跨基础架构的角色配置文件模式作为代码
时光倒流,PuppetLabs推广的“角色配置文件”模式节省了许多复杂的部署。这是使用配置工具Puppet的一种方法,该方法是:
并将其中的一些带入Terraform和Kubernetes配置的世界真是太好了。
如果您在多家公司从事Terraform的工作,您可能会发现文件夹结构,模块使用和环境升级的方法大不相同。在CTS,我们尝试基于“角色配置文件”模式来正式化我们的基础设施即代码(IaC)方法。我们发现,角色配置文件模式是一种有用的概念模型,不仅适用于配置(Puppet),而且适用于资源调配(Terraform + Terragrunt)和Kubernetes(Kustomize)中的应用程序层部署。
Puppet Labs的Craig Dunn制作了一个很棒的幻灯片,在这里详细介绍了Role-Profile模式的设计:
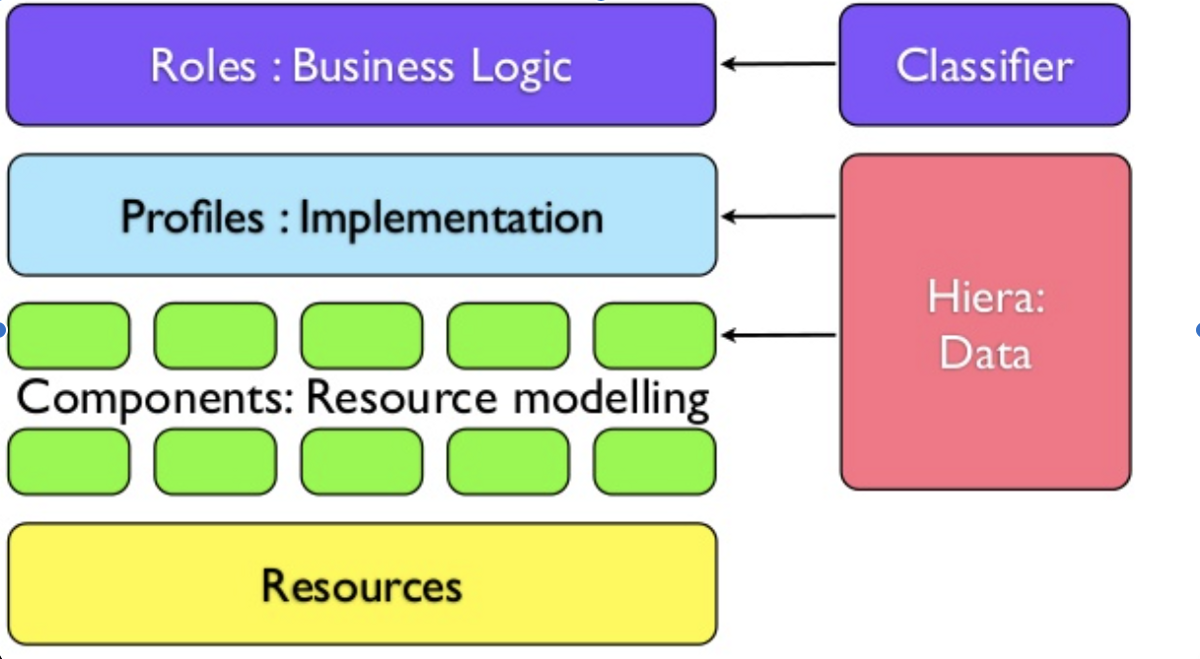
在下面的堆栈图中,角色,配置文件和组件都编写在Puppet DSL中。
角色代表业务逻辑,而不是技术,并以此名称命名。 uat_server,存档。
配置文件定义了一组组件,并以它们实现的逻辑技术堆栈命名,例如数据库,电子邮件
如果您不了解Puppet,那么足以知道有一个系统(节点分类器)可以将节点(又名机器或VM)映射到角色。 例如,一台机器可以由节点分类器分配给UAT服务器角色,并具有以下配置文件: 在这里,UAT Server是业务逻辑,因此是角色,并且三个配置文件正好构成了角色组成。 最后,Puppet使用了另一个名为Hiera的工具来分离每个层的自定义。 Puppet还就在角色-配置文件方法中应如何使用Hiera提出了一些强有力的建议。 参见规则部分: 这些规则很有趣,因为它们封装了有助于确保概要文件和组件可组合和可重用的最佳实践。 组件级配置,用于在多个项目中不变的事情(在组件中设置)
配置文件级别的配置,用于在环境之间不会发生变化的事情(对组件进行参数化,在配置文件本身中设置配置,或者对配置文件进行参数化并使用通用配置)
在不同环境中发生变化的事物的概要文件级别配置(对概要文件进行参数化并根据环境进行设置)
这些规则将指导我们如何以及在何处配置带有角色配置文件模式的Terraform。让我们看看如何将图案应用于Terraform。
如果您尚未使用Terragrunt,则可以解决某些Terraform问题(并介绍一些它自己的问题)。在CTS,每天有数百个Terraform跨多个客户部署,我们对减少失败的Terraform运行的爆炸半径非常感兴趣。
通常,对于具有足够复杂的基础架构的公司而言,一旦这成为问题,最容易做的就是将代码库分成多个Terraform运行。也许这样组织:
现在,这种脱钩意味着在您说应用程序更新时,您绝不会冒网络层的任何风险—但是它确实存在问题:
如何保持排序(将图形拆分为层数后,Terraform能够计算的所有不错的图形依赖关系都会消失)
也许您会编写定制脚本来维持顺序?但是仍然没有真正的依赖管理。随着时间的流逝,是什么阻止您在层之间引入循环依赖关系?也许您将使用TF状态或数据源来发现各层之间的数据,但这是临时的,并添加了许多以前不需要的代码。
幸运的是,Terragrunt以一致的方式解决了许多此类问题。 Terragrunt文档本身在解释动机和功能方面做得很好。
下表显示了三层存储库如何映射到“角色配置文件”模式以及理想情况下应如何使用它们。
从上面示例的左侧开始,在Terragrunt Infra Repo中,我们在europe-west-2地区的过渡环境中拥有cloudm目录。
可以将此cloudm目录视为Puppet角色:它是承载CTS之一所需的基础结构。产品。它需要一个GCP项目和一个GKE集群。这由子目录gke和service-project以及每个子目录中的配置terragrunt.hcl定义。
与Puppet和Hiera不同,角色配置不会分离。它也不是正式定义的实体,即复制cloudm角色以有效地复制目录并为hcl配置适当的值。但是,这仍然是一项重大改进-该层中没有明确的Terraform资源。
接下来,我们有Terragrunt模块层-如果以gke-private-cluster模块为例,它包装了terraform-google-kubernetes模块,在这种情况下,添加了一些路由和DNS。在更复杂的模块中,可以调用多个供应商模块。我们在这里确保可靠的通用设置,并记录CTS如何认为最好在所有环境中调用供应商提供的各种模块。
最后是供应商模块-来自Google之类的供应商模块,它们是基金会计划的一部分,提供了最佳实践模块。它们可以从GitHub或Terraform Registry获得。它们几乎直接与Puppet组件进行比较,这些组件通常是从Puppet Forge提取的模块。
人们不会写有关Terragrunt的文章,也不会拥护不可变版本部署的优点。在Terragrunt模块存储库层,我们能够跨多个模块进行更改,并在存储库级别使用git标签来及时修复该代码库。我们在Infra-live层中指定的每个环境中的env_version文件中指定该标记(请参见上面的阶段层次结构)。每个terragrunt.hcl文件在链接到要使用的配置文件时都使用该标记。现在,我们可以更改多个模块,并一步一步地进行开发。如果一切顺利,我们可以将阶段env_version文件撞到相同的标签,以进行非常容易的升级,我们知道该升级已经过测试。
最后要提到的一件事是,我们使用亚特兰蒂斯监视Terragrunt Infra存储库,并根据请求请求自动进行计划。它配置为仅在配置文件级别运行Terragrunt。它扮演了Puppet Master的角色(甚至是K8s世界中的ArgoCD,也许是另一个可以探索的抽象概念)
角色配置文件+组件模式非常适合Terragrunt和Terraform。目前,Terragrunt-Infra to Role是该模式中最弱的映射。但是,在配置,角色定义和分类器的组合角色中,它运行良好。概要文件和组件映射是清晰明显的。
允许非常快速地部署新客户(我们需要做的就是建立实时仓库,即从我们的配置文件库中挑选樱桃)。
轻松过渡到Terraform 12-许多艰苦的工作是由其他人在Vendor(component)模块中完成的。
为DevOps工程师提供通用的概念模型。这在某种程度上与我们快速部署的能力有关,从长期来看可能是最有价值的成果。知道如何构造一个新项目(配置和代码的每个部分都应该存在)时,面对空白时,可以消除很多精神负担。
我们还将此模式扩展到了Kustomize和ArgoCD部署的Kubernetes,但这是另一篇博客文章! 乍一看,名为TerraServices的最终模式看起来可以映射到配置文件(Infra-Module层)。 OpenCredo将它们称为独立的逻辑组件。 OpenCredo继续讨论Orchestrating Terraform,因为所有孤立的状态都需要大量的协调。 希望我已经展示了Terragrunt是一个很好的解决方案-它是开源的,可以解决依赖关系,并且提供了在孤立运行之间共享数据的通用方法。



