如何在AWS上以更高的性能和更低的成本运行数据库

亚马逊网络服务(AWS)是最受欢迎的公共云服务提供商之一。在AWS上运行数据库是使用其云服务的重要部分。但是,我们如何才能最好地利用云资源并以最佳性能运行数据库?
这篇文章演示了我们在PingCAP上如何部署和优化TiDB以在AWS Cloud上进行生产。我们希望这里提供的建议还可以帮助您配置最适合您自己的工作负载的TiDB服务。
为了评估不同配置的性能,我们运行了TPC-C和Yahoo!。在典型的三节点群集上进行云服务基准(YCSB)测试。 TPC-C是通用基准标准,可模拟密集的在线交易工作量,而YCSB涵盖最常见的云应用方案。本文详细讨论了结果。
当在TiDB之类的持久数据库之上构建应用程序时,该数据库最终会将用户交互转换为磁盘存储上的读取和写入。因此,本文着重介绍如何更好地利用AWS云存储作为TiDB的新存储介质。
在本文中,我们考虑将AWS Elastic Block Storage(EBS)用作TiDB服务的主要存储。与传统的本地磁盘不同,EBS是:
有弹性。存储层与弹性计算云(EC2)实例解耦,因此可以弹性应对主机故障,并且易于扩展。
云友好。 EBS与AWS云生态系统自然集成;例如,通过S3快照进行备份和还原很容易。
尽管EBS的年故障率(AFR)比商品硬件要小,但对于关键业务应用程序仍然不够可靠。它们要求跨区域可用性,只有在多个可用性区域(AZ)中复制的分布式数据库才有可能。在这方面,TiDB非常适合EBS。
EBS卷由其性能限制定义,包括最大和持续的每秒输入/输出操作(IOPS)和吞吐量。在某些情况下,EBS卷可以在短期内“爆发”以达到更高的性能。为了使我们的产品具有可预测的性能,我们的帖子主要关注可持续的EBS性能。
IOPS限制就像硬顶一样。低于限制,就IOPS更改而言,I / O延迟相对稳定。一旦IOPS达到限制,延迟就会受到严重的惩罚,通常会超过10毫秒。
与IOPS相比,吞吐量限制要软得多。这意味着即使低于该限制,I / O延迟也会与I / O吞吐量成比例地增长。
EBS通过网络接口连接到EC2实例。因此,对于给定的EC2 / EBS对,实际的磁盘性能不仅取决于EBS规范,还取决于EC2专用于云存储的带宽的能力。下表总结了几种实例类型的性能:
1:根据AWS官方文档,低功率机器至少每24小时只能达到30分钟的最高性能。
Amazon EBS优化的实例文档包括有关EC2-to-EBS限制的详细规范。通常,EC2的能力与其计算能力成正比。但是,较大的机器(例如具有32个内核的m5.8xlarge)倾向于每个内核具有更少的资源。
下图展示了EC2带宽限制如何直接影响服务性能。使用不同类型的实例作为节点服务器对两个集群进行交叉比较;即m5.2xlarge和m5.4xlarge。每个群集节点都配备了1 TB的AWS预置IOPS,容量为6,000 IOPS。从理论上讲,该磁盘的最大吞吐量为256 KiB I / O时为1,500 MiB / s,但实际性能受EC2带宽的严格限制。切换EC2实例后,在CPU使用率几乎相同的情况下,性能提高了一倍。
对于AWS通用SSD,IOPS性能以每GB 3 IOPS的比例线性扩展至卷大小,直到达到1 TB的3,000 IOPS上限为止。这意味着大于1 TB的gp2体积不是经济上最佳的选择。理论上,gp2的带宽限制始终为250 MiB / s。但是,由于EBS在内部将用户请求分为256 KiB块,因此只有大于334 GB的卷才具有足够的IOPS配额来交付该数量的吞吐量。
值得注意的是,gp2是基于信用的可爆实例之一。根据您拥有的积分数,gb2可能会在短期内从基准达到最高性能。对于具有仅在有限时间内要求高性能的高度动态工作负载配置文件的用户而言,此功能可能很诱人。但是对于我们的目标用户群,我们建议将gp2的卷大小设置为大于1 TB,以避免由于突发而导致不可预测的性能。
与gp2相比,预配置的IOPS SSD进一步提高了最大吞吐量和IOPS容量。您最多可以配置IOPS 64,000,吞吐量最多可以配置1,000 MiB / s。除了高性能之外,新一代io2还提供了99.999%的耐用性。
为了获得基准性能,我们建议将io1 / io2卷配置为每TB 6,000 IOPS。借助云存储的弹性,您可以动态修改EBS卷性能。这意味着您可以根据应用程序对存储层的压力,以不同的方式向上或向下扩展各个节点的存储性能。您可以使用我们的Grafana面板或AWS的CloudWatch监视正在运行的实例的I / O负载。
通常,预配置的IOPS SSD卷非常适合需要云上最佳存储性能的大规模数据密集型应用程序。为了最大程度地利用此存储功能,考虑使用此选项的用户在选择大小合适的EC2实例时应格外小心。
一个EBS卷的性能有限,但是您可以将多个卷作为RAID-0阵列条带化以增加存储能力。根据我们的基准,具有两个1 TB gp2卷的RAID 0阵列的性能可与配备6 K IOPS的io1相媲美,但成本仅为40%。
但是,RAID-0配置缺少数据冗余。因此,RAID阵列的服务保证要弱于单个卷的服务保证。例如,剥离两个gp2体积的99.8%的耐久性,将产生一系列99.6%的耐久性。
同样,调整RAID-0阵列的大小会导致服务停机。因此,对于采用磁盘条带化的用户,建议您在部署每个存储节点之前先计划它们的卷大小。
到目前为止,我们已经讨论了AWS云上存储性能的关键要素。应用程序的工作负载决定了实际的性能要求。更具体地说,诸如批量插入或表扫描之类的查询给存储带宽带来了巨大压力,而事务处理或随机读取则更多地依赖于存储IOPS资源。
下表列出了我们认为对于大多数常见工作负载而言具有成本效益的存储节点配置。将这些配置视为一般建议或构建块,可以在其上创建自己的自定义配置。除了此列表之外,用户还可以根据此处提出的原理从AWS提供的各种选项中进行选择。
对于需要更高服务质量的应用程序,我们提供了几种可以以最低成本进一步提高基准性能的技术。但是,这些策略需要额外的维护,因此仅建议专业用户使用。
从逻辑上讲,TiKV将Raft日志与键值数据分开存储。由于数据库仅维护最新事务的Raft日志,因此Raft组件的吞吐量使用率较低。与使用键值数据共享磁盘相比,使用单独的Raft卷可以减少关键路径上的写入延迟。因此,我们建议为延迟敏感的应用程序部署一个单独的EBS磁盘作为Raft卷。
您可以在TiKV配置文件中指定单独的Raft卷的路径:
[] ## RaftDB目录的路径。 ##如果未设置,则为`{data-dir} / raft`。 ##如果计算机上有多个磁盘,请将Raft RocksDB的数据存储在不同的磁盘上##可以提高TiKV性能。 #raftdb-path =“ / path / to / raft”
为了保证数据的持久性,Raftstore经常发出同步写入。因此,木筏卷的最高优先级是磁盘IOPS和fsync频率。几种类型的EBS可以满足这些需求。为了获得最佳的系统稳定性,我们建议使用体积较小的预配置IOPS SSD。例如,配备2 K IOPS的40 GB io1。对于可以容忍某种程度的性能波动的应用程序,应该选择价格更便宜的通用型SSD,并且其更大的尺寸可以接受可接受的基准IOPS。例如,一个350 GB gp2,容量为1050 IOPS。
几种EC2类型已附加一个或多个本地实例存储。这些SSD驱动器与您创建的实例在物理上位于同一位置,因此,其性能比云存储好得多。但是,实例终止后,实例存储中的内容将无法保留或传输。这些限制使实例存储容易受到主机故障或更新的影响,并且不适合存储关键的应用程序数据。下表比较了在m5d.2xlarge上用fio测试的网络磁盘和本地实例存储:
但是,作为快速层设备,实例存储可以用作缓存来减轻来自云磁盘的读取压力。由于RocksDB(TiKV的存储引擎)通过访问新近度对磁盘数据进行分组,因此使用最近最少使用(LRU)策略的缓存自然会受益于数据文件的组织方式。
为了证明SSD缓存的重要性,我们使用EnhanceIO(SSD缓存的开源解决方案)来优化由读取IOPS限制的几种工作负载。
SSD缓存不会给数据完整性带来额外的风险,因为我们仅将本地磁盘用作只读缓存。此外,包括EnhanceIO在内的多种SSD缓存解决方案均支持热插拔,因此您可以在服务保持运行时动态配置缓存策略。
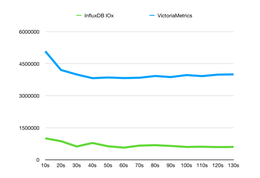
如前所述,EBS的访问延迟对I / O吞吐量很敏感。对于像TiKV这样的依靠后台压缩来提供持续服务的系统,这对性能稳定性构成了极大的威胁。下图显示,读/写流的增加导致每秒写操作的减少:
为了将后台I / O流量保持在稳定水平,建议您将rate-bytes / sec__设置为适中的较低值。在TiKV 4.0.8及更高版本中,您可以动态更改I / O速率限制,并且DBA可以随着工作负载的发展来优化此参数。两种方法都在下面列出。
[] ##限制压缩和刷新的磁盘IO。 ##如果压实和冲洗超过一定阈值,则可能导致严重的峰值。考虑将##设置为磁盘吞吐量的50%〜80%,以获得更稳定的结果。但是,在繁重的##写工作负荷中,限制压缩和刷新速度也会导致写停顿。 ## 1. rate-bytes-per-sec是您大多数时候要设置的唯一参数。它控制压缩和刷新的##总写入率,以每秒字节数为单位。目前,除了刷新和压缩外,RocksDB不会##强制执行速率限制,例如写入WAL。 rate-bytes / sec =“ 100MB”
然而,持续的手动干预是不方便的。我们的最终目标是建立一个更加自治的“自动驾驶”数据库。作为朝这个方向迈出的一步,我们最近推出了一种新的自动调整算法,该算法可根据用户工作负载自动配置速率限制,该功能将在下一个主要版本中提供。
现在,根据工作量和预算,您应该确定特定的群集配置。本节介绍一些内部调整技巧,可以更好地根据您的需求自定义数据库服务。
在TiKV下,我们使用RocksDB作为存储引擎。它使用块高速缓存以未压缩的格式存储最近的读取。配置块高速缓存大小实际上可以调整存储在内存中的未压缩内容和压缩内容(系统页面)的比例。
从块缓存读取比从页面缓存读取更快,但是分配大块缓存并不总是理想的。如果设置相对较小的块高速缓存,则内存可以容纳更多的块,因为它们被紧凑地存储在系统页面高速缓存中,从而避免了对这些块的读取而影响磁盘存储。
当应用程序的工作负载非常繁重且读取集无法放入块缓存中时(例如,数据集太大或读取模式太稀疏),很可能许多读取请求将落入持久性层。用户通常会体验到读取和更新延迟的增加,并且会注意到存储监视器上的读取I / O压力很高。在这种情况下,建议调低块缓存大小。在5 K仓库TPC-C基准测试中,为了避免读取IOPS达到EBS限制,我们在具有32 GB内存的EC2实例中为块缓存保留4 GB。
[] ##共享块缓存的大小。通常应将其调整为系统总内存的30%-50%。 ##如果未设置配置,则由以下字段的总和或其默认##值决定:## * rocksdb.defaultcf.block-cache-size或系统总内存的25%## * rocksdb。 writecf.block-cache-size或系统总内存的15%## * rocksdb.lockcf.block-cache-size或系统总内存的2%## * raftdb.defaultcf.block-cache-size或系统总内存的2%总内存## ##要在单个物理机上部署多个TiKV节点,请显式配置此参数。 ##否则,TiKV中可能会发生OOM问题。 #容量=“ 4GB”
在RocksDB中,先通过检索键值对所在的物理块将其读取到内存中。在这种情况下,每个逻辑读取的物理I / O大小(也称为读取放大)至少为一个大小。物理块。减小块大小可减少点获取中涉及的不必要读取。不利之处是具有空间局部性的读取请求会产生更多的读取I / O。因此,当磁盘I / O压力(尤其是IOPS)低于EBS限制时,用户可以减小块大小以获得更好的读取性能。
块大小对于平衡I / O吞吐量和IOPS也很有用。例如,在m5.4xlarge + io1配置中,EC2将I / O吞吐量限制为593 MiB / s,这可能不足以满足密集型工作负载。在这种情况下,用户可以减小块大小以降低读取吞吐量。但是,这是以更多读取I / O为代价的,可以通过预配置的IOPS来满足。根据经验,将块大小从64 KiB更改为4 KiB可使读取IOPS加倍,并使读取吞吐量减半。
由于块大小决定了磁盘文件的编码,因此在为应用程序确定最佳配置之前,应使用不同的设置进行几次测试运行。
[] ##数据块大小。 RocksDB基于块单位压缩数据。 ##与其他数据库中的页面相似,块是在块缓存中缓存的最小单位。请注意,##此处指定的块大小对应于未压缩的数据。 #块大小=“ 64KB” []#块大小=“ 64KB”
为了完成用户请求,内部执行者必须在特定的CPU和I / O操作中执行不同类型的工作。在具有更高I / O延迟的平台(如AWS Cloud)上,这些执行器将更多时间用于I / O操作,并且无法有效处理传入的请求。为了解决这个问题,TiKV团队正在开发一个新的异步框架,该框架将I / O操作与请求处理循环分开。在此功能投入生产之前,我们建议用户为关键组件的线程池设置更大的大小,以提高TiKV的整体处理效率。
线程池大小不足可能会导致客户端响应时间变慢。在TiKV FastTune Grafana面板下,用户可以监视不同线程池的等待时间并进行相应的调整。
[] ##调度程序的工作池大小,即写线程数。 ##应该少于CPU核心总数。当频繁进行写操作时,请将其设置为##更高的值。更具体地说,您可以运行“ top -H -p tikv-pid”来检查名为“ sched-worker-pool”的线程##是否繁忙。 #scheduler-worker-pool-size = 4 [] ##使用多少个线程来处理日志应用#apply-pool-size = 2 ##使用多少个线程来处理筏消息#store-pool-size = 2
通过一系列深入的调查,我们展示了在AWS云上运行TiDB的最佳实践。通过遵循这些实践,您将能够以合理的成本获得性能更高的TiDB集群。接下来,您可以阅读我们的教程和Aurora迁移指南,进行尝试。欢迎加入Slack,与我们分享您的经验并提出问题。