基于ARM的AWS EC2实例上的PostgreSQL
Jobin Augustine数据中心中ARM处理器的预期增长一直是讨论的热门话题,而且我们很好奇它在PostgreSQL中的表现。用于测试和评估的基于ARM的服务器的普遍可用性是一个主要障碍。破冰者是AWS在2018年在其云中宣布其基于ARM的处理器产品的时候。但是我们并没有立即看到太多兴奋,因为许多人认为它是“实验性”的东西。我们对于将其推荐用于关键用途也持谨慎态度,并且从未付出足够的努力来评估它。但是,当基于Graviton2的第二代实例于2020年5月发布时,我们要认真考虑。我们决定从运行PostgreSQL的角度来独立研究新实例的价格/性能。
重要提示:请注意,虽然很想在x86和arm上进行这种PostgreSQL比较,但这并不正确。这些测试将PostgreSQL在两个虚拟云实例上进行了比较,其中不仅包括CPU,还包括更多的活动部件。我们主要关注基于两种不同架构的两个特定AWS EC2实例的性价比。
对于此测试,我们选择了两个类似的实例。一种是较旧的m5d。 8xlarge,另一个是基于Graviton2的新m6gd。 8xlarge。这两个实例都带有本地“临时”存储空间,我们将在这里使用它们。使用速度非常快的本地驱动器应有助于揭示系统其他部分的差异,并避免测试云存储。这些实例并不完全相同(如下所示),但距离足够近,可以被认为是同一等级。我们使用了来自pgdg repo的Ubuntu 20.04 AMI和PostgreSQL 13.1。我们使用较小(内存中)和较大(io绑定)的数据库大小进行了测试。
根据北弗吉尼亚州Linux的AWS定价信息,对实例进行规范和按需定价。使用当前列出的价格,m6gd。 8xlarge便宜25%。
实例:m6gd.8xlarge 虚拟CPU:32 内存:128 GiB 储存:1 x 1900 NVMe SSD(1.9 TiB) 价格:每小时$ 1.4464
实例:m5d.8xlarge 虚拟CPU:32 内存:128 GiB 储存:2 x 600 NVMe SSD(1.2 TiB) 价格:每小时$ 1.808
我们为实例选择了Ubuntu 20.04.1 LTS AMI,并且在操作系统方面未做任何更改。在m5d.8xlarge实例上,两个本地NVMe驱动器统一在一个raid0设备中。 PostgreSQL是使用PGDG信息库中的.deb软件包安装的。
postgres =#选择版本(); 版 -------------------------------------------------- -------------------------------------------------- ------------------------------------ aarch64-unknown-linux-gnu上的PostgreSQL 13.1(Ubuntu 13.1-1.pgdg20.04 + 1),由gcc(Ubuntu 9.3.0-17ubuntu1〜20.04)9.3.0,64位编译 (1列)
max_connections =' 200' shared_buffers =' 32GB' checkpoint_timeout =' 1h' max_wal_size =' 96GB' checkpoint_completion_target =' 0.9' archive_mode =&on' archive_command =' / bin / true' random_page_cost =' 1.0' Effective_cache_size =' 80GB' maintenance_work_mem =' 2GB' autovacuum_vacuum_scale_factor =' 0.4' bgwriter_lru_maxpages =' 1000' bgwriter_lru_multiplier =' 10.0' wal_compression =' ON' log_checkpoints =' ON' log_autovacuum_min_duration =' 0'
首先,使用pgbench(PostgreSQL附带的微基准标记工具)进行了初步的测试。这使我们可以测试多个客户和工作的不同组合,例如:
pgbench创建的默认负载是类似tpcb的读写负载。我们在未启用校验和的PostgreSQL实例上使用了相同的命令。我们可以看到ARM的性能提高了19%。
我们很好奇校验和计算是否由于体系结构差异而对性能有任何影响。如果启用了PostgreSQL级别的校验和。从PostgreSQL 12开始,可以使用pg_checksum实用程序启用校验和,如下所示:
令我们惊讶的是,结果略好!由于差异仅为1.7%,因此我们将其视为噪音。至少我们可以断定,启用校验和不会对这些现代处理器造成明显的性能下降。
只读负载应以CPU为中心。由于我们选择的数据库大小完全适合内存,因此可以消除与IO相关的开销。
结果显示,与x86实例相比,ARM的tps增长了30%。
我们想检查如果负载完全以CPU为中心时启用校验和,是否可以观察到tps的变化。
在pgbench测试中,我们观察到随着负载以CPU为中心,性能差异会增加。我们无法通过校验和观察到任何性能下降。
当页面被写出并在缓冲池中读取时,PostgreSQL计算并写入页面的校验和。此外,启用校验和时,总是记录提示位,从而增加了WAL IO压力。为了正确地验证总的校验和开销,我们需要更长和更大的测试,这与对sysbench-tpcc所做的类似。
我们决定使用sysbench-tpcc执行更详细的测试。我们主要对数据库适合内存的情况感兴趣。附带说明一下,虽然臂架服务器上的PostgreSQL没有出现问题,但与x86相比,sysbench更为灵活。
在这种中等负载下,ARM实例的性能比x86实例高出约15.5%。在此前后,百分比差基于平均tps值。
您可能想知道为什么在测试结束时性能突然下降。它与带有full_page_writes的检查点有关。即使在内存测试中我们使用了pareto分布,每个检查点之后也会写出相当多的页面。在这种情况下,WAL实例比实例实例显示更多的性能触发了WAL检查点。这些下降将在所有执行的测试中出现。
将实例逼近其饱和点(请记住,两个实例均为32 cpu实例),我们发现差异进一步降低到4.5%。
当两个实例都超过其饱和点时,性能的差异可以忽略不计,尽管仍为1.4%。此外,当并发时,我们可以观察到ARM的吞吐量(tps)下降了6-7%,x86的下降了4%。在这32个vCPU机器上从64增加到128。
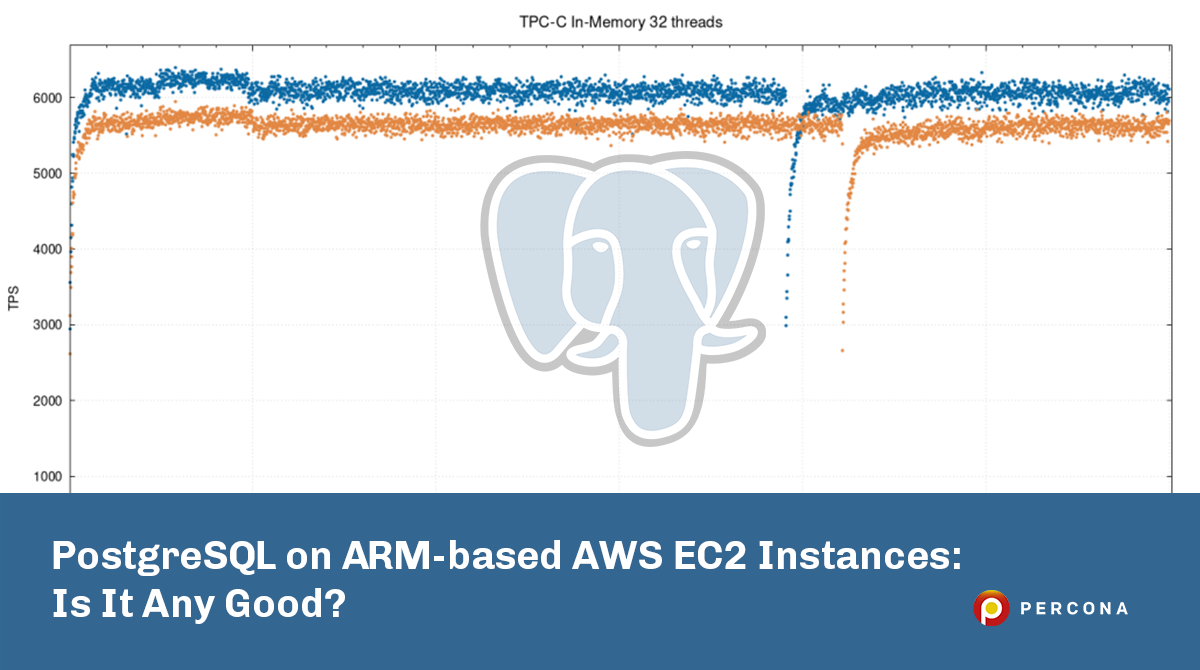
并非我们所测量的所有内容都适合基于Graviton2的实例。在IO绑定测试(约200G数据集,200个仓库,均匀分布)中,我们看到两个实例之间的差异较小,并且在64和128个线程下,常规m5d实例的性能更好。您可以在下面的组合图中看到这一点。
造成这种情况的一个可能原因,尤其是对于m6gd.8xlarge在128个线程处发生的严重崩溃是因为它缺少m5d.8xlarge拥有的第二个驱动器。目前尚无完全可比的实例,因此我们认为这是一个合理的比较;每个实例类型都有一个优势。由于我们希望本地驱动器对测试的影响可以忽略不计,因此需要更多测试和配置文件才能正确识别原因。可以执行EBS的IO绑定测试,以尝试从等式中删除本地驱动器。
可以从此GitHub存储库中获得有关测试设置,测试结果,使用的脚本以及测试期间生成的数据的更多详细信息。
在我们执行的测试中,很少有ARM实例比x86实例慢的情况。在过去几天的整个测试过程中,测试结果均保持一致。尽管基于ARM的实例便宜25%,但在大多数测试中,与基于x86的实例相比,它可以显示15-20%的性能提升。因此,基于ARM的实例在所有方面最终都具有更好的性价比。我们应该期望将来有越来越多的云提供商提供基于ARM的实例。如果您希望查看任何其他类型的基准测试,请告诉我们。