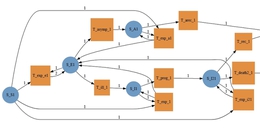
结构化并发

TL;DR:“结构化并发”指的是一种构建异步计算结构的方法,如此一来,子操作保证在父操作之前完成,就像函数保证在调用者之前完成一样。这听起来简单乏味,但在C++中却并非如此。结构化并发--最引人注目的是C++20协程--对异步架构的正确性和简单性有着深远的影响。它为我们的异步程序带来了现代C++风格,使异步生命周期与普通的C++词法作用域相对应,不再需要引用计数来管理对象生命周期。
早在20世纪50年代,新生的计算机业就发现了结构化编程:具有词法作用域、控制结构和子例程的高级编程语言产生的程序比使用测试跳转指令和GOTO的汇编级编程更易于阅读、编写和维护。这一进步是一个巨大的飞跃,以至于没有人再谈论结构化编程;它只是一种“编程”。
与任何其他语言相比,C++更充分地利用了结构化编程。对象生存期的语义反映了作用域的严格嵌套,也就是代码的结构。函数激活嵌套、作用域嵌套和对象生存期嵌套。对象的生命周期以作用域的右大括号结束,并且对象以与其构造相反的顺序被销毁,以保持严格的嵌套。
现代C++编程风格就是建立在这种结构化的基础上的。对象具有值语义-它们的行为类似于int-并且资源在析构函数中被确定性地清理,这从结构上保证了资源在其生命周期结束后不会被使用。这是非常重要的。
当我们放弃这种严格的作用域和生存期嵌套时-例如,当我们引用堆上的对象计数时,或者当我们使用单例模式时-我们是在与语言的优势抗争,而不是与它们合作。
在并发性存在的情况下编写正确的程序要比在单线程代码中困难得多。造成这种情况的原因有很多。原因之一是线程,就像单例和动态分配的对象一样,嘲笑你的微不足道的嵌套作用域。虽然您可以在线程中使用现代C++风格,但当逻辑和生命周期分散在线程之间时,程序的层次结构就会丢失。我们用来管理单线程代码复杂性的工具--特别是绑定到嵌套作用域的嵌套生命周期--根本不能转换为异步代码。
为了理解我的意思,让我们看看当我们采用一个简单的同步函数并将其设为异步函数时会发生什么。
Dothing()非常简单。它声明一些本地州,调用帮助器,然后返回一些结果。现在想象一下,我们想要使这两个函数同步,可能是因为它们花费的时间太长。没问题,让我们使用Boost Futures,它支持延续链接:
Boost::Future<;void>;ComputeResult(State&;s);Boost::Future<;int>;dothing(){State s;Auto Fut=ComputeResult(S);Return Fut.Then([&;](AUTO&;&;){return s.Result;});//oops}。
如果你以前用期货编程,你可能会尖叫,“不!”最后一行上的.Then()将一些工作排入队列,以便在culteResult()完成后运行。Dothing()然后返回结果的未来。问题是,当dothing()返回时,State对象的生命周期结束,而Continue仍在引用它。这现在是一个悬而未决的参考,很可能会导致崩盘。
哪里出了问题?期货让我们可以计算出目前还不能得到的结果,Boost风格让我们可以链接延续。但Continue是一个单独的函数,具有单独的作用域。我们经常需要在这些独立的作用域之间共享数据。不再有整洁的嵌套作用域,不再有嵌套的生存期。我们必须手动管理状态的生命周期,如下所示:
Boost::future<;void>;computeResult(shared_ptr<;State>;s);//addref//状态Boost::Future<;int>;dothing(){AUTO s=std::Make_Shared<;State>;();AUTO FUT=ComputeResult;Return Fut.Then([s](AUTO&;&;){Return s.Result;});//addref//状态}。
由于这两个异步操作都涉及状态,因此它们都需要分担责任来保持状态。
思考这个问题的另一种方式是:这种异步计算的生命周期是多少?它在调用dothing()时开始,但直到延续(传递给Future的lambda)返回时才结束。没有与该生命周期相对应的词汇作用域。这就是我们悲哀的根源。
当我们考虑遗嘱执行者时,故事就变得更加复杂了。Executor是执行上下文的句柄,它允许您在线程或线程池上调度工作。许多代码库都有一些执行者的概念,有些代码库允许您用延迟或其他策略来安排事情。这让我们可以做一些很酷的事情,比如将计算从IO线程池转移到CPU线程池,或者延迟重试异步操作。很方便,但就像Goto一样,它是一个非常低级的控制结构,容易混淆而不是澄清。
例如,我最近遇到了一种算法,它使用执行器和回调(这里称为侦听器)来重试某些资源的异步分配。下面是一个大大删节的版本。这是在休息后描述的。
//这是一个在//异步操作完成时调用的延续:struct Manager::Listener:ListenerInterface{Shared_PTR<;Manager>;Manager_;Executor Executor_;Size_t RetriesCount_;void onSuccemon()Override{/*...yay,分配成功...。*/}void onFailed()Override{//当分配失败时,向执行器发送重试//并延迟自动分配=[MANAGER=MANAGER_](){MANAGER-&>;ALLOCATE();};//在将来的某个时候运行:EXECUTOR_.EXECUTE_AFTER(ALLOC,10ms*(1<;<;RetriesCount_));}};//尝试异步分配某些资源//将上面的类作为Continuationvoid Manager::Allocate(){//我们是否已经尝试了太多次?If(RetriesCount_>;kMaxRetries){/*...通知任何观察者我们失败了*/return;}//重试:++RetriesCount_;allocator_.doAllocate(make_Shared<;Listener>;(Shared_From_This(),Executor_,RetriesCount_));}(Made_Shared<;Listener>;(Shared_From_This(),Executor_,RetriesCount_))。
ALLOCATE()成员函数首先检查操作是否已经重试了太多次。如果不是,它调用帮助器doAllocate()函数,传递一个回调来通知成功或失败。失败时,处理程序将延迟的工作提交给Executor,后者将回调Alalate(),从而延迟地重试分配。
这是一种高度有状态且相当迂回的异步算法。逻辑跨越多个功能和多个对象,控制和数据流不明显。请注意,保持物品存活所必需的复杂的参考计数舞蹈。将工作发布给遗嘱执行人会让这件事变得更加困难。这段代码中的执行器没有延续的概念,因此在任务执行期间发生的错误无处可去。如果ALLOCATE()函数希望程序的任何部分能够从错误中恢复,则它不能通过抛出异常来发出错误信号。错误处理必须手动和带外完成。如果我们想要支持取消,情况也是如此。
这是非结构化并发:我们以特别的方式将异步操作排队;我们链接依赖的工作,使用延续或“串”执行器来强制顺序一致性;我们使用强引用计数和弱引用计数来保持数据存活,直到我们确定不再需要它为止。没有任务A是任务B的子任务的正式概念,也没有办法强制该子任务在其父任务之前完成,并且代码中没有一个地方可以让我们指向并说,“这就是算法。”
如果您不介意这个类比,通过执行器的跳跃有点像在时间和空间上都是非本地的goto语句:“跳到程序中的这一点,从现在起X毫秒,在这个特定的线程上。”
这种非局部的不连续性使得人们很难对正确性和效率进行推理。将非结构化并发扩展到处理大量并发实时事件的整个程序,手动处理带外异步控制和数据流、控制对共享状态的并发访问以及管理对象生存期的附带复杂性变得难以承受。
回想一下,在计算的早期,非结构化编程风格迅速让位于结构化风格。随着C++中增加了协同程序,我们看到今天的异步代码也发生了类似的相移。如果我们根据协程(使用Lewis Baker流行的cppcoro库)重写上述重试算法,它可能如下所示:
//尝试异步分配某些资源//WITH RETRY:cppcoro::TASK<;>;Manager::ALLOCATE(){//重试最多kMaxRetries//次:For(int riresesCount=1;riresesCount<;=kMaxRetries;++RetriesCount){try{co_await allocator_.doAllocate();co_return;//Success!}Catch(...){}//O。释放线程以获取//位,然后重试:co_aWait Scheduler_.Schedule_After(10ms*(1<;<;RetriesCount));}//错误,重试次数太多,抛出std::run_error(";资源分配重试计数已超出。";);}
旁白:这用实现cppcoro的DelayedScheduler概念的Scheduler_替换了Executor_。
可以在局部变量中维护状态(就像RetriesCount一样),而不是作为需要引用计数的对象的成员。
从结构上保证,在此函数继续执行之前,将完成对allocator_.doAllocate()的异步调用。
第(4)点影响深远。考虑一下本文开头的这个微不足道的例子。以下在协程方面的重新实现是完全安全的:
上面的代码是安全的,因为我们知道ComputeResult在恢复执行之前完成,因此在s被销毁之前完成。
使用结构化并发,通过引用立即等待的子任务来传递局部变量是完全安全的。
采用结构化的并发方法(其中并发操作的生存期严格嵌套在它使用的资源的生存期内,并与程序作用域绑定)允许我们避免使用诸如SHARED_PTR之类的垃圾收集技术来管理生存期。这可以产生更高效的代码,需要更少的堆分配和原子引用计数操作,以及更容易推理和不容易出错的代码。然而,这种方法的一个含义是,它意味着在父操作可以完成之前,我们必须始终联接并等待子操作。我们不能再简单地从那些子操作中分离出来,让资源在引用计数降至零时自动清理。为了避免不必要的长时间等待其结果不再需要的子操作,我们需要一种能够取消这些子操作的机制,以便它们能够快速完成。因此,结构化并发模型需要对取消提供深度支持,以避免引入不必要的延迟。
请注意,每次通过引用将局部变量传递给子协程时,我们都依赖结构化生存期和结构化并发性。我们必须确保子协程在父协程退出该局部变量的作用域并销毁它之前已经完成并且不再使用该对象。
当我谈到“结构化并发”时,我说的不仅仅是协程--尽管这是它最明显的表现。为了理解我的意思,让我们简要地讨论一下什么是协程,什么不是协程。特别是,C++协程根本没有本质上的并发性!它们实际上只是让编译器将您的函数分割为回调函数的一种方式。
在这里等待是什么意思?老生常谈的答案是:无论cppcoro::task<;>;的作者希望它是什么意思(在一定范围内),它都意味着什么。更完整的答案是,co_await挂起当前的协程,捆绑协程的其余部分(这里是语句co_return s.result;),并将其传递给可等待的对象(这里是culteResult(S)返回的任务<;>;)。该可等待对象通常会将其存储在某个位置,以便以后子任务完成时可以调用它。例如,cppcoro::Task<;>;就是这样做的。
换句话说,任务类型和协程语言特性共同作用,在无聊的回调之上加了一层“结构化并发”。就这样。这就是魔力。这一切都只是回调,但回调是一种非常特殊的模式,正是这种模式使这种“结构化”。该模式确保子操作在父操作之前完成,而该属性才是带来好处的因素。
一旦我们认识到结构化并发实际上只是特定模式中的回调,我们就会意识到我们可以在没有协程的情况下实现结构化并发。当然,使用回调进行编程并不是什么新鲜事,并且可以将模式编码到库中并使其可重用。这就是libunifex所做的。如果您遵循C++标准化,这也是执行者提案中的发送者/接收者抽象所做的事情。
使用libunifex作为结构化并发的基础,我们可以编写以下示例:
Unifex::any_sender_of<;>;ComputeResult(State&;s);auto dothing(){return unifex::let_with(//声明类型为State:[]{return State{};}的局部变量),//使用本地构造一个异步任务:[](State&;s){return unifex::Transform(ComputeResult),[&;]{。
当我们有协同程序的时候为什么会有人这么写呢?你当然需要一个很好的理由,但我能想到几个。使用协程,在第一次调用协程时有一个分配,每次恢复时都有一个间接函数调用。编译器有时可以消除这种开销,但有时不能。通过直接使用回调(但采用结构化并发模式),我们可以在不进行权衡的情况下获得协程的许多好处。
然而,这种编程风格做出了不同的取舍:它比同等的协程程序更难写和读。我认为未来90%的异步代码应该仅仅是为了可维护性而使用协程。对于热代码,有选择地用较低级别的等价物替换协程,并让基准作为您的指南。
我在上面提到过,协程本身并不是并发的;它们只是编写回调的一种方式。协程本质上是顺序的,而任务<;>;类型的懒惰--协程开始挂起,等待之后才开始执行--意味着我们不能用它来在程序中引入并发性。现有的基于未来的代码通常假定操作已经急切地开始,从而引入了临时并发,您需要小心地将其删减。这迫使您以特别的方式一遍又一遍地重新实现并发模式。
通过结构化并发,我们将并发模式编码为可重用的算法,以结构化的方式引入并发。例如,如果我们有一系列任务,并且希望等到它们全部完成并以元组形式返回结果,我们会将它们全部传递给cppcoro::When_all并等待结果。(Libunifex也有WHEN_ALL算法。)。
目前,cppcoro和libunifex都没有WHEN_ANY算法,因此不能启动多个并发操作并在第一个操作完成时返回。不过,这是一个非常重要和有趣的基础算法。为了保持结构化并发的保证,当第一个子任务完成时,When_any应该请求取消所有其他任务,然后等待它们全部完成。该算法的效用取决于程序中的所有异步操作是否能迅速响应取消请求,这表明在现代异步程序中,对取消的深度支持是多么重要。
到目前为止,我已经讨论了什么是结构化并发以及它为什么重要。我还没有讨论我们是如何做到这一点的。如果您已经在使用协程来编写异步C++,那么恭喜您。您可能会继续享受结构化并发的好处,也许会对协程为什么如此具有变革性有更深入的理解和欣赏。
对于缺乏结构化并发性、缺乏对取消的深度支持,甚至缺乏对异步的抽象的代码库来说,这项工作非常困难。它甚至可以从引入复杂性开始,以便开辟出一个孤岛,在该孤岛中,周围的代码提供结构化并发模式所需的保证。例如,这包括给人一种即时取消预定工作的印象,即使底层执行上下文不直接提供这一功能。增加的复杂性可以隔离在一个层中,并且可以在上面构建结构化并发孤岛。然后可以开始简化工作,获取未来或回调样式的代码并将其转换为协程,梳理出父/子关系、所有权和生命周期。
添加co_aWait会使同步函数成为异步函数,而不会干扰计算结构。与普通函数调用一样,等待的异步操作必须在调用函数完成之前完成。这场革命是:什么都不会改变。作用域和生命周期仍然像往常一样嵌套,只是现在作用域在时间上是不连续的。有了原始的回调和期货,这种结构就会消失。
协程,以及更一般的结构化并发,将现代C++风格的优势--值语义、算法驱动的设计、具有确定性终结的清晰所有权语义--带入我们的异步编程中。它之所以这样做,是因为它将异步生命周期与普通的C++词法作用域联系在一起。协程将我们的异步函数划分为挂起点处的回调,这些回调以一种非常特定的模式被调用,以维护作用域、生存期和函数激活的严格嵌套。
我们在代码中散布了co_await,并且继续使用我们熟悉的所有习惯用法:错误处理的异常、局部变量中的状态、释放资源的析构函数、通过值或引用传递的参数,以及所有其他良好、安全和惯用的现代C++的特征。
如果您想更多地了解C++中的结构化并发,请务必查看Lewis Baker的CppCon Talk from 2019关于它的文章。