了解各个单元在深度神经网络中的作用
由加利福尼亚州斯坦福市斯坦福大学的David L.Donoho编辑,并于2020年7月7日批准(已于2019年8月31日接受审查)
深度神经网络擅长寻找解决大型数据集上复杂任务的分层表示形式。我们人类如何理解这些学习的表征?在这项工作中,我们介绍了网络解剖,这是一个分析框架,可以系统地识别图像分类和图像生成网络中各个隐藏单元的语义。首先,我们分析经过场景分类训练的卷积神经网络(CNN),并发现与各种对象概念相匹配的单元。我们发现证据表明网络已经学习了许多对象类,这些对象类在分类场景类中起着至关重要的作用。其次,我们使用类似的分析方法来分析训练为生成场景的生成对抗网络(GAN)模型。通过分析激活或停用少量单元时所做的更改,我们发现可以在适应上下文的同时从输出场景中添加和删除对象。最后,我们将分析框架应用于理解对抗攻击和语义图像编辑。
深度网络的各个隐藏单元是否可以教我们网络如何解决复杂的任务?有趣的是,在最先进的深层网络中,已经观察到许多单个单元与未明确教授给网络的人类可理解的概念相匹配:已经发现单元可以检测物体,零件,纹理,时态,性别,语境和情感(1到7)。找到这样有意义的抽象是深度学习的主要目标之一(8),但是对于这样的概念特定单元的出现和作用还没有很好的理解。因此,我们问:如何量化整个网络层中概念单元的出现?哪些类型的概念是匹配的,它们起什么作用?当网络包含一个在树上激活的单元时,我们希望了解它是否是虚假的相关性,或者该单元是否具有因果作用,从而揭示了网络如何建模其关于树的高级概念。
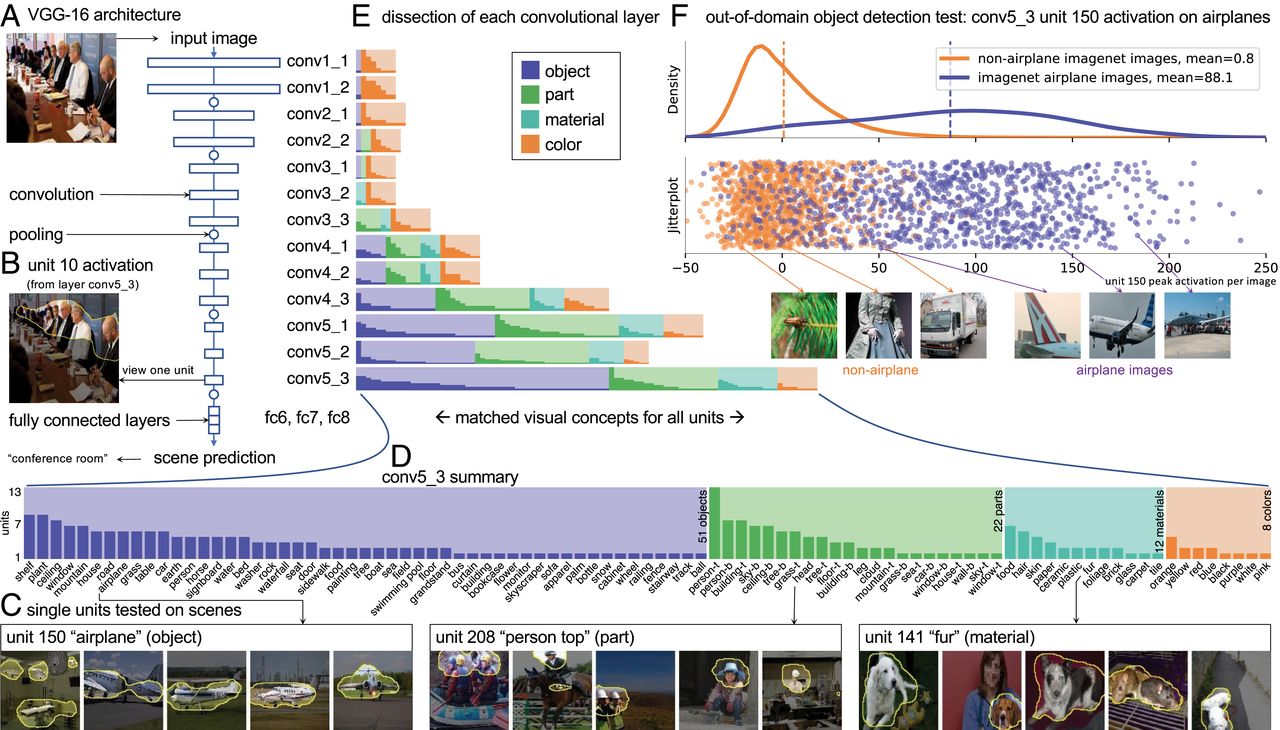
为了研究这些问题,我们介绍了网络解剖(9,10),这是我们系统地映射在深度卷积神经网络(CNN)中发现的语义概念的方法。这种网络中计算的基本单位是学习的卷积滤波器。该体系结构是解决计算机视觉中各种区分性和生成性任务的最新技术(11层到19层)。通过将每个单元的活动与一系列人类可解释的模式匹配任务(例如对象类别的检测)进行比较,网络解剖可以识别,可视化和量化网络中各个单元的作用。
以前了解深度网络的方法包括使用显着性图(20 – 27):这些方法询问网络在做出决策时所处的位置。我们当前查询的目标是不同的:我们询问网络在寻找什么以及为什么。另一种方法是创建简化的代理模型以模仿和总结复杂网络的行为(28到30),另一种技术是训练解释网络以生成易于理解的网络解释(31)。与那些方法相反,网络解剖的目的是直接解释网络本身的内部计算,而不是训练辅助模型。
我们剖析了接受两种不同类型任务训练的网络单元:图像分类和图像生成。在这两种设置中,我们都发现训练有素的网络包含与未在训练数据中明确标记的高级视觉概念相对应的单元。例如,在接受训练以分类或生成自然场景图像时,这两种类型的网络都会学习与“树”的视觉概念相匹配的单个单元,即使我们从未在训练过程中向网络传授树概念。
将我们的分析重点放在网络的单元上,可以通过在处理过程中激活和停用单元来测试网络行为的因果结构。在分类器中,我们使用这些干预来询问是否可以通过识别场景类中视觉概念的少量单元来解释特定类的分类性能。例如,我们询问在删除一些可以检测到雪,山脉,树木和房屋的单位时,如何影响网络将图像分类为滑雪胜地的能力。在场景生成网络中,我们询问场景中对象的渲染如何受到特定于对象的单元的影响。移除树单元会如何影响输出图像中树和其他对象的外观?
Warning: Can only detect less than 5000 characters
通过确定每个班级最重要的单元,可以揭示网络学习到的对象和场景之间的关系。例如,图2 A中显示了“滑雪胜地”类别中四个最重要的conv5_3单元:这些单元在移除时对滑雪胜地准确性的损害最大。这些单位可以检测到雪,山,房屋和树木,所有这些似乎对滑雪胜地的场面都很重要。
为了测试网络对滑雪胜地进行分类的能力是否可以仅归因于最重要的单位,我们删除了选定的单位集。图2 B显示,仅删除这4个(共512个)单元会使网络在区分滑雪胜地场景时的准确性从81.4%降低到64.0%,而删除conv5_3中的20个最重要的单元将类的准确性进一步降低到53.5%,接近机会水平(机会为50%),即使几乎不影响所有场景类的分类准确性(从53.3变为52.6%,机会为0.27%)。相反,删除492个最不重要的单位(在conv5_3中仅保留20个最重要的单位)对特定类别的准确性影响很小,滑雪胜地的准确性仅降低3.7%(降至77.7%)。当然,删除这么多的单元会损害网络对其他场景类别进行分类的能力:删除492个最不重要的单元会将所有级别的准确性降低到2.1%(机会为0.27%)。
图2 C显示了删除不同数量的最重要和最不重要的单位对滑雪胜地准确性的影响。为避免过度拟合评估数据,我们根据单位对单班的个人影响来对单位的重要性进行排名训练集上的滑雪胜地准确性,以及在保留的验证集上评估删除单元集所绘制的影响。可以看出,该网络可以从最重要的单位获得大部分的滑雪胜地分类性能。甚至可以通过删除最不重要的单位来提高单班精度。在SI附录中将进一步探讨这种效果。
在所有类别中都可以看到这种内部组织,其中网络相对于单个输出类别而言,其准确性大部分依赖于少量重要单元。图2D对365个场景类别的每个重复相同的实验。删除每个班级最重要的20个conv5_3单元,将单班精度平均降低到53.0%,接近机会水平。相比之下,删除492个最不重要的单位只会使单类准确性平均降低3.6%,只是略有降低。我们得出的结论是,由conv5_3单元完成的紧急目标检测不是虚假的:每个单元对于一组特定的类都很重要,并且对象检测器可以解释为将网络中各个场景类的分类分解为更简单的子问题。
为什么有些单位与可解释的概念匹配得那么好,而另一些单位却没有?图2E中的数据表明,最可解释的单位是对许多不同的输出类别很重要的单位。对于仅一类(或无一类)重要的单位,由IoU衡量的解释性较差。我们进一步发现,重要的单元主要与其关联的类别成正相关,并且不同的单元组合为每个类别提供了支持。 SI附录中详细介绍了单位类别相关性的度量以及重要单位的重叠组合示例。
诸如飞机,雪和树木探测器之类的可解释单位的出现是否取决于将视觉世界分为数百种场景类别的训练集标签?场景的分类法可能编码了了解对象所必需的区别。还是网络可以从视觉数据本身推断出这样的概念?为了调查这个问题,我们接下来在经过训练以解决无人监督任务的网络上进行类似的实验。
生成对抗网络(GAN)学习合成随机逼真的图像,该图像模仿训练集中真实图像的分布(14)。从结构上讲,训练有素的GAN生成器是分类器的反面,可从随机输入的潜矢量产生逼真的图像。与分类不同,它是无人监督的设置:GAN没有提供人工注释,因此网络必须自己学习图像的结构。
值得注意的是,已经观察到GAN可以学习图像的全局语义:例如,在潜矢量之间进行插值可以平滑地改变房间的布局(40)或更改对象的纹理(41)。我们希望了解GAN是否还学会分解本地语义,例如,如果内部单元将场景的生成表示为有意义部分的层次结构,则该知识是否会得到学习。
我们测试了经过训练以模仿LSUN厨房图像的累进GAN架构(19)(42)。该网络体系结构由15个卷积层组成,如图3 A所示。给定从多元高斯分布中采样的512维向量,该网络在处理了15个层的数据后,会生成256×256的逼真图像。与分类器网络一样,每个单元通过显示过滤器在其最高1%位数水平以上激活的区域来可视化,如图3 B所示。重要的是,发生器中的因果关系与分类器的流动方向相反:单元381在图像中的灯罩上激活,因为在生成图像之前发生滤光器激活,所以未检测到图像中的物体。相反,该单位是最终渲染对象的计算的一部分。
为了确定与对象类相关联的网络单元的位置,我们将网络解剖应用于网络每一层的单元。在此实验中,使用的参考细分模型和阈值与用于分析VGG-16分类器的参考细分模型和阈值相同。但是,我们不分析与输入数据中出现的对象的一致性,而是分析与在生成的输出图像中找到的分段对象的一致性。如图3 C所示,出现的最大概念单元未出现在网络边缘,如我们在分类器中看到的,而是出现在中间:第5层具有与最大数量的不同对象和零件类匹配的单元。
图3D示出了与层5中的单位相匹配且IoU> 2的每个物体,零件,材料和颜色。 4%。该层包含19个特定于对象的单元,41个与对象部分匹配的单元,一种材料和六个颜色单元。从分类网络中可以看出,“烤箱”和“椅子”等视觉概念与许多单位相匹配。与分类器不同,匹配的对象部分多于整个对象。
在图3 D中,单个单元显示了广泛的视觉多样性:这些单元似乎并不严格匹配特定的像素图案,而是特定类别的外观不同:例如,各种样式的烤箱或不同的颜色和形状厨房凳子。
在图3F中,我们将窗口特定单元314用作图像分类器。我们发现,当生成大窗口时和不生成大窗口时,单元的激活之间存在很大的差距。此外,简单的阈值(峰值激活> 8.03)可以在预测所生成的图像是否具有大窗口时达到78.2%的精度。然而,分布密度曲线揭示了在不激活单元314的情况下经常可以生成包含大窗口的图像。图3G中示出了两个这样的样本。这些示例表明其他单元可以潜在地合成窗口。
单元与生成的对象类之间的关联是暗示性的,但是它们不能证明与对象类关联的单元实际上使生成器呈现对象类的实例。为了了解单元在GAN生成器中的因果作用,我们在直接删除或激活单元组时测试生成器的输出。
我们首先从在LSUN教堂场景(42)上训练的Progressive GAN(19)中依次删除较大的树单元集。我们根据IoU u树对第4层中的单元进行排名,以识别最特定于树的单元。当从网络中依次删除这些树单元的较大集合时,GAN会生成带有越来越少的树的图像(图4A)。移除10,000个随机生成的图像后,删除20个最特定于树的单位可将生成的输出中的树像素数减少53.3%。
删除特定于树的单位后,生成的图像将继续看起来类似真实。尽管生成的树越来越少,但其他对象(例如建筑物)未发生变化。值得注意的是,建筑物被树木遮挡的部分是幻觉化的,好像去掉树木就能看到它们后面的墙壁和窗户(图4 B)。生成器似乎已经计算出了比渲染最终输出所需更多的细节。隐藏在树后的建筑物细节只能通过抑制树的生成来揭示。这些隐藏细节的出现强烈表明GAN正在学习场景的结构化统计模型,该模型超出了可见像素图案的平面汇总范围。
......