面向编程语言创建者的LLVM完整指南
本系列的编译器教程适用于不只是想要创建玩具语言而想要对象的人。您想要多态。您想要并发。您想要垃圾回收。等一下你不要GC?好的,不用担心,我们不会那样做:P
如果您在此阶段刚刚加入该系列,这里有个简短的回顾。我们正在设计一种Java风格的并发面向对象编程语言Bolt。我们已经完成了编译器前端,在其中进行了解析,类型检查和数据流分析。我们已经简化了语言,以便为LLVM做好准备-主要的收获是对象已简化为结构,其方法已简化为函数。
了解LLVM,您将成为朋友的羡慕对象。 Rust将LLVM用于其后端,因此它一定很酷。您将在所有这些性能基准上击败它们,而无需手动优化代码或编写机器汇编代码。嘘,我不会告诉他们。
可以在deserialise_ir文件夹中找到用于已删除的表示形式(我们称为Bolt IR)的C ++类定义。这篇文章的代码(LLVM IR生成)可以在llvm_ir_codegen文件夹中找到。回购使用Visitor设计模式并充分使用std :: unique_ptr来简化内存管理。
要遍历样板,以了解如何为特定语言表达生成LLVM IR,请搜索包含相应ExprIR对象的IRCodegenVisitor :: codegen方法。例如对于if-else语句:
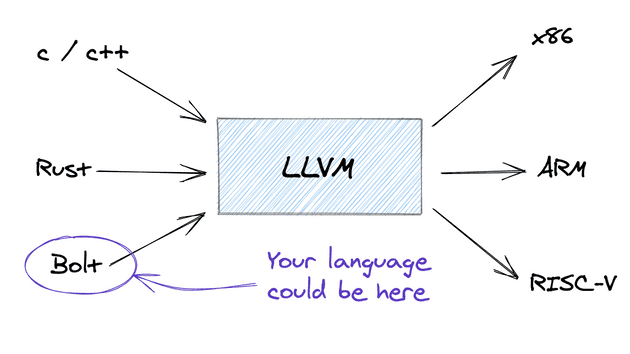
在我们取消语言功能之后,但在针对特定机器架构(x86,ARM等)的后端之前,LLVM位于编译器的中端
LLVM的IR相当低级,它不能包含某些语言中存在的语言功能,而不能包含其他语言中的语言功能(例如,类是C ++而不是C语言)。如果您之前遇到过指令集,则LLVM IR是RISC指令集。
结果是LLVM IR看起来像是一种更具可读性的汇编形式。由于LLVM IR与机器无关,因此我们无需担心寄存器的数量,数据类型的大小,调用约定或其他机器特定的细节。
因此,在LLVM IR中,我们没有固定数量的物理寄存器,而是有无限数量的虚拟寄存器(标记为%0,%1,%2,%3…我们可以读写)。这是从虚拟机映射的后端工作到物理寄存器。
而且,我们没有分配数据类型的特定大小,而是将类型保留在LLVM IR中。同样,后端将获取此类型信息并将其映射到数据类型的大小。 LLVM具有用于不同大小的int和float的类型,例如int32,int8,int1等。它还具有派生类型:如指针类型,数组类型,结构类型,函数类型。要了解更多信息,请查看“类型”文档。
现在,内置在LLVM中的是一组优化,我们可以在LLVM IR上运行例如死代码消除,函数内联,公共子表达式消除等。这些算法的细节无关紧要:LLVM为我们实现了它们。
讨价还价的一面是,我们以静态单一分配(SSA)形式编写LLVM IR,因为SSA形式使优化编写者的工作更加轻松。 SSA形式听起来很花哨,但这仅意味着我们在使用前定义变量,并且仅分配一次变量。以SSA形式,我们无法重新分配变量,例如x = x + 1;相反,我们每次都分配一个新变量(x2 = x1 + 1)。
简而言之:LLVM IR看起来像带有类型的程序集,减去了凌乱的机器特定细节。 LLVM IR必须采用SSA形式,这样更易于优化。让我们看一个例子!
请注意,.ll扩展名是用于人类可读的LLVM IR输出。还有用于比特码的.bc,这是LLVM IR的更紧凑的机器表示。
请注意,LLVM IR如何包含诸如br和icmp之类的汇编指令,但是通过一条调用指令来抽象出特定于机器的函数调用约定的混乱细节。
如果我们退后一步,可以看到IR定义了程序的控制流程图。 IR指令被分组为标记的基本块,每个块的pred标签代表该块的输入边。例如ifcont基本块则具有then和else的前身:
在这一点上,我假设您遇到了控制流图和基本块。我们在本系列的上一篇文章中介绍了控制流图,在其中我们使用它们对程序执行了不同的数据流分析。我建议您现在去检查该数据流分析帖子的CFG部分。我将在这里等待:)
phi指令表示条件分配:根据我们刚来自哪个基本块来分配不同的值。它的形式为phi类型[val1,predecessor1],[val2,predecessor2],...在上面的示例中,如果我们来自then块,则将%iftmp设置为1,如果我们已经将%mult设置为%mult来自else块。 Phi节点必须位于一个块的开头,并且每个前任节点必须包含一个条目。
再往后退,LLVM IR中的函数的总体结构如下:
LLVM模块包含与程序文件关联的所有信息。 (对于多文件程序,我们将其相应的模块链接在一起。)
我们的阶乘函数只是模块中的一个函数定义。如果我们要执行程序,例如要计算阶乘(10),我们需要定义一个主函数,该函数将成为程序执行的入口点。主要功能的签名是C的宿醉(我们返回0表示成功执行):
我们在模块目标信息中指定要为Intel Macbook Pro进行编译:
现在,我们已经了解了LLVM IR的基础知识,让我们介绍LLVM API。我们将介绍关键概念,然后在进一步探索LLVM IR时介绍更多API。
LLVM定义了很多类,它们映射到我们所讨论的概念。
这些都在名称空间llvm中。在Bolt存储库中,我选择通过将其命名为llvm :: Value,llvm :: Module等来使此命名空间明确)
大部分LLVM API都是相当机械的。现在,您已经看到了定义模块,函数和基本块的图,它们在API中对应类之间的关系很好。您可以查询Module对象以获取其Function对象的列表,并查询Function以获取其BasicBlocks的列表,反之亦然:您可以查询BasicBlock以获取其父Function对象。
值是程序计算的任何值的基类。这可能是一个函数(函数将Value子类化),基本块(BasicBlock也将Value子类化),一条指令或中间计算的结果。
每个表达式代码生成方法都返回一个值*:执行该表达式的结果。您可以将这些代码生成方法视为为该表达式生成IR,并使用Value *表示包含表达式结果的虚拟寄存器。
我们如何为这些表达式生成IR?我们创建一个唯一的Context对象,将整个代码生成捆绑在一起。我们使用此上下文来访问核心LLVM数据结构,例如LLVM模块和IRBuilder对象。
我们将使用上下文仅创建一个模块,我们将其创造性地命名为" Module"。
我们使用IRBuilder对象来逐步建立IR。从直观上讲,它等效于读取/写入文件时的文件指针-它带有隐式状态,例如就像在文件指针周围移动一样,您可以使用SetInsertPoint(BasicBlock * TheBB)方法将构建器对象设置为在特定基本块的末尾插入指令。同样,您可以使用GetInsertBlock()获取当前的基本块。
对于每个IR指令,构建器对象都有Create ___()方法。例如CreateLoad用于加载指令,CreateSub,CreateFSub分别用于整数和浮点子指令,等等。某些Create __()指令带有可选的Twine参数:用于为结果寄存器指定一个自定义名称。例如iftmp是以下指令的麻线:
我们不直接构造它们,而是从它们对应的类中获取它们。 (LLVM跟踪如何使用每种类型/常量类的唯一实例)。
例如,我们通过getSigned获取具有特定类型和值的常量有符号整数,并通过getInt32Ty获取int32类型。
函数类型相似:我们可以使用FunctionType :: get。函数类型包括返回类型,参数类型数组以及该函数是否可变参数:
首先,我们使用该名称创建类型。这会将其添加到模块的符号表中。这种类型是不透明的:我们现在可以在其他类型声明中引用,例如函数类型或其他结构类型,但是我们无法创建该类型的结构(因为我们不知道其中的内容)。
LLVM使用StringRef和ArrayRef组合字符串和数组。您可以直接传递文档需要StringRef的字符串,但是我选择在上面明确显示此StringRef。
第二步是指定结构体中的类型数组。请注意,由于我们定义了不透明的Tree类型,因此可以使用Tree类型的getPointerTo()方法获得Tree *类型。
因此,如果您的自定义结构类型在其主体中引用其他自定义结构类型,则最好的方法是声明所有不透明的自定义结构类型,然后填写每个结构的主体。
填写其功能主体(如果要链接外部功能,请跳过此步骤!)
函数原型包括函数名称,函数类型,“链接”信息以及要向其添加函数的符号表的模块。我们选择“外部链接”-这意味着该函数原型可从外部查看。这意味着我们可以链接外部函数定义(例如,如果使用库函数),或在另一个模块中公开我们的函数定义。您可以在此处查看链接选项的完整枚举。
要生成函数定义,我们只需要使用API来构造我们在阶乘示例中讨论的控制流程图:
万花筒官方教程对如何为if-else语句构造控制流程图做了很好的解释。
现在,我们已经介绍了LLVM IR和API的基础知识,我们将研究更多的LLVM IR概念,并介绍相应的API函数调用。
我们可以通过两种方式将值存储在LLVM IR中的局部变量中。我们已经看到了第一个:分配给虚拟寄存器。第二个是使用alloca指令向堆栈动态分配内存。尽管我们可以存储整数,浮点数和指向堆栈或虚拟寄存器的指针,但聚合数据类型(例如结构和数组)不适合寄存器,因此必须存储在堆栈中。
是的,你看的没错。与大多数编程语言内存模型不同,在该模型中,我们使用堆进行动态内存分配,而在LLVM中,我们只有一个堆栈。
LLVM不提供堆-它们是库功能。对于单线程应用程序,堆栈分配就足够了。在下一篇文章中(我们将扩展Bolt扩展以支持并发性),我们将讨论在多线程程序中需要全局堆的必要性。
我们已经看到了结构类型,例如{i32,i1,i32}。数组类型的格式为[num_elems x elem_type]。注意num_elems是一个常量-您需要在生成IR时(而不是在运行时)提供此常量。因此,[3 x int32]有效,但[n x int32]无效。
我们给alloca一个类型,它在堆栈上分配一个内存块并返回一个指向它的指针,该指针可以存储在寄存器中。我们可以使用该指针从堆栈中加载和存储值。
相应的构建器说明是……您猜中它是CreateAlloca,CreateLoad,CreateStore。 CreateAlloca返回值*的特殊子类:AllocaInst *:
正如我们在堆栈上分配局部变量一样,我们可以创建全局变量并从中加载并存储到它们。
全局变量在模块的开始处声明,并且是模块符号表的一部分。
我们可以使用模块对象来创建命名的全局变量,并对其进行查询。
我们在堆栈或全局内存中获得了指向聚合类型(数组/结构)的基本指针,但是如果我们想要一个指向特定元素的指针呢?我们需要在聚合中找到该元素的指针偏移量,然后将其添加到基本指针中以获取该元素的地址。计算指针偏移是特定于机器的,例如取决于数据类型的大小,结构填充等。
Get Element Pointer(GEP)指令是将指针偏移量应用于基本指针并返回结果指针的指令。
考虑从p开始的两个数组。遵循C约定,我们可以将指向该数组的指针表示为char *或int *。
下面我们显示了GEP指令来计算每个数组中的指针p + 1: 这条GEP指令有点冗长,因此,请按以下步骤进行操作: 此i64 1索引将基本类型的倍数添加到基本指针。 i8的p + 1将增加1个字节,而i32的p + 1将向p增加4个字节。 如果索引为i64 0,我们将返回p本身。 等待? 索引数组? 是的,GEP指令可以将多个索引传递给它。 我们看了一个简单的示例,其中我们只需要一个索引。 在查看传递多个索引的情况之前,我想重申一下第一个索引的目的: 类型为Foo *的指针可以在C中表示类型为Foo的数组的基本指针。 第一个索引添加此基本类型Foo的倍数来遍历此数组。 好的,现在让我们来看一下结构。 因此,采用Foo类型的结构:
我们想索引结构中的特定字段。自然的方法是将它们标记为字段0、1和2。我们可以通过将字段2作为另一个索引传递到GEP指令中来访问字段2。
然后将返回的指针计算为:ptr + 0 *(Foo的大小)+偏移量2 *(Foo的字段)。
对于结构体,您可能总是将第一个索引传递为0。与GEP的最大混淆是,由于我们想要字段2,因此该0似乎是多余的,那么为什么我们要首先传递一个0索引呢?希望您可以从第一个示例中看到为什么需要0。将其视为传递给GEP的隐式Foo数组(大小为1)的基指针。
为避免混淆,LLVM具有特殊的CreateStructGEP指令,该指令仅询问字段索引(这是为您添加0的CreateGEP指令):
我们的聚合结构嵌套得越多,我们可以提供的索引就越多。例如。对于Foo第二个字段(第4个元素int数组)的元素索引2:
返回的指针是:ptr + 0 *(Foo的大小)+偏移量1 *(Foo的字段)+偏移量2 *(数组的元素)。
(根据相应的API,我们将使用CreateGEP并传递数组{0,1,2}。)
请记住,LLVM IR必须以SSA形式编写。但是,如果我们尝试映射到LLVM IR的Bolt源程序不是SSA格式,会发生什么?
一种选择是让我们在更早的编译器阶段以SSA格式重写程序。每次我们重新分配变量时,我们都必须创建一个新变量。我们还必须为条件语句引入phi节点。对于我们的示例,这很简单,但是总的来说,这种额外的重写是我们宁愿不去处理的。
我们可以使用指针来避免分配新鲜的变量。请注意,这里我们不是在重新分配指针x,而只是更新它指向的值。因此,这是有效的SSA。
与变量重命名相比,这种切换到指针的转换要容易得多。它还有一个非常不错的LLVM IR等效项:分配堆栈内存(并操纵指向堆栈的指针),而不是从寄存器中读取。
因此,无论何时声明局部变量,我们都使用alloca获取指向刚分配的堆栈空间的指针。我们使用加载和存储指令来读取和更新指针所指向的值:
如果我们要重写Bolt程序以使用新鲜变量,那么让我们重新看一下LLVM IR。它只有2条指令,而使用堆栈则只有5条指令。此外,我们避免了昂贵的加载并存储了内存访问指令。
因此,尽管我们通过避免重写为SSA来简化我们作为编译器编写者的工作,但这是以牺牲性能为代价的。
LLVM提供了mem2reg优化,可将堆栈存储器访问优化为寄存器访问。我们只需要确保在函数的输入基本块中声明了所有局部变量的分配。
如果局部变量声明发生在函数的另一个块中,我们该怎么做?让我们看一个例子:
我们实际上可以移动alloca。只要在使用前分配堆栈空间,我们就在哪里分配堆栈空间都没有关系。因此,让我们在此局部变量声明发生的父函数的最开始处编写alloca。
我们如何在API中做到这一点?好吧,还记得生成器就像文件指针的类比吗?我们可以有多个文件指针指向文件中的不同位置。同样,我们实例化一个新的IRBuilder以指向父函数的入口基本块的开始,并使用该生成器插入alloca指令。
我正在用自己的博客来教我今年学到的主题。这是双赢的局面-您可以获得计算机科学教程,并且可以与您分享!
API使添加通行证变得非常容易。我们创建一个functionPassManager,添加所需的优化过程,然后初始化管理器。
特别是,让我们来看一下Bolt编译器之前和之后的阶乘LLVM IR输出。您可以在存储库中找到它们:
请注意,我们实际上是如何摆脱alloca和相关的加载和存储指令的,并且还删除了当时的基本块! 最后一个示例向您展示了LLVM的功能及其优化。 您可以在Bolt存储库中的main.cc文件中找到运行LLVM代码生成和优化的顶级代码。 在接下来的几篇文章中,我们将介绍一些更高级的语言功能:泛型,继承以及方法重写和并发! 敬请期待他们的出现!