张量处理单元
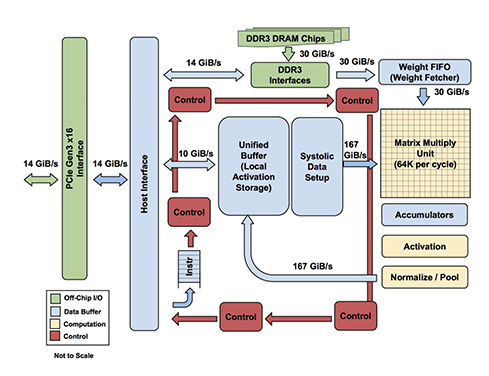
张量处理单元(TPU)(有时称为TensorFlow处理单元)是用于机器学习的专用加速器。它是Google设计的处理IC,用于使用TensorFlow处理神经网络处理。 TPU是ASIC(专用集成电路),用于通过网络上的处理元件(带有本地存储器的小型DSP)来加速特定的机器学习工作负载,以便这些元件可以相互通信并传递数据。
TensorFlow是一个用于机器学习的开源平台,可用于图像分类,对象检测,语言建模,语音识别等。
TPU具有优化模型的库,使用片上高带宽存储器(HBM),并且每个内核中都有标量,矢量和矩阵单元(MXU)。 MXU在每个周期以16K乘法累加运算进行处理。通过Bfloat16简化了32位浮点输入和输出。内核分别执行用户计算(XLA ops)。 Google可以访问其服务器上的Cloud TPU。
否则,CPU和GPU更适合于快速原型设计,简单的模型,中小型批处理大小,无法更改的预先存在的代码,一些数学问题等。 *有关更多信息,请参见云张量处理单元(TPU)。
在2013年,对于Google显而易见的是,除非他们能够设计能够处理机器学习推理的芯片,否则他们将不得不将其拥有的数据中心数量增加一倍。谷歌表示,最终的TPU的性能比目前的CPU和GPU高15-30倍,每瓦性能高30-80倍。”
导致这种现象的基本趋势是专业化与通用化。将Nvidia的GPU用于ML应用程序的效率大约为84%。您浪费了那部分的84%。如果您要在Google上部署数以百万计的图形处理器,那么您就有很大的动力去构建TPU,而不是从Nvidia购买GPU。全面都是如此。” eSilicon的杰克·哈丁(Jack Harding)说。
最新的Google TPU包含65,536个8位MAC块,消耗的功率如此之大,以至于该芯片必须进行水冷。 TPU的功耗可能在200W至300W之间。
Pod是链接在一起的多个设备。 有关更多信息,请参见Google的TPU页面。