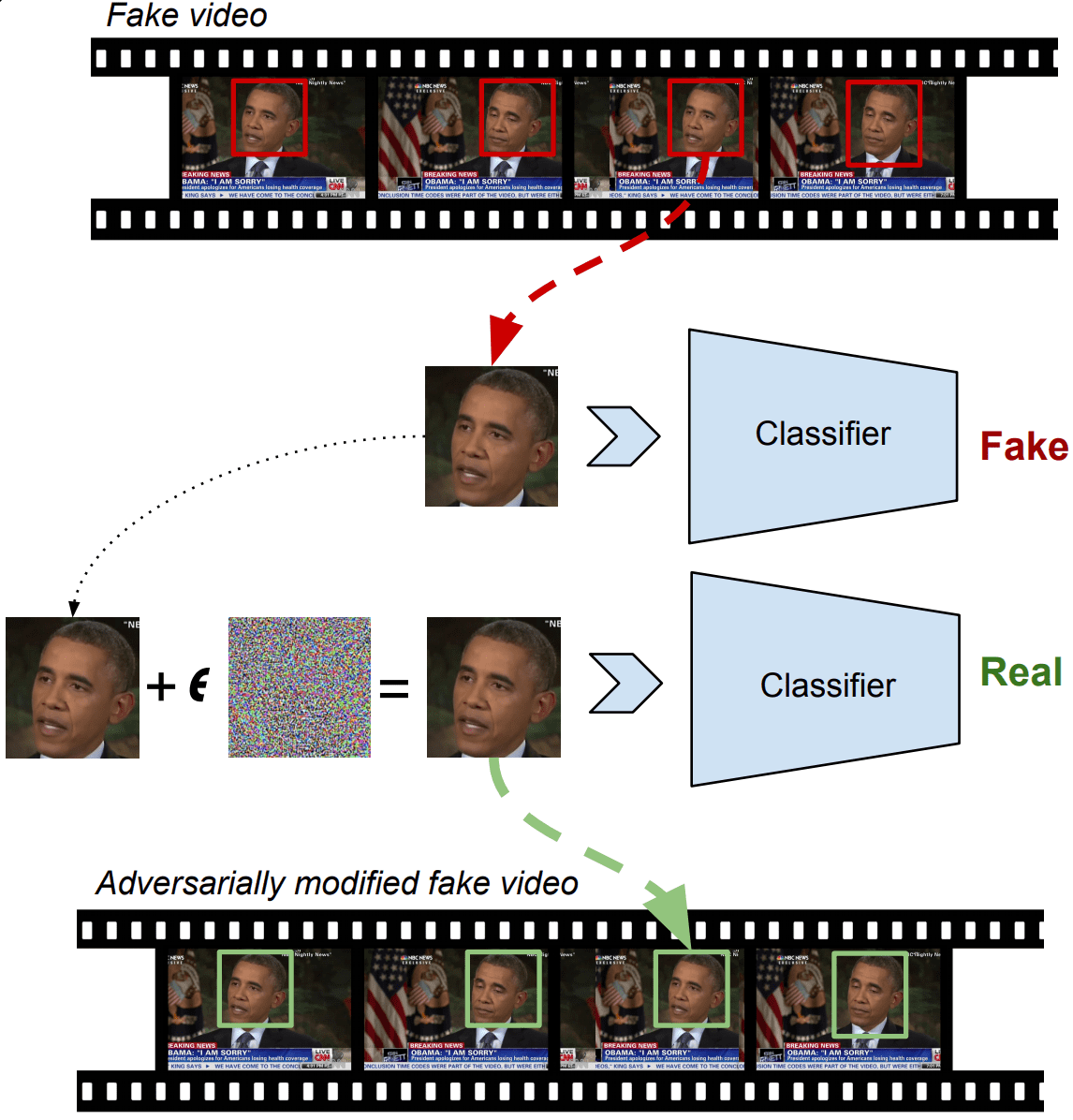
研究人员表明,可以通过在每个视频帧中插入称为对抗示例的输入来击败检测器。对抗示例是经过稍微操纵的输入,这些输入导致诸如机器学习模型之类的人工智能系统出错。此外,该团队表明,在视频压缩后,攻击仍然有效。
"我们的工作表明,对Deepfake检测器的攻击可能是现实世界中的威胁,"加州大学圣地亚哥分校计算机工程博士学位的Shehzeen Hussain说。学生,也是WACV论文的第一作者。 "更令人震惊的是,我们证明,即使对手可能不知道检测器使用的机器学习模型的内部工作原理,也可以制作出强大的对抗性深渊仿冒品。
在伪造品中,对对象的脸部进行修改以创建从未发生过的令人信服的逼真的镜头。结果,典型的Deepfake探测器将注意力集中在视频中的面部:首先对其进行跟踪,然后将裁剪后的面部数据传递到确定其是真实还是伪造的神经网络。例如,眨眼在伪造品中无法很好地再现,因此检测器将注意力集中在眼睛的运动上,以此作为确定眼睛的一种方法。最先进的Deepfake检测器依靠机器学习模型来识别假视频。
研究人员指出,假冒视频在社交媒体平台上的广泛传播引起了全球的广泛关注,尤其是阻碍了数字媒体的信誉。 "如果攻击者对检测系统有一定的了解,他们可以设计输入以瞄准检测器的盲点并绕过检测器,"该论文的另一位第一作者,加州大学圣地亚哥分校的计算机科学专业学生Paarth Neekhara说。
研究人员为视频帧中的每个面孔创建了一个对抗性示例。但是,尽管诸如压缩和调整视频大小之类的标准操作通常会从图像中删除对抗性示例,但这些示例旨在承受这些过程。攻击算法通过估计一组输入转换来实现此目的,模型将模型如何将图像分类为真实或伪造。从那里开始,它使用这种估计来转换图像,以使对抗图像即使在压缩和解压缩之后也保持有效。然后将脸部的修改版本插入所有视频帧中。然后对视频中的所有帧重复此过程,以创建Deepfake视频。攻击还可以应用于在整个视频帧上运行的检测器,而不仅仅是面部作物。
该小组拒绝发布其代码,因此敌对方不会使用该代码。
研究人员在两种情况下测试了他们的攻击:一种是攻击者可以完全访问检测器模型,包括面部提取管道以及分类模型的体系结构和参数。攻击者只能查询机器学习模型来找出一帧被归类为真假的可能性。在第一种情况下,未压缩视频的攻击成功率超过99%。对于压缩视频,比例为84.96%。在第二种情况下,未压缩的成功率为86.43%,压缩视频的成功率为78.33%。这是展示对最先进的Deepfake检测器进行成功攻击的第一项工作。
"要在实践中使用这些Deepfake检测器,我们认为有必要对那些了解这些防御并且有意试图挫败这些防御的适应性对手进行评估,这很重要。研究人员写道。 "我们表明,如果攻击者对检测器具有完全或什至部分的知识,则可以很容易地绕过深度检测的最新方法。
为了改进探测器,研究人员推荐了一种类似于对抗训练的方法:在训练过程中,自适应对手会继续产生新的深造假货,从而可以绕过当前先进的探测器;检测器继续改进以检测新的深层伪造。
对抗性Deepfakes:评估Deepfake检测器对对抗性示例的漏洞Shehzeen Hussain,Malhar Jere,Farinaz Koushanfar,加州大学圣地亚哥分校电气和计算机工程系Paarth Neekhara,Julian McAuley,加州大学圣地亚哥分校计算机科学与工程系
加州大学圣地亚哥分校的Studio 10 300提供广播和电视连接,可与我们的教员进行媒体采访,可以通过进行协调。(必须启用JavaScript才能查看此电子邮件地址)。要与加州大学圣地亚哥分校的教职专家联系,讨论有关问题和趋势新闻的趋势,请访问https://ucsdnews.ucsd.edu/media-resources/faculty-experts。