一种检测浏览器指纹的动态方法
在之前的两篇文章中,我们介绍了浏览器指纹识别的问题,并展示了基于JavaScript文件原始文本内容的静态指纹检测器AI。现在,我们将完善解决方案,并考虑JavaScript文件的动态行为。
您是否知道65.1%的人认为Internet服务提供商应该保护他们免受不必要的跟踪?有关此类的更多见解,请参阅我们的在线隐私和跟踪感知调查。
静态方法在JavaScript源代码中搜索可疑的代码段。该技术的一个弱点是,即使不执行可疑代码段,它也会发出指纹信号。避免此问题的自然方法是检查访问网站后执行的函数调用。我们将基于函数调用的方法称为动态方法。
在其他领域也存在静态与动态的区别。例如,静态恶意软件检测器基于分析可执行文件的原始字节。另一方面,动态恶意软件检测器在沙盒环境中运行可执行文件并检查其行为。静态方法更简单,更便宜,但是动态方法可以提供更高的准确性。
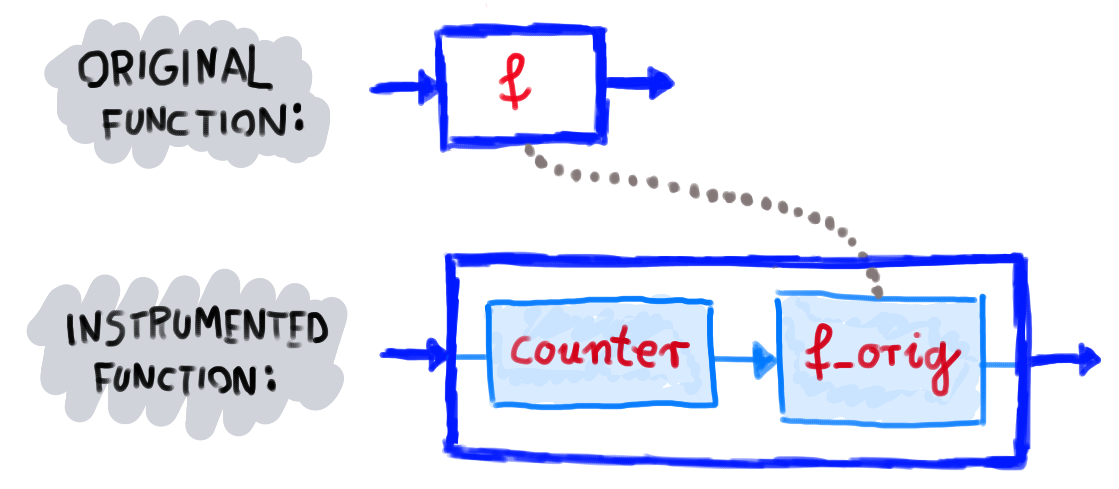
自定义网络浏览器的JavaScript引擎并非易事。在探索了多种可能性之后,我们选择使用无头Chrome浏览器,并应用Chrome DevTools协议对其进行检测。这使我们可以用内置函数替换内置函数。如果有内置函数f,我们将其另存为f_orig之类的名称,然后重新定义f,以便它运行检测代码并调用f_orig。
然后,我们使用定制的Chrome浏览器访问了网站。为了从浏览器中提取函数调用数据,我们利用了浏览器的控制台日志。我们将带注释的消息写入控制台日志,并从Python处理这些消息。
准备带标签数据集的教科书方法是对网络上可用的JavaScript文件进行统一采样,并在运行时逐行手动对其进行分析。但是,这将是一项巨大的工作,因为现实生活中的JavaScript文件通常包含数千行缩小的代码。因此,我们采用启发式方法进行数据收集,并尝试承受采样不均匀的危险。
–每个数据点对应一个网站×JavaScript对。当同一JavaScript文件嵌入到其他网站中时,其行为可能会有所不同。
–为了收集第一批正面示例(浏览器指纹识别的案例),我们从各种反跟踪列表中提取了候选对象。然后,分析人员访问了这些站点,并使用浏览器的开发人员工具调查了JavaScript文件的行为。如果分析人员看到浏览器指纹清晰的迹象,则该网站×JavaScript对被标记为肯定。如果我们无法为候选人识别明确的指纹迹象,那么我们就将其从标记数据中剔除,作为不清楚的案例。
–为了收集第一批否定示例(没有浏览器指纹的情况),我们尝试使用常识来生成一组候选项。我们包括了反跟踪组织的网站,一些受欢迎的网站以及从跟踪角度看无害的其他随机网站。然后,分析师逐行调查了JavaScript文件。如果我们可以确定地说该代码不包含浏览器指纹,则可以将给定的网站×JavaScript对标记为否定。否则,作为未知情况,我们将其排除在标记数据之外。
–为了收集更多批次的数据点,我们在数据集的第一个版本上训练了一个简单的分类器。然后,我们爬网并在访问的网站×JavaScript对上运行分类器。然后,我们从该集合中选取候选人,并尝试利用分类器提供的解释来手动验证分类器的决定。如果我们可以清楚地确认或否决机器的决定,则将案例添加到标记的数据集中。否则,我们将其作为不清楚的案例而忽略。
–数据收集的另一个困难是有头和无头浏览器之间的区别。分析师使用头戴式浏览器进行调查,但网络爬网由无头浏览器执行。因此,我们需要仔细检查headed和headless方法是否产生相同(或几乎相同)的函数调用。如果存在差异,我们将从标记的数据集中删除给定的案例。
–我们对数据集应用了重复数据删除。如果多个数据点具有相同的特征向量,则我们仅保留1个数据点。
经过所有这些努力,我们总共获得了409个带标签的示例。数据集相当均衡:258个示例为负(63%),151个为正(37%)。否定示例是https://www.roomkey.com/js/connector/connector.js(网站:https://wyndhamhotels.com)。肯定示例是https://www.mobile.de/resources / c0ad9057f4200d85dea57fe1e15731(网站:https://mobile.de)。
机器学习算法的输入是一个数字表。行对应于示例(在本例中为JavaScript文件),列对应于示例的各种数字属性(称为功能)。
我们从可与指纹关联的属性访问和函数调用事件派生了特征。我们总共选择了76个属性和30个功能,并为每个属性分配了一个计数器。如果访问了属性或调用了函数,则相应的计数器增加。这些功能可以分为以下几组:
window.navigator属性(43个功能):该组包括计数器,用于计数器的知名指纹指示器(例如插件和javaEnabled),以及用于非常规指示器的计数器,例如mediaCapabilities和maxTouchPoints。
window.screen属性(33个功能):屏幕属性已长时间用于指纹识别。该组中的一些示例功能是availHeight,availWidth,colorDepth和fontSmoothingEnabled。
画布功能(23个功能):画布指纹识别[2]通过利用HTML5画布元素来工作。指纹脚本以其选择的字体和大小绘制文本,并添加背景色。然后,将画布像素数据的哈希码用作指纹。我们在该组中定义的一些示例计数器功能是fillText,fillRect和toDataURL。
音频功能:(6个功能):音频指纹[3]在概念上类似于画布指纹,但是它利用音频上下文和振荡器节点元素而不是画布。我们在该组中定义的一些示例计数器功能是createOscillator,createDynamicsCompressor和振荡器_start。
其他(11个功能):该组包含与窗口属性或画布/音频功能无关的其他功能。
定义功能之后,就该训练机器学习模型了。我们将比较7种不同的模型。第一个是逻辑回归,其余六个是基于树的非线性模型。应用的评估方案是20倍交叉验证。评估指标是准确性(#正确决策/#所有决策)。为了实现实验,我们使用了scikit-learn。下表中汇总了结果:
所有算法的交叉验证准确性都很高(超过90%)。最佳分数是通过最复杂的模型获得的(#7:max_depth = 3的GradientBoosting)。这表明我们提出的计数器功能是指纹的有力指标,并且与标签的关系并非无关紧要。
GradientBoosting算法为每个输入要素提供了一个重要值。让我们研究一下#7模型对功能重要性的看法:
两个最可预测的功能是cpuClass和fillRect。每个cpuClass×fillRect值的标签分布如下所示(特征值是整数,但点在网格单元中随机扰动以提高可见性):
如果未访问窗口导航器的cpuClass属性,并且未调用画布的fillRect函数,则JavaScript可能未执行浏览器指纹识别(请参阅左下角的单元格)。如果计数器大于0,则指纹识别的可能性很高,尤其是当两个计数器都大于0时。
问题出现了:我们如何利用机器学习分类器在现实世界中提供实用价值?一种解决方案(已经内置在CUJO AI Incognito中)是自动生成基于AI的域黑名单。该方法的概述如下:
–因此,我们获得了潜在威胁用户隐私的候选JavaScript文件列表。
–最后,我们对候选列表进行后处理:–我们确定仅包含跟踪JavaScript文件而不包含合法JavaScript文件的域。 可以安全地阻止这些域,而不会损害用户体验。 安全阻止域已添加到隐身域的黑名单中。 有兴趣了解更多关于我们如何使用AI保护人们免受在线跟踪的信息吗? 下载隐身白皮书。 基于AI的方法的优势在于,它可以检测尚未包含在公开来源中的零日跟踪器。 因此,我们可以针对跟踪器提供更强的保护。 从我们的研究团队获得最新见解,并紧贴行业趋势。 我们从不发送垃圾邮件。



