自PostgreSQL 8.3以来的TPC-H性能
在本博客系列的第一部分中,我展示了两个基准测试结果,展示了PostgreSQL OLTP自2008年发布的8.3以来的性能变化。在这一部分中,我计划做同样的事情,但对于分析/BI查询,处理大量数据。
测试此工作负载有许多行业基准,但最常用的可能是TPC-H,因此我将在这篇博客文章中使用TPC-H。还有TPC-DS,另一个用于测试决策支持系统的TPC基准,它可以被视为TPC-H的演变或替代。出于几个原因,我决定坚持使用TPC-H。
首先,TPC-DS在模式(更多的表)和查询数量(22对99)方面都要复杂得多。正确地调优这一点会困难得多,尤其是在处理多个PostgreSQL版本时。其次,一些TPC-DS查询使用较早的PostgreSQL版本不支持的功能(例如分组集),使得这些查询与某些版本无关。最后,我想说,与TPC-DS相比,人们对TPC-H更加熟悉。
这样做的目的不是为了与其他数据库产品进行比较,而是提供一个合理的长期特征,说明PostgreSQL自PostgreSQL8.3以来的性能是如何演变的。
注:要对TPC-H基准进行非常有趣的分析,我强烈推荐Boncz、Neumann和Erling的“TPC-H分析:隐藏的信息和从有影响力的基准中吸取的教训”的论文。
这篇博客文章中的大部分结果来自我办公室里的“更大的盒子”,它有以下参数:
我相信你能买到更强壮的机器,但我相信这足以给我们提供相关数据。有两种配置变体-一种禁用了并行度,另一种启用了并行度。在这两种情况下,大多数参数值都是相同的,并根据可用的硬件资源(CPU、RAM、存储)进行调整。您可以在本帖子的末尾找到有关配置的更详细信息。
我想非常清楚地说明,我的目标不是实现一个可以通过TPC要求的所有标准的有效TPC-H基准。我的目标是评估不同分析查询的性能是如何随时间变化的,而不是追求某种抽象的性能度量单位或类似的东西。
因此,我决定只使用TPC-H的一个子集-本质上只是加载数据,然后运行22个查询(所有版本上的参数都相同)。没有数据刷新,数据集在初始加载后是静态的。我选择了一些比例因子,1、10和75,这样我们就可以得到适合共享缓冲区的结果(1)、适合内存的结果(10)和大于内存的结果(75)。我会选择100来使其成为一个“好的序列”,这在某些情况下不适合280 GB的存储(这要归功于索引、临时文件等)。请注意,TPC-H甚至不会将比例因子75识别为有效的比例因子。
但是,对1 GB或10 GB数据集进行基准测试有意义吗?人们倾向于关注更大的数据库,所以费心去测试这些数据库似乎有点愚蠢。但我不认为这是有用的--根据我的经验,野外的绝大多数数据库都相当小,即使整个数据库很大,人们通常也只处理其中的一小部分-最近的数据、未解决的订单等。所以我认为,即使使用这些小的数据集进行测试也是有意义的。
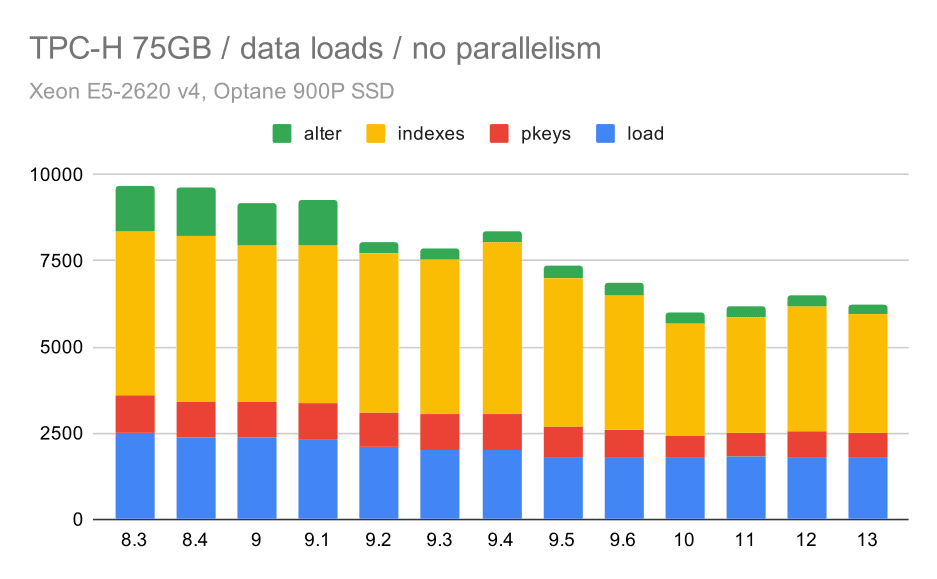
首先,让我们看看将数据加载到数据库中需要多长时间-没有并行和有并行。我将只显示75 GB数据集的结果,因为对于较小的情况,总体行为几乎相同。
您可以清楚地看到改进的趋势是稳定的,仅通过提高所有四个步骤(复制、创建主键和索引,以及(特别是)设置外键)的效率,就可以减少大约30%的持续时间。9.2中的“Alter”改进尤为明显。
现在,让我们看看启用并行性是如何改变行为的。下图将启用并行度(标记为“(P)”)的结果与禁用并行度的结果进行比较。
不幸的是,在这个测试中,并行性的效果似乎非常有限-它确实有一点帮助,但差异相当小。所以总体改善幅度保持在30%左右。
现在我们可以看一下查询。TPC-H有22个查询模板-我已经生成了一组实际查询,并在所有版本上运行了它们两次-第一次是在删除所有缓存并重启实例之后,然后是使用预热的缓存。图表中显示的所有数字都是这两次运行中最好的(当然,在大多数情况下,这是第二次运行)。
在没有并行性的情况下,在最小的数据集上的结果非常清楚-对于22个查询中的每个查询,每个条形图都被分成多个部分,具有不同的颜色。很难说哪个部分映射到哪个确切的查询,但当一个查询在两次运行之间改善或变得更差时,它足以识别情况。例如,在第一张图表中,很明显,Q21在8.3到8.4之间的速度要快得多。
对于10 GB的规模,结果有点难以解释,因为在8.3上,有一个查询(Q21)执行起来花费了太多时间,使其他所有查询都相形见绌。
好的,这样就更容易读了。我们可以清楚地看到,大多数查询(直到Q17)都变得更快了,但随后有两个查询(Q18和Q20)变得稍微慢了一些。我们将在最大的数据集上看到类似的问题,所以我将讨论可能的根本原因。
同样,我们看到9.3中的一个查询突然增加-这一次是第二季度,如果没有它,图表看起来如下所示:
总的来说,这是一个相当不错的改进,仅通过使计划器和优化器更智能,以及通过使执行器更高效(请记住,在这些运行中禁用了并行性),就可以将整个执行速度从大约2.7小时加快到大约1.2小时。
那么,第二季度会有什么问题,让它在9.3中变得更慢呢?简单的答案是,每次您使计划器和优化器变得更智能-无论是通过构建新类型的路径/计划,还是通过使其依赖于某些统计数据,也意味着当统计数据或估计出错时,可能会出现新的错误。在第二季度中,WHERE子句引用聚合子查询-该查询的简化版本可能如下所示:
从部分补给中选择1,其中ps_Supplyost=(补给成本)从补给中选择补给,最小补给(Ps_Supplyost):补给,从补给中选择,补给中选择。*区域*及s_suppkey=s_suppkey*及r_name=';及n_regionkey=r_regionkey=r_regionkey*及r_name=#39;美国(美国);
问题是我们不知道计划时的平均值,因此不可能为WHERE条件计算足够好的估计值。实际的Q2包含额外的联接,而计划这些联接从根本上取决于对联接关系的良好估计。在旧版本中,优化器似乎一直在做正确的事情,但在9.3中,我们在某种程度上使其更智能,但由于估计不佳,它无法做出正确的决策。换句话说,由于计划者的限制,旧版本中的好计划只是运气而已。
我敢打赌,Q18和Q20在较小数据集上的回归也是由类似的原因造成的,尽管我没有详细调查这些原因。
我相信其中一些优化器问题可以通过调优成本参数(例如,RANDOM_PAGE_COST等)来解决。但由于时间限制,我还没有试过。但是,它确实表明升级不会自动改进所有查询-有时升级可能会触发回归,因此对应用程序进行适当的测试是一个好主意。
那么,让我们看看查询并行性在多大程度上改变了结果。同样,我们将只查看9.6版本的结果,因为在启用并行查询的情况下,使用“(P)”标记结果。
显然,并行性有相当大的帮助-即使在这个很小的数据集上,它也减少了大约30%。在中等数据集上,常规运行和并行运行没有太大区别:
这是已经讨论过的问题的又一例证-启用并行性允许考虑额外的查询计划,而且很明显,估计或成本计算与实际不符,导致糟糕的计划选择。
在这里,启用并行性是我们的优势-优化器设法为第二季度构建了一个更便宜的并行计划,覆盖了9.3中引入的糟糕的计划选择。但为了完整起见,以下是不含Q2的结果。
即使在这里,您也可以发现一些糟糕的并行计划选择-例如,Q9的并行计划在11之前更差,而11的并行计划变得更快-这可能要归功于11支持额外的并行执行器节点。另一方面,一些并行查询(Q18、Q20)在第11天会变慢,因此不仅仅是彩虹和独角兽。
我认为这些结果很好地说明了从PostgreSQL8.3开始实现的优化。禁用并行性的测试表明效率提高了(即使用相同数量的资源做更多事情)-数据加载速度提高了约30%,查询速度提高了约2倍。我确实遇到了一些低效查询计划的问题,但这是使查询规划器变得更智能时的固有风险。我们一直在努力使结果更可靠,我确信我可以通过稍微调优配置来缓解这些问题中的大多数。
在启用并行性的情况下,结果表明我们可以有效地利用额外的资源(特别是CPU内核)。数据加载似乎并没有从中获益很多-至少在这个基准测试中没有,但是对查询执行的影响是显著的,导致大约2倍的加速(当然,不同的查询受到不同的影响)。
在未来的PostgreSQL版本中有很多机会来改进这一点。例如,有一个补丁系列实现了复制的并行性,从而加快了数据加载速度。有各种补丁可以改进分析查询的执行-从小的本地化优化到列存储和执行、聚合下推等大项目。使用声明性分区也可以获得很多好处-这是我在进行此基准测试时几乎忽略的一个特性,原因很简单,因为它会以太大的方式扩大范围。我相信还有很多其他的机会是我无法想象的,但是PostgreSQL社区中更聪明的人已经在努力了。
Shared_Buffers=4GBwork_mem=128MB VACKUP_COST_LIMIT=1000max_WAL_SIZE=24GB CHECKPOINT_TIMEOUT=30min CHECKPOINT_COMPLETION_TARGET=0.9#LOGGING LOG_CHECKPOINTS=onlog_CONNECTIONS=onlog_DISCONSIONS=onlog_line_prefix=';%t%c:%l%x/%v';log_lock_waits=onlog_temp_files=1024#并行查询max_Parallel_Worker_Per_Gather=0max_Parallel_Maintenance_Worker=0#Optimizerdefault_Statistics_target=1000随机_PAGE_COST=60有效缓存大小=32 GB。
Shared_Buffers=4GBwork_mem=128MB Vacuum_Cost_Limit=1000max_WAL_SIZE=24GB CHECKPOINT_TIMEOUT=30min CHECKPOINT_COMPLETION_TARGET=0.9#LOGGING LOG_CHECKPOINTS=onlog_CONNECTIONS=onlog_DISCONNECTIONS=onlog_line_prefix=';%t%c:%l%x/%v';LOG_LOCK_WAITS=onlog_temp_files=1024#并行查询max_Parallel_Worker_Per_Gather=16max_Parallel_Maintenance_Worker=16max_Worker_Processing=32max_Parallel_Worker=32#优化器DEFAULT_STATISTICS_TARGET=1000 RANDOM_PAGE_COST=60Effect_CACHE_SIZE=32 GB



