PGM索引:与B树性能匹配的学习索引,空间减少了83倍
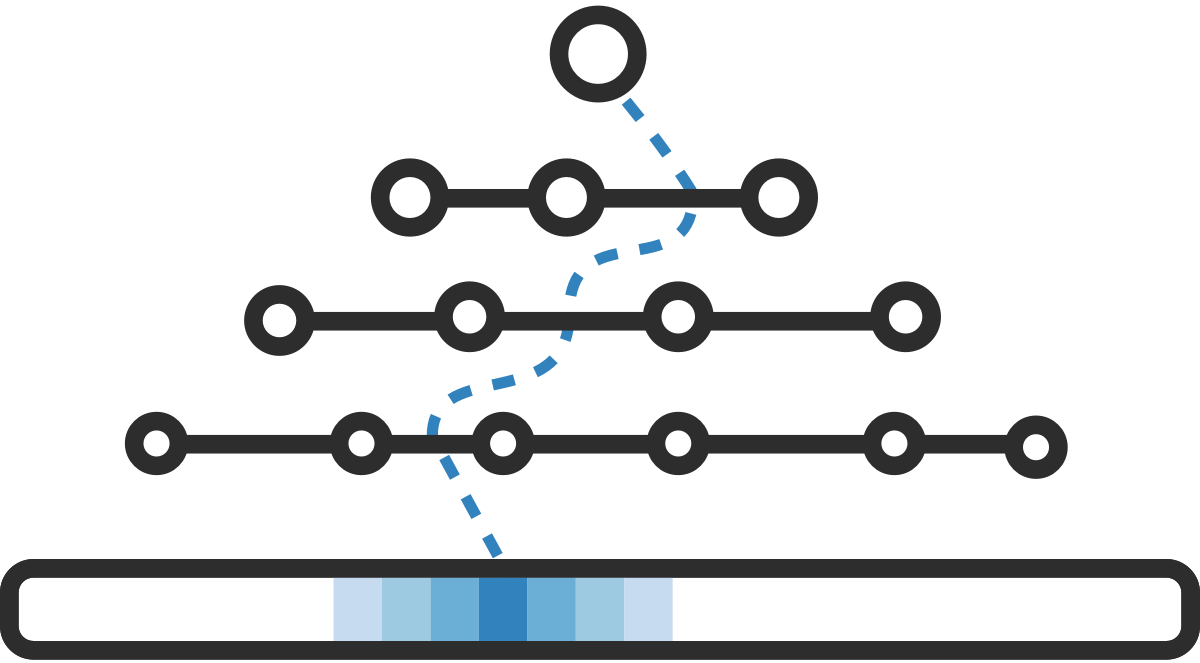
分段几何模型索引(PGM-index)是一种数据结构,它可以使用比传统索引少的数量级空间,对数十亿个项目的数组进行快速查找,前身,范围搜索和更新,同时提供相同的最坏情况查询时间保证。
与传统的基于树的索引不了解输入数据中可能存在的规律性不同,PGM索引在索引键及其在内存中的位置之间利用了学习的映射。这种映射的简洁性,加上独特的递归构造算法,使PGM-index成为一种数据结构,在空间上以数量级控制着传统索引,同时仍提供了最佳的查询和更新时间性能。
除此之外,PGM索引还提供了压缩,分发感知和多准则适应性,因此适合解决对大数据系统的日益增长的需求,这些大数据系统适应各种现代设备和产品所带来的快速变化的约束。应用程序。
这是有关学习索引的第一批结果之一,该索引通过捕获输入数据的分布来达到惊人的性能。
与某些早期结果不同,PGM-index是一种学习型索引,具有可证明的最佳时间和空间复杂性保证。
它总是比传统的基于树的索引占用更少的空间,通常少几个数量级。如果这还不够,那么甚至还有压缩版本。
您可以通过适当设置其参数之一来调整索引以适应内存层次结构,空间占用率和时间效率。
自动调谐器使您可以指定最大查找时间(或空间占用),并获得相应的空间效率最高(或最快)的PGM-index配置。
#include< vector> #include< cstdlib> #include< iostream> #include< algorithm> #include" pgm / pgm_index.hpp" int main(){//生成一些随机数据std :: vector<整数>数据(1000000); std :: generate(data。begin(),data。end(),std :: rand);数据。 push_back(42); std :: sort(data。begin(),data。end()); //构造PGM-index const int epsilon = 128; //时空权衡参数pgm :: PGMIndex< int,epsilon>索引(数据); //查询PGM-index auto q = 42;自动范围=索引。搜索(q);自动lo =数据。 begin()+范围。罗; auto hi =数据。 begin()+范围。你好; std :: cout<< * std :: lower_bound(lo,hi,q);返回0; }
保罗·费拉吉娜(Paolo Ferragina)和乔治·芬奇瓜拉(Giorgio Vinciguerra)。 PGM索引:具有可证明的最坏情况边界的全动态压缩学习索引。 PVLDB,13(8):1162-1175,2020。
Paolo Ferragina,Fabrizio Lillo和Giorgio Vinciguerra。为什么学习的索引如此有效?在:第37届国际机器学习会议(ICML 2020)的会议记录中。
如果您使用图书馆,请在此网站上放置一个链接,并引用以下文章:
保罗·费拉吉娜(Paolo Ferragina)和乔治·文西格拉(Giorgio Vinciguerra)。 PGM索引:具有可证明的最坏情况边界的全动态压缩学习索引。 PVLDB,13(8):1162-1175,2020。
@article {Ferragina:2020pgm,作者= {Paolo Ferragina和Giorgio Vinciguerra},标题= {{PGM-index}:具有可证明的最坏情况边界的全动态压缩学习索引},年份= {2020},数量= {13},Number = {8},Pages = {1162--1175},Doi = {10.14778 / 3389133.3389135},Url = {https://pgm.di.unipi.it},Issn = {2150-8097} ,Journal = {{PVLDB}}}
PyGM。 Python排序容器的软件包,使用PGM-index来提高查询性能和内存使用率。 我们很高兴得知您是否在项目中使用了我们的代码。 我们将在这里列出PGM-index最有趣的应用! 有很多方法可以为这个项目做贡献,仅举几例: 使索引知道SIMD。 例如,可以将错误设置为SIMD寄存器宽度,并使用矢量指令遍历没有分支的索引级别。



