无锁编程简介
无锁编程是一个挑战,这不仅是因为任务本身很复杂,而且还因为一开始很难穿透该主题。
幸运的是,我对无锁(也称为无锁)编程的第一个介绍是Bruce Dawson出色而全面的白皮书《无锁编程注意事项》。和许多人一样,我曾有机会将布鲁斯的建议付诸实践,以便在Xbox 360等平台上开发和调试无锁代码。
从那时起,已经写了很多好的材料,从抽象理论和正确性证明到实际示例和硬件细节。我将在脚注中留下参考文献列表。有时,一个来源中的信息可能看起来与其他来源正交:例如,某些材料假定了顺序一致性,因此回避了通常困扰无锁C / C ++代码的内存排序问题。新的C ++ 11原子库标准又使工作陷入困境,挑战了我们许多人表达无锁算法的方式。
在本文中,我想重新引入无锁编程,首先是对其进行定义,然后将大部分信息精简为几个关键概念。我将使用流程图说明这些概念之间的关系,然后我们将脚趾深入细节。至少,任何从事无锁编程的程序员都应该已经了解如何使用互斥锁以及信号和事件等其他高级同步对象编写正确的多线程代码。
人们通常将无锁编程描述为没有互斥锁的编程,也称为锁。没错,但这只是故事的一部分。根据学术文献,公认的定义要宽泛一些。从本质上讲,无锁是用于描述某些代码的属性,而无需过多地讲述该代码的实际编写方式。
基本上,如果程序的某些部分满足以下条件,则可以合理地认为该部分是无锁的。相反,如果代码的给定部分不满足这些条件,则该部分不是无锁的。
从这种意义上讲,无锁的锁定并不直接指互斥,而是指以某种方式“锁定”整个应用程序的可能性,无论是死锁,活动锁,甚至是由假设的线程调度决定造成的。你最大的敌人最后一点听起来很有趣,但这很关键。共享互斥量很少被排除,因为一旦一个线程获得了互斥量,您最大的敌人就根本再也不会调度该线程了。当然,真正的操作系统不能那样工作-我们只是在定义术语。
这是一个简单的操作示例,其中不包含互斥锁,但仍然不是无锁的。最初,X =0。作为读者的练习,请考虑如何调度两个线程,以使两个线程都不退出循环。
没有人期望大型应用程序完全没有锁。通常,我们从整个代码库中识别出一组特定的无锁操作。例如,在无锁队列中,可能会有少量的无锁操作,例如推,弹出,也许为isEmpty等。
赫利希& Shavit是《多处理器编程艺术》的作者,倾向于将此类操作表示为类方法,并提供了以下简洁的无锁定义(请参见幻灯片150):“在无限执行中,无数次通常会完成一些方法调用。”换句话说,只要程序能够继续调用那些无锁操作,无论如何,已完成的调用数量都会不断增加。从算法上讲,系统在这些操作期间无法锁定。
无锁编程的一个重要结果是,如果挂起单个线程,它将永远不会阻止其他线程作为一个整体通过它们自己的无锁操作取得进展。这在编写中断处理程序和实时系统时暗示了无锁编程的价值,其中无论程序其余部分处于什么状态,某些任务都必须在一定时间内完成。
最后的精度:设计为阻止的操作不会使算法失去资格。例如,当队列为空时,队列的弹出操作可能会故意阻塞。其余代码路径仍然可以认为是无锁的。
事实证明,当您尝试满足无锁编程的非阻塞条件时,就会出现一整套技术:原子操作,内存障碍,避免ABA问题,仅举几例。在这里,事物迅速变得令人着迷。
那么这些技术如何相互联系?为了说明,我整理了以下流程图。我将在下面详细说明。
原子操作是一种以似乎不可分割的方式操作内存的操作:没有线程可以观察到该操作是半完成的。在现代处理器上,许多操作已经是原子的。例如,简单类型的对齐读取和写入通常是原子的。
读-修改-写(RMW)操作更进一步,使您能够自动执行更复杂的事务。当无锁算法必须支持多个编写器时,它们特别有用,因为当多个线程在同一地址上尝试RMW时,它们将有效地连续排成一行并一次执行这些操作。我已经在此博客中介绍了RMW操作,例如在实现轻量级互斥锁,递归互斥量和轻量级日志记录系统时。
RMW操作的示例包括Win32上的_InterlockedIncrement,iOS上的OSAtomicAdd32以及C ++ 11中的std :: atomic :: fetch_add。请注意,C ++ 11原子标准不能保证该实现在每个平台上都是无锁的,因此最好了解您的平台和工具链的功能。您可以调用std :: atomic<> :: is_lock_free来确保。
不同的CPU系列以不同的方式支持RMW。诸如PowerPC和ARM之类的处理器公开了加载链接/存储条件指令,这些指令可以有效地使您在较低的级别上实现自己的RMW原语,尽管这种做法并不经常执行。普通的RMW操作通常就足够了。
如该流程图所示,即使在单处理器系统上,原子RMW也是无锁编程的必要部分。如果没有原子性,线程可能会在事务进行到一半时被中断,从而可能导致状态不一致。
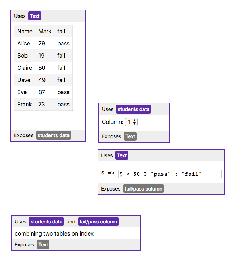
也许最经常讨论的RMW操作是比较交换(CAS)。在Win32上,通过诸如_InterlockedCompareExchange之类的内部函数家族提供CAS。通常,程序员在循环中执行比较和交换操作以重复尝试事务。这种模式通常涉及将共享变量复制到局部变量,执行一些推测性工作,并尝试使用CAS发布更改:
void LockFreeQueue :: push(Node * newHead) { 为(;;) { //将共享变量(m_Head)复制到本地。 节点* oldHead = m_Head; //做一些推测性的工作,其他线程还看不到。 newHead-> next = oldHead; //接下来,尝试将我们的更改发布到共享变量。 //如果共享变量未更改,则CAS成功并返回。 //否则,请重复。 如果(_InterlockedCompareExchange(&m_Head,newHead,oldHead)== oldHead) 返回; } }
这样的循环仍然可以认为是无锁的,因为如果一个线程的测试失败,则意味着它必须在另一个线程上成功-尽管某些体系结构提供了较弱的CAS变体,但不一定如此。每当实现CAS循环时,都必须特别注意避免ABA问题。
顺序一致性意味着所有线程都同意发生内存操作的顺序,并且该顺序与程序源代码中的操作顺序一致。在顺序一致性下,不可能像我在上一篇文章中演示的那样经历内存重新排序的恶作剧。
一种实现顺序一致性的简单(但显然不切实际)的方法是禁用编译器优化,并强制所有线程在单个处理器上运行。即使线程在任意时间被抢占和调度,处理器也永远不会看到自己的内存影响。
某些编程语言甚至可以为在多处理器环境中运行的优化代码提供顺序一致性。在C ++ 11中,可以将所有共享变量声明为具有默认内存排序约束的C ++ 11原子类型。在Java中,可以将所有共享变量标记为volatile。这是我上一篇文章的示例,该示例以C ++ 11样式重写:
std :: atomic< int> X(0),Y(0); int r1,r2; 无效thread1() { X.store(1); r1 = Y.load(); } 无效thread2() { Y.store(1); r2 = X.load(); }
因为C ++ 11原子类型保证顺序一致性,所以结果r1 = r2 = 0是不可能的。为此,编译器会在后台输出其他指令-通常是内存围栏和/或RMW操作。与程序员直接处理内存排序的指令相比,那些额外的指令可能会使实现效率降低。
如流程图所示,每当您对多核(或任何对称多处理器)进行无锁编程,并且您的环境不能保证顺序一致性时,您必须考虑如何防止内存重新排序。
在当今的体系结构上,用于执行正确的内存排序的工具通常分为三类,这既阻止了编译器的重新排序,也阻止了处理器的重新排序:
轻量级同步或防护说明,我将在以后的文章中讨论;
获取语义可防止按照程序顺序对其后面的操作进行内存重新排序,而释放语义则可防止对其之前的操作进行内存重新排序。这些语义特别适用于存在生产者/消费者关系的情况,其中一个线程发布一些信息,而另一个线程读取它。在以后的文章中,我还将对此进行更多讨论。
在内存重新排序方面,不同的CPU系列具有不同的习惯。每个CPU供应商都记录了这些规则,并严格遵循了硬件。例如,PowerPC和ARM处理器可以相对于指令本身更改内存存储的顺序,但是通常,英特尔和AMD的x86 / 64系列处理器不会。我们说以前的处理器具有更宽松的内存模型。
倾向于抽象出这些特定于平台的细节,尤其是C ++ 11为我们提供了编写可移植的无锁代码的标准方法。但是目前,我认为大多数无锁程序员至少对平台差异有所了解。如果需要记住一个关键的区别,那就是在x86 / 64指令级别上,每次从内存中加载都会获取语义,并且每次存储到内存都将提供释放语义–至少对于非SSE指令和非写组合内存。因此,过去通常会编写可在x86 / 64上运行但在其他处理器上无法运行的无锁代码。
如果您对处理器如何以及为什么执行内存重新排序的硬件详细信息感兴趣,我建议您阅读《并行编程难》的附录C。无论如何,请记住,由于编译器对指令的重新排序也可能导致内存重新排序。
在这篇文章中,我没有对无锁编程的实际方面说太多,例如:什么时候做?我们真正需要多少?我也没有提到验证无锁算法的重要性。尽管如此,我希望对某些读者来说,本入门对无锁概念有基本的了解,因此您可以继续阅读更多内容而不会感到困惑。与往常一样,如果您发现任何不正确之处,请在评论中告诉我。