NLP的深度学习:斯坦福课程(免费讲座笔记)
但是您也可以为每个单词设置Sigmoid(WiUj),为每个在窗口中嵌入Uj的上下文设置+Sigmoid(-WiUk),然后为随机选择的k设置+Sigmoid(-WiUk)。在某种程度上,类似于波尔兹曼机器的遗忘。
超参数魔术:在d=300时表现平台期(但不会崩溃,即使在10k!!-nips,2018-)。似乎和PCA有关。
还有一件事:数据质量非常重要。使用“小”维基百科数据集的模型比使用大新闻抓取数据集的模型性能更好。
评估单词嵌入:您可以评估类比(使用语义或句法类比,在预制数据集上具有准确性),或者余弦距离/相似度与心理驱动的机械土耳其语相似度。
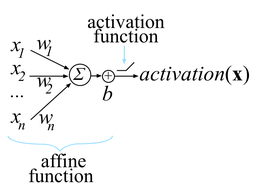
使用之前固定的k个单词进行预测。例如使用马尔可夫链或共现矩阵。您可以使用单词的一次性编码(超级稀疏向量作为输入-实际上在任何正常的实现中作为索引传递)来训练完全连接的MLP。
语义相似的单词应该会产生类似的“Next Word”分布,但是普通的窗口模型不会利用这一点!让我们在混合中添加一些嵌入内容。
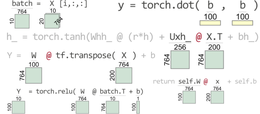
训练RNN。这意味着将数据集分成多个序列(通常是来自语料库的句子、段落或整个文本)。对于每个序列,您用零(或合理的先验)初始化隐藏状态h。你把每个第i个单词按顺序排列,得到它的嵌入,把它和h连接起来,让它通过仿射层,加上偏置,然后用它来预测第i+1个单词(通过典型的仿射+Softmax层)。对批中的每个单词执行此操作后,您将为每个单词反向传播生成的概率的二进制交叉熵损失,从而为隐藏状态和嵌入获得更好的W矩阵(您也可以训练H0。如果您的语料库足够大,您还可以训练嵌入)。
定义为语料库的概率的倒数,由^1/N标准化。另一种看待它的方法是:取您的模型给予每个t+1个单词的倒数概率的几何平均值,给定它们的前一个t。GPT-3得到大约20作为困惑值(因此平均概率大约是0.05。不错)。
第t个单词的梯度是前t-1个单词的梯度的乘积,这意味着如果Jacobian的范数是<;1,那么它在字数上将是指数小的,而对于Jacobian>;1则会发生相反的情况。这意味着一个单词在将来只有几个空格,不会在过去的决策中产生足够大的影响。我们用剪裁梯度解决爆炸梯度:如果梯度范数>;e,则将其缩小到e范数,对于e是一个超参数。
为了解决渐变问题,发明了两种体系结构:LSTM和GRU,它只是一个流线型的LSTM(门更少,收敛速度更快,参数更少)。它们的性能通常相似,或者LSTM稍好一些,因为它有更多的参数。
除了隐藏状态,LSTMLSTM还具有单元状态,它们将信息保存在单元状态中,并决定将哪些部分与隐藏状态一起传递。它们有忘记门、输入门和输出门,每个门都是输入(字t)和隐藏状态(t-1)串联的仿射变换的Sigmoid。使单元状态^为tanh(输入和隐藏状态t-1的另一个仿射变换)。然后,实际单元状态是输入门*那个单元状态+忘记门*最后一个单元状态。最后,将隐藏状态更新为OUTPUT_GATE*tanh(单元)。
GRU.它们的工作原理相似,但闸门较少。您只需在更新门乘以先前隐藏状态和1-输入仿射的更新门乘以隐藏状态t-1(乘以有点像遗忘门的RESET_GATE)之间的凸和,而不是输出门和单元的tanh。
您可以训练编码器RNN(使用常见的chirimbolos:Word Embedding,通常可以使用LSTM或GRU等)。然后训练一个不同的解码器RNN,该解码器的起始隐藏状态不是随机或0向量,而是源句中最后一个单词的隐藏状态,然后它必须生成目标句子中的所有单词。您可以在Softmax上使用交叉熵反向传播每个单词中的错误(使用与您用于大词汇表大小的单词嵌入相同的技巧)。
在前馈/测试阶段,您可以每次采样最可能的单词(贪婪方法)或采样前k个最可能的单词,然后继续扩展前k个最可能的单词序列,当您到达句末标记时总是停止。
由于对数似然率必然会随着单词的增加而降低,而且最有可能出现的句子只是空句,因此对于N个句子的词长,您可以按1/N对句子进行归一化,以获得归一化分数,而不会对长句子进行处罚。
但是,我们如何解决这样一个事实,即最后的隐藏状态可能不包含所有信息,特别是来自句子开头较远的单词的信息?
取内积的向量(每个都是标量),在上面做Softmax。你现在有了一个概率(注意力)分布。
取每个人获得的关注度加权的编码器隐藏状态的凸和。将它与解码器的隐藏状态连接起来,并在softmax之前将其用于仿射层。它还可以变得更一般:代替点积的凸和,可以在状态和中间的矩阵之间进行点积,或者用tanh和不同的向量进行疯狂的事情来进行注意力分配。
过去两年的许多NLP可以归结为“人们找到了很多巧妙的方式来利用注意力,这几乎与所有的进步相匹配。”
“在研究中,很多时候,你用一个简单的模型就能获得最好的性能,然后随着时间的推移,人们提出了更复杂的架构,他们的表现甚至更好,最终有人意识到,如果你对简单的模型的参数调整得恰到好处,你就可以再次击败他们。”[由我转述]。
在问答中,我们提供了一段和一个问题,模型需要选择回答问题的段落的子串。这意味着我们不能回答是或不是问题、计数问题等。
最大的数据集是由机械的Turk+精心挑选的相当简单的文本组成的。最有名的是班队。F1分数通常是报告的度量,在这里您寻找单词的精确度+FPR,而不是机械土耳其人的答案。
模型不善于注意到是否没有答案,直到研究人员提出了解决方案(要么使用一个阈值,要么得到一个“noAnswer”令牌来表示答案)。
在车队中,这个模型比传统的(非神经)NLP模型高出近30个F1积分。它输给了Bert&;c,但这有点简单。
连接两个终端状态(一个用于每个网络,因此一个用于反向的第一个字,一个用于正确的最后一个字)。
我们用注意力来找出答案在哪里。我们要做的是计算出每个单词的问题向量和段落状态之间的注意力得分,并用它来定义子字符串的开始和结束单词。
您可能会说我们缺少有关中间单词的信息,但实际上我们正在训练LSTM将该信息推到边缘(这是双向的,因此它是双向的)。