我们绘制了一百万个网页,以找出导致网络缓慢的原因
我们在网络上渲染了前一百万个页面,跟踪所有可能的性能指标,记录每个错误,记录每个请求的URL。据我们所知,这将产生第一个连接性能,错误和库在网络上使用情况的数据集。在本文中,我们分析了数据可以告诉我们有关创建高性能网站的信息。
您能比我们的分析做得更好吗?我们将数据集发布到Kaggle,因此您可以自己计算数字。
如今,人们普遍的看法是,与15年前相比,网络在某种程度上更慢,更容易出错。由于JavaScript,框架,网络字体和polyfill的不断增长,我们已经吞噬了更快的计算机,网络和协议给我们带来的所有收益。大概是这样。我们想检查一下这是否真的成立,并尝试找出导致2020年网站缓慢和崩溃的常见因素。
高层计划很简单:编写Web浏览器的脚本,让其呈现前100万个域的根页面,并记录所有可能的指标:呈现时间,请求计数,重绘,JavaScript错误,使用的库等。数据,我们可以问一个因素如何与另一个因素相关的问题。哪些因素是导致渲染时间延长的最主要因素?哪些库与长时间交互相关?最常见的错误是什么,是什么引起的?
收集数据仅需编写一些代码即可使用Puppeteer编写Chrome脚本,启动200个EC2实例,在周末渲染一百万个网页,并祈祷您真正了解AWS定价的工作原理。
HTTP 2现在比HTTP 1.1更为普遍,但是HTTP 3仍然很少见。 (注意:即使使用Chrome有时会将其报告为HTTP 2 + QUIC,我们也将使用QUIC协议作为HTTP 3进行计数。)这是针对根文档的,对于链接的资源,协议编号看起来有些不同。
对于链接的资源,HTTP 3的普及率约为100倍。这怎么可能是真的?因为所有站点都链接相同的内容:
很多网站上都链接了一些脚本。这意味着我们可以期望这些资源在缓存中,对吗?从此不再如此:从Chrome 86开始,从不同域请求的资源将不会共享缓存。 Firefox计划实现相同的功能。 Safari多年来一直在像这样拆分其缓存。
给定此网页数据集及其加载时间指标,最好能了解使网页变慢的原因。我们将研究dominteractive指标,这是文档与用户互动之前所花费的时间。我们可以做的最简单的事情就是查看每个度量与dominteractive的相关性。
基本上,每个指标都与dominteractive正相关,除了0–1变量表示HTTP2或更高。这些指标中的许多指标也彼此呈正相关。我们需要一种更复杂的方法来了解导致长时间互动的各个因素。
一些指标是计时,以毫秒为单位。我们可以看一下它们的方框图,以了解浏览器在哪里花费时间。
弄清促成高交互时间的各个因素的一种方法是进行线性回归,在此我们可以根据其他指标来预测交互性。这意味着我们为每个指标分配一个权重,并将页面的交互时间建模为其他指标的加权总和,再加上一些常数。优化算法设置权重,以最小化整个数据集的预测误差。回归发现的权重大小告诉我们有关每个指标对网页运行缓慢有多大贡献。
我们将从回归中排除计时指标。如果我们花费500毫秒建立连接,那么dominteractive就会增加500毫秒,但这并不是特别有趣的见解。时间指标从根本上说是结果。我们想了解导致它们的原因。
括号中的数字是优化算法学习的回归系数。您可以将它们解释为以毫秒为单位。虽然确切的数字应该用一粒盐(请参阅下面的注释)来获取,但是有趣的是看到分配给每个特征的比例。例如,该模型预测,交付主文档所需的每个重定向都将延迟354毫秒。每当通过HTTP2或更高版本传递主HTML文档时,该模型预计互动时间将缩短477毫秒。对于文档触发的每个请求,它会预测额外的16毫秒。
在解释回归系数时,我们需要记住,我们是在简化的现实模型上进行操作。交互时间实际上不是由这些输入指标的加权总和确定的。显然,模型没有发现因果关系的机会。混淆变量显然是一个问题。例如,如果使用HTTP2加载主文档与通过HTTP2加载其他请求相关联,则该模型将把这一优势纳入main_doc_is_http2_or_greater的权重中,即使加速来自于除主文档以外的其他请求。在将模型所说的内容映射到有关现实的结论时,我们需要谨慎。
这是一个有趣的图表,显示了dominteractive按用于分发根HTML页面的HTTP协议版本进行拆分的情况。
按第一个请求的HTTP协议版本划分的dominteractive箱形图。橙色线是中位数,框从25%到75%。括号中的百分比是使用此协议发出的请求的分数。
仍然有少数网站仍通过HTTP 0.9和1.0交付。这些网站碰巧很快。似乎我们无法弄清协议变得越来越快的事实,即程序员会通过向浏览器提供更多内容来愉快地消耗这种加速。
这是用于交付根HTML页面的协议版本。如果我们看一下协议对于该文档中链接的资源的影响,该怎么办?如果我们按协议版本对请求数进行回归,则会得到以下结果。
如果我们相信这一点,我们可以得出结论,将请求的资源从HTTP 1.1移到2可以使速度提高1.8倍,而从HTTP 2移到3则可以使速度降低0.6倍。 HTTP 3是一个较慢的协议,这是真的吗?否:更可能的解释是HTTP 3很少,并且通过HTTP 3发送的少数资源(例如Google Analytics(分析))对dominteractive的影响要大于平均水平。
让我们根据传输的字节数(除以传输的数据类型来预测)来预测互动时间。
这是类似的回归,这一次是查看每种请求发起者类型的请求数量。
在这里,请求按发起请求的方式进行拆分。显然,并非所有请求都相等。由link元素触发的请求(即CSS,收藏夹图标)以及由CSS触发的请求(即字体,更多CSS)以及脚本和iframe会大大降低速度。通过XHR和提取进行请求可以预测比基线交互时间要快(可能是因为这些请求几乎总是异步的)。 CSS和脚本通常以渲染阻止方式加载,因此找到与交互时间较慢的关联并不奇怪。视频相对便宜。
我们在这里还没有发现任何新的优化技巧,但是分析确实提供了人们可以从各种优化中获得的预期影响的范围的概念。以下主张似乎有很好的经验支持:
尽可能少地提出请求。请求数比传输的千字节数重要。
对于您必须发出的请求,请尽可能通过HTTP2或更高版本进行处理。
为了弄清页面上正在使用哪些库,我们采用以下方法:在每个站点上,我们都记录了全局变量(即window对象上的属性)。之后,每个具有六千多个外观的全局变量都与一个JavaScript库相关联(如果可能)。这是一项艰苦的工作,但是由于数据集还具有每个页面所请求的URL,因此可以查看变量出现与URL请求之间的重叠,这通常足以确定哪个库将设置每个全局变量。无法与单个库可靠关联的全局变量将被忽略。这种方法在某种程度上会被低估:JS库没有义务在全局名称空间中保留任何内容。每当不同的库设置相同的属性时,它也会产生噪音,并且在标记过程中会遗漏此事实。
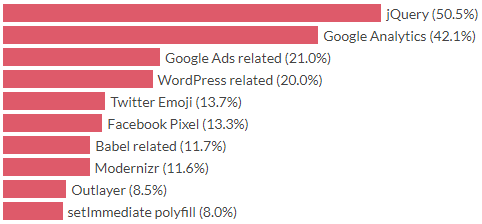
当今最常用的JavaScript库是什么?按照会议和博客文章的主题,您会被推荐React,Vue和Angular。在这个排名中,他们离排名靠前。
是的,好的旧jQuery在顶部。 JQuery于2006年首次发布,这在人类时代是14年前,但在JavaScript时代则更长。以Angular版本衡量,它可能是数百个版本之前的版本。 2006年是另一个时代。最常用的浏览器是Internet Explorer 6,最大的社交网络是MySpace,网页上的圆角是一场革命,人们称之为Web 2.0。 JQuery的主要用例是跨浏览器兼容性,这在2020年与2006年是不同的野兽。14年后的今天,示例中的整个网页都加载了jQuery。
从前十名来看,我们的浏览器主要运行分析,广告和代码以与旧的浏览器兼容。 8%的网站以某种方式为无法通过任何浏览器实现的功能定义了setImmediate / clearImmediate填充。
我们将再次进行线性回归,根据存在的库预测dominteractive。回归的输入是向量X,其中X.length ==库数,如果存在库i,则X [i] == 1.0,如果不存在,则X [i] == 0.0。当然,我们知道dominteractive实际上不是由某些库的存在与否决定的。但是,将每个库建模为对速度的累加贡献,并回归数十万个示例,仍然给我们带来有趣的发现。
此处的负系数表示,与没有库时相比,该模型预测的交互时间要短。当然,这并不意味着添加这些库可以使您的网站更快,它仅意味着具有这些库的网站碰巧比模型所建立的某些基准要快。这里的结果可能既具有社会学意义,又具有技术意义。例如,用于延迟加载的库预计交互时间很短。这可能是同样多的,因为带有这些库的页面是由程序员制作的,他们花费时间优化快速页面加载,这是由延迟加载直接导致的。我们无法通过此设置来解决这些因素。
我们可以重复上面的练习,但是这次是预测加载时间。 Onloadtime是触发窗口的“加载”事件所花费的时间,也就是加载页面上所有资源所花费的时间。我们以与以前相同的方式进行线性回归。
互联网评论家喜欢说关联不等于因果关系,实际上我们无法直接利用这些模型来了解因果关系。解释系数时应格外小心,尤其是因为可能涉及许多混淆因素。但是,肯定有足够的东西可以使您变得“嗯”。该模型将982ms的交互式交互时间与jQuery的存在关联起来的时间缩短了,并且有一半的站点加载了此脚本,这一事实应引起我们的关注。如果您要优化自己的网站,请在此处将其依赖项列表与等级和系数进行交叉引用,这样可以很好地指示出哪些依赖项删除可以最大程度地发挥您的优势。
您可能还对我们深入研究爬网中发现的错误感兴趣。请参阅我们关于The JavaScript Errors In The Wild的文章,其中我们分析发现的错误,并讨论它们可以告诉我们有关网络技术如何发展以创造一个不太容易出错的未来的信息。