WARP:改进了Firefox 83中的JavaScript性能
默认情况下,我们在Firefox 83中启用了Warp,这是对SpiderMonkey的一个重大更新。SpiderMonkey是Firefox Web浏览器中使用的JavaScript引擎。
通过Warp(也称为WarpBuilder),我们对JIT(Just-in-Time)编译器进行了重大改变,从而提高了响应速度,加快了页面加载速度,提高了内存使用率。新的架构也更易于维护,并开启了对SpiderMonkey的额外改进。
运行JavaScript的第一步是将源代码解析为字节码,这是一种较低级别的表示。字节码可以使用解释器立即执行,也可以由实时(JIT)编译器编译成本机代码。现代的JavaScript引擎有多层执行引擎。
解释器和基线JIT的编译速度很快,只执行基本的代码优化(通常基于内联缓存),并收集性能分析数据。
优化JIT执行高级的编译器优化,但编译时间较慢且使用更多内存,因此仅用于热(多次调用)函数。
优化JIT根据其他层收集的性能分析数据进行假设。如果这些假设被证明是错误的,那么优化后的代码将被丢弃。当发生这种情况时,该函数将在基准层中恢复执行,并且必须再次预热(这称为紧急情况)。
我们之前的JIT优化Ion使用了两个截然不同的系统来收集性能分析信息来指导JIT优化。第一种是类型推断(TI),它收集有关JS代码中使用的对象类型的全局信息。第二种是CacheIR,这是一种简单的线性字节码格式,由基线解释器和基线JIT用作基本的优化原语。ION主要依靠TI,但在TI数据不可用时,偶尔也会使用CacheIR信息。
使用Warp,我们已将优化JIT更改为仅依赖基线层收集的CacheIR数据。这看起来是这样的:
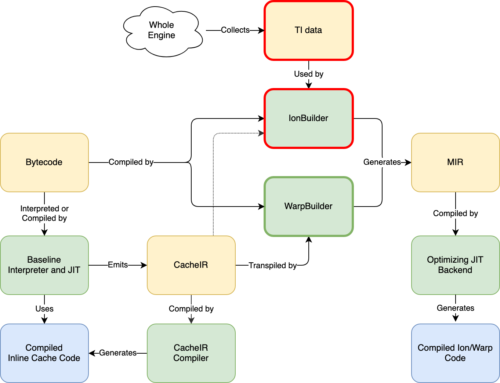
这里有很多信息,但需要注意的是,我们已经用更简单的WarpBuilder前端(用绿色标出)替换了IonBuilder前端(用红色标出)。IonBuilder和WarpBuilder都会生成Ion Mir,这是优化JIT后端使用的中间表示形式。
IonBuilder使用从整个引擎收集的TI数据来生成MIR,而WarpBuilder使用基线解释器和基线JIT用来生成内联缓存(IC)的相同CacheIR来生成MIR。正如我们将在下面看到的,Warp和较低层之间更紧密的集成有几个优点。
基线解释器和基线JIT对此函数使用两个内联缓存:一个用于属性访问(o.x),另一个用于减法。这是因为在不知道o和o.x的类型的情况下,我们无法优化该函数。
将使用o值调用属性访问IC o.x。然后,它可以附加一个IC存根(一小段机器代码)来优化此操作。在SpiderMonkey中,这是通过首先生成CacheIR(一种简单的线性字节码格式,您可以将其视为优化配方)来实现的。例如,如果o是一个对象,而x是一个简单的数据属性,我们将生成以下代码:
在这里,我们首先保护输入(O)是一个对象,然后保护对象的形状(它决定对象的属性和布局),然后从对象的槽加载o.x的值。
请注意,插槽数组中的形状和属性索引存储在单独的数据部分中,而不是烘焙到CacheIR或IC代码本身。CacheIR用shapeOffset和OffsetOffset表示这些字段的偏移量。这允许许多不同的IC存根共享相同的生成代码,从而减少编译开销。
然后,IC将此CacheIR片段编译为机器码。现在,基线解释器和基线JIT可以快速执行此操作,而无需调用C++代码。
减法IC的工作原理与此相同。如果o.x是int32值,则将使用两个int32值调用减法IC,并且IC将生成以下CacheIR以优化该情况:
这意味着我们首先保护左侧是int32值,然后保护右侧是int32值,然后我们可以执行int32减法,并将IC存根的结果返回给函数。
CacheIR指令捕获了我们优化操作所需的所有操作。我们有几百条CacheIR指令,定义在一个YAML文件中。这些是我们的JIT优化管道的构建块。
如果一个JS函数被多次调用,我们希望使用优化编译器对其进行编译。使用扭曲有三个步骤:
WarpOracle:在主线程上运行,创建包含基准CacheIR数据的快照。
WarpOracle阶段在主线程上运行,速度非常快。实际的和平号构建可以在后台线程上完成。这是对IonBuilder的改进,在IonBuilder中,我们必须在主线程上构建MIR,因为它依赖于许多全局数据结构来进行类型推断。
WarpBuilder有一个转换器,可以将CacheIR转换为MIR。这是一个非常机械的过程:对于每条CacheIR指令,它只生成相应的MIR指令。
把这些放在一起,我们会得到下面的图片(点击查看更大的版本):我们对这个设计非常兴奋:当我们更改CacheIR指令时,它会自动影响我们的所有JIT层(参见上图中的蓝色箭头)。WARP只是将函数的字节码和CacheIR指令编织到一个MIR图中。
我们的旧MIR构建器(IonBuilder)有很多我们在WarpBuilder中不需要的复杂代码,因为所有的JS语义都被我们也需要用于IC的CacheIR数据捕获了。
优化的JavaScript JIT能够将JavaScript函数内联到调用方。有了Warp,我们就更进一步了:Warp还能够根据调用点专门化内联函数。
此函数可以从多个位置调用,每个位置都传递不同形状的对象或o.x的不同类型。在这种情况下,内联缓存将具有多态CacheIR IC存根,即使每个调用方只传递一个类型。如果我们在Warp中内联函数,我们将不能像我们想要的那样优化它。
为了解决这个问题,我们引入了一种名为试验内联的新优化方法。每个函数都有一个ICScript,用于存储该函数的CacheIR和IC数据。在我们对一个函数进行扭曲编译之前,我们会扫描该函数中的基线IC,以搜索对可内联函数的调用。对于每个可链接的调用点,我们为被调用者函数创建一个新的ICScript。每当我们调用内联候选对象时,我们都会传入新的专用ICScript,而不是使用被调用者的默认ICScript。这意味着Baseline解释器、Baseline JIT和Warp现在将收集和使用该调用点的专用信息。
试用内联非常强大,因为它是递归工作的。例如,考虑以下JS代码:
函数call WithArg(Fun,x){Return Fun(X);}函数测试(A){var b=callWithArg(x=>;x+1,a);var c=callWithArg(x=>;x-1,a);return b+c;}。
当我们执行测试函数的内联试验时,我们将为每个callWithArg调用生成一个专门的ICScript。稍后,我们尝试在这些调用方专用的callWithArg函数中进行递归尝试内联,然后我们可以根据调用方来专门化有趣的调用。这在IonBuilder中是不可能的。
当需要对测试函数进行Warp编译时,我们拥有调用者专用的CacheIR数据,可以生成最佳代码。
这意味着我们在对函数进行WARP编译之前,通过(递归地)专门化调用点的基准IC数据来构建内联图。然后,Warp只需在此基础上进行内联,而不需要自己的内联启发式算法。
IonBuilder能够直接内联某些内置函数。这对于像Math.abs和Array.Prototype.ush这样的东西特别有用,因为我们可以用几条机器指令来实现它们,而且这比调用函数要快得多。
因为Warp是由CacheIR驱动的,所以我们决定为调用这些函数生成优化的CacheIR。
这意味着在我们的基准解释器和JIT中,这些内置的代码现在也通过IC存根进行了适当的优化。新的设计使我们能够生成正确的CacheIR指令,这不仅使Warp受益,而且使我们所有的JIT层都受益。
例如,让我们看看一个带有两个int32参数的Math.pow调用。我们生成以下CacheIR:
LoadArgumentFixedSlot ResultId 1,SlotIndex 3GuardToObject inputId 1GuardSpecificFunction funId 1,ExptedOffset 0,nargsAndFlagsOffset 8LoadArgumentFixedSlot ResultId 2,slotIndex 1LoadArgumentFixedSlot ResultId 3,slotIndex 0GuardToInt32 inputId 2GuardToInt32 inputId。
首先,我们确保被调用方是内置的POW函数。然后我们加载这两个参数,并保护它们为int32值。然后,我们执行专用于两个int32参数的幂运算,并从IC存根返回结果。
此外,Int32PowResult CacheIR指令还用于优化JS求幂运算符x**y。对于该运算符,我们可能会生成:
当我们为Int32PowResult添加Warp转换器支持时,Warp能够在没有额外更改的情况下优化求幂运算符和Math.power。这是CacheIR提供可用于优化不同操作的构建块的一个很好的例子。
在许多工作负载上,扭曲比离子更快。下面的图片显示了几个例子:我们的Google Docs加载时间提高了20%,速度计基准性能提高了大约10%-12%:
我们在Reddit和Netflix等其他JS密集型网站上看到了类似的页面加载和响应能力提升。《晚间新闻》用户的反馈也是积极的。
这些改进很大程度上是因为基于CacheIR的Warp允许我们在整个引擎中删除跟踪IonBuilder使用的全局类型推断数据所需的代码,从而提高整个引擎的速度。
旧系统需要所有功能来跟踪类型信息,而这些信息只在非常热门的功能中有用。有了Warp,用来优化Warp的概要信息(CacheIR)也被用来加速在基线解释器和基线JIT中运行的代码。
Warp还可以在线程外执行更多工作,需要重新编译的次数更少(以前的设计通常过于专门化,导致许多紧急情况)。
目前,在某些合成JS基准(如辛烷和克拉肯)上,WARP比Ion慢。这并不令人惊讶,因为Warp必须与近十年的优化工作竞争,并专门针对这些基准进行调整。
我们认为这些基准测试不能代表现代JS代码(另请参阅V8团队关于此的博客文章),其他地方的大幅加速和其他改进盖过了这些倒退。
这就是说,在接下来的几个月里,我们将继续优化Warp,我们希望在未来看到所有这些工作量的改善。
删除全局类型推理数据也意味着我们使用更少的内存。例如,下图显示了Firefox中的JS代码在加载多个网站时使用的内存减少了8%(Tp6):
我们预计,随着我们移除旧代码并能够简化更多的数据结构,这个数字在接下来的几个月里会有所改善。
类型推断数据还为垃圾回收增加了大量开销。9月23日,当我们在Firefox Nighly中默认启用Warp时,我们注意到GC扫描(GC的一个阶段)的遥测数据有了很大的改进:
因为WarpBuilder比IonBuilder机械化得多,所以我们发现代码更简单、更紧凑、更易维护,也更不容易出错。通过到处使用CacheIR,我们可以用更少的代码添加新的优化。这使得团队更容易提高性能和实现新功能。
我们用Warp取代了IonMonkey JIT的前端(和平号建造阶段)。下一步是删除旧的代码和架构。这很可能发生在Firefox 85中。我们预计这会带来额外的性能和内存使用改进。
我们还将继续逐步简化和优化IonMonkey JIT的后端。我们认为JS密集型工作负载还有很大的改进空间。
最后,因为我们所有的JIT现在都是基于CacheIR数据的,所以我们正在开发一个工具,让我们(和Web开发人员)为JS函数探索CacheIR数据。我们希望这能帮助开发者更好地理解JS的性能。
《变形金刚》的大部分工作是由卡罗琳·卡伦、伊恩·爱尔兰、简·德·穆伊以及我们令人惊叹的贡献者安德烈·巴尔古尔和汤姆·舒斯特完成的。SpiderMonkey团队的其他成员为我们提供了很多反馈和想法。克里斯蒂安·霍勒(Christian Holler)和加里·光(Gary Kwong
感谢Ted Campbell,Caroline Cullen,Steven DeTar,Matthew Gaudet,Melissa Thermidor,特别是Iain爱尔兰为这篇文章提供了很好的反馈和建议。